
This blog post is part of the Supercharging your large ClickHouse data loads series:
Introduction
Often, especially when migrating from another system to ClickHouse Cloud, a large amount of data must be initially loaded. Loading billions or trillions of rows from scratch can be challenging, as such data loads take some time. The longer it takes, the higher the chances of transient issues like network glitches potentially interrupting and stopping the data load. We will show how to address these challenges and avoid interruptions to your data load.
In this third and last part of our three-part blog series about supercharging your large ClickHouse data loads, we will equip you with our best practices for resilient and efficient large data loads.
For this, we will briefly introduce you to a new managed solution for loading large data volumes from external systems into ClickHouse with built-in resiliency. We then look under the hood of a script originating from our magnificent support team helping some of our ClickHouse Cloud customers successfully migrate their datasets with trillions of rows. In the case that your external data source is not supported by our built-in managed solution yet, you can utilize this script in the meantime for loading a large dataset incrementally and reliably over a long period of time.
Resilient data loading
Loading billions or even trillions of rows from scratch from an external system into a ClickHouse table takes some time. For example, assuming an (arbitrarily) basic transfer throughput of 10 million rows per second, 36 billion rows can be loaded per hour and 864 billion rows per day. Loading a few trillion rows would require multiple days.
This is enough time for things to go temporarily wrong - for example, there could be a transient network connection issue, causing the data load to be interrupted and fail. Without a managed solution using a stateful orchestration of the data transfer with built-in resiliency and automatic retries, users often resort to truncating the ClickHouse target table and starting the whole data load from scratch again. This further increases the overall time it takes to load the data and, most importantly, could also fail again, leaving you unhappy. Alternatively, you can try to identify which data was successfully ingested into the ClickHouse target table and then try to load just the missing subset. This can be tricky without a unique sequence in your data and requires manual intervention and extra time.
ClickPipes
ClickPipes is a fully managed integration solution in ClickHouse Cloud providing built-in support for continuous, fast, resilient, and scalable data ingestion from an external system:
Having only GA’d this September, ClickPipes currently supports Apache Kafka in a number of flavors: OSS Apache Kafka, Confluent Cloud, and AWS MSK. Additional event pipelines and object stores (S3, GCS, etc.) will be supported soon, and, over time, direct integrations with other database systems.
Note that ClickPipes will automatically retry data transfers in the event of failures and currently offers at-least-once semantics. We also offer a Kafka Connect connector for users loading data from Kafka, who need exactly-once semantics.
ClickLoad
If your external data source is not supported by ClickPipes yet, or if you are not using ClickHouse Cloud, we recommend the approach sketched in this diagram:
 ① Export your data first into an object storage bucket (e.g. Amazon AWS S3, Google GCP Cloud Storage, or Microsoft Azure Blob Storage), ideally as moderately sized Parquet files between 50 and 150MB, but other formats work too. This recommendation is made for several reasons:
① Export your data first into an object storage bucket (e.g. Amazon AWS S3, Google GCP Cloud Storage, or Microsoft Azure Blob Storage), ideally as moderately sized Parquet files between 50 and 150MB, but other formats work too. This recommendation is made for several reasons:
-
Most current database systems and external data sources support an efficient and reliable export of very large data volumes into (relatively cheap) object storage.
-
Parquet has become almost ubiquitous as a file interchange format that offers highly efficient storage and retrieval. ClickHouse has blazingly fast built-in Parquet support.
-
A ClickHouse server can process and insert the data from files stored in object storage with a high level of parallelism utilizing all available CPU cores.
② You can then use our ClickLoad script, described in more detail below, that orchestrates a reliable and resilient data transfer into your ClickHouse target table by utilizing one of our object storage integration table functions (e.g. s3, GCS, or AzureBlobStorage).
We provide a step-by-step example of using ClickLoad here.
The core approach
The basic idea for ClickLoad originated from our support team guiding some of our ClickHouse Cloud customers in successfully migrating their data with trillions of rows.
In a classical divide-and-conquer fashion, ClickLoad splits the overall to-be-loaded file data into repeatable and retry-able tasks. These tasks are used to load the data from object storage incrementally into ClickHouse tables, with automatic retries in case of failures.
For easy scalability, we adapt the queue-worker approach introduced in another blog. Stateless ClickLoad workers orchestrate the data loading by reliably claiming file load tasks from a task table backed by the KeeperMap table engine. Each task potentially contains multiple files to process, with the KeeperMap table guaranteeing each task (and thus file) can only be assigned to one worker. This allows us to parallelize the file load process by spinning up additional workers, increasing the overall ingest throughput.
As a prerequisite, the task table is populated with file load tasks for the ClickLoad workers:
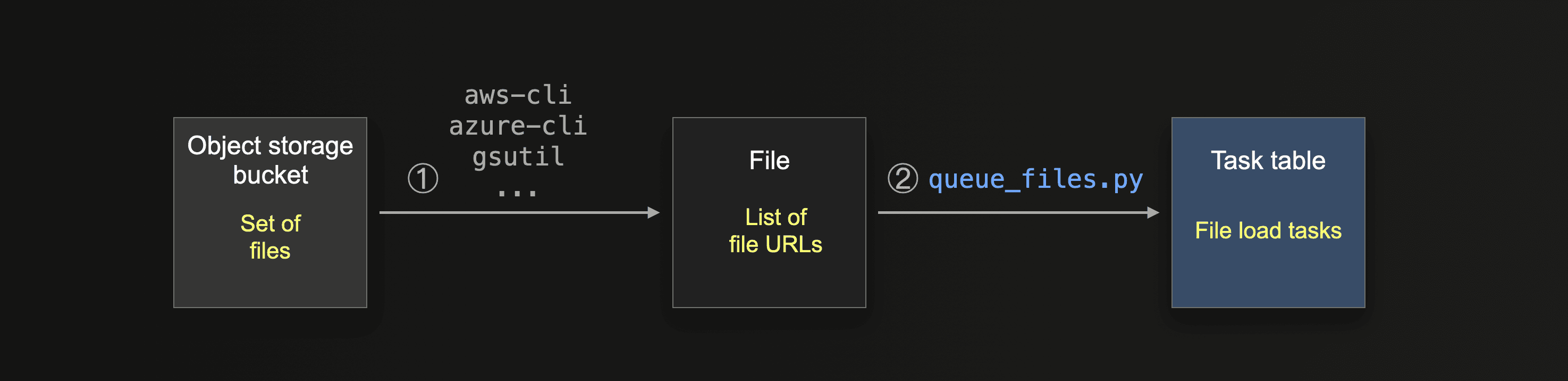
① Users can utilize a corresponding object storage command line interface tool (e.g. Amazon aws-cli, Microsoft azure-cli, or Google gsutil) for creating a local file containing the object storage urls of the to-be-loaded files.
② We provide instructions plus a separate script queue_files.py that splits the entries from the file from step ① into chunks of file urls and loads these chunks as file load tasks into the task table.
The following diagram shows how these file load tasks from the task table are used by a ClickLoad worker orchestrating the data load:
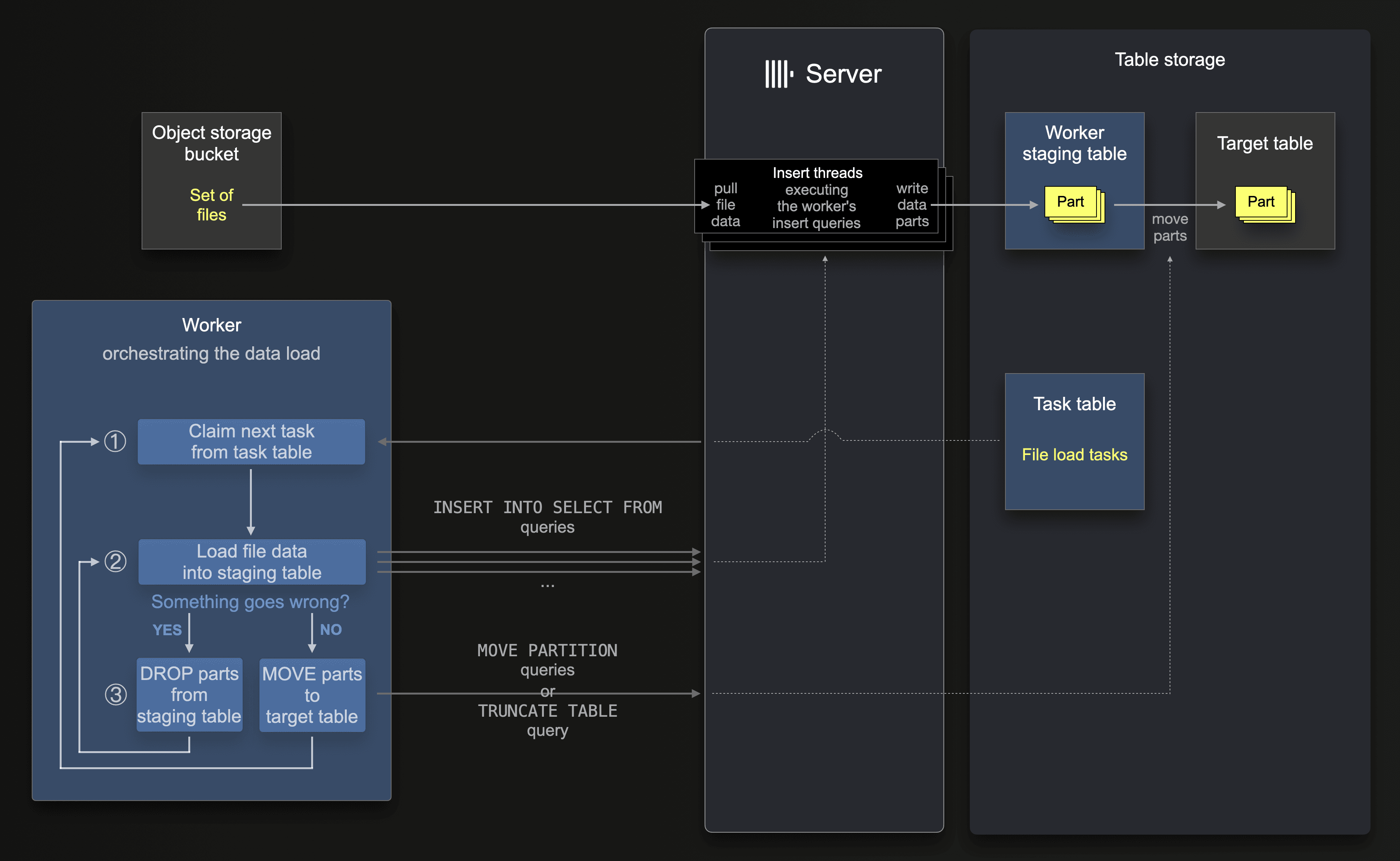
For easy retry-able file loads in case something goes wrong, each ClickLoad worker first loads all file data into a (different per worker) staging table: after ① claiming its next task, a worker iterates over the task’s list of file urls and ② (sequentially) instructs the ClickHouse server to load each file from the task into a staging table by using INSERT INTO SELECT FROM queries (where the ClickHouse server by itself pulls the file data from object storage). This inserts the file data with a high level of parallelism and creates data parts in the staging table.
Suppose one of the insert queries for the current task is interrupted and fails in between a state where the staging table already contains some data in the form of parts. In this case, the worker first ③ instructs the ClickHouse server to truncate the staging table (drop all parts), and then ② retries its current file load task from scratch. On successfully completing the task, the worker ③ uses specific queries and commands, causing the ClickHouse server to move all parts (from all partitions) from the staging table to the target table. The worker then ① claims and processes the next task from the task table.
In ClickHouse Cloud, all data is stored separately from the ClickHouse servers in shared object storage. Consequently, moving parts is a lightweight operation that only changes parts' metadata but doesn’t physically move parts.
Note that each worker creates its own staging tables on startup and then executes an endless loop checking for unprocessed tasks, with sleep breaks in case no new task is found. We use a signal handler registered for SIGINT (Ctrl+C) and SIGTERM (Unix process kill signal) signals for cleaning up (deleting) the worker’s staging tables when a worker is shut down.
Also, note that a worker processes atomic chunks of files instead of single files to reduce contention on Keeper when replicated tables are used. The latter creates a (much) larger number of MOVE PARTITION calls that are coordinated by Keeper in a replicated cluster. Furthermore, we randomize the file chunk size to prevent Keeper contention when multiple parallel workers run.
Staging tables ensure that loaded data will be stored exactly once
The INSERT INTO SELECT FROM queries used by the ClickLoad workers could insert the file data directly into the target table. But when an insert query invariably fails, so as not to cause data duplication when we retried the task, we would need to delete all data from the previously failed task. This deletion is much more difficult than when data is inserted into a staging table, which can simply be truncated.
For example, just dropping parts in the target table is impossible as the initially inserted parts get automatically merged (potentially with parts from prior successful inserts) in the background.
Relying on automatic insert deduplication is also not generally possible because (1) it is highly unlikely that insert threads recreate exactly the same insert blocks, and (2) with a high number of running workers, the default per-table deduplication window in ClickHouse could be insufficient.
Lastly, explicitly deduplicating all rows with an OPTIMIZE DEDUPLICATE statement would be (1) a very heavy and slow operation the larger the target table gets and (2) could potentially accidentally deduplicate rows that are intentionally identical in the source data files.
The only way to reliably delete the data from a failed insert from the target table before retrying the insert would be to use an ALTER TABLE DELETE, a lightweight delete, or a lightweight update statement. All of these are eventually materialized with a heavy mutation operation, which becomes more expensive as the table increases in size.
Conversely, the detour via a staging table allows our workers to guarantee that each row from the loaded files is stored exactly once in the target table by efficiently dropping or moving parts, depending on whether the task failed or succeeded.
Workers are lightweight
ClickLoad’s worker script only orchestrates data loading but doesn’t actually load any data by itself. Instead, the ClickHouse server and its hardware resources are utilized for pulling the data from object storage and writing it into ClickHouse tables.
Note that running ClickLoad requires a separate machine with network access to both the source object storage bucket and the target ClickHouse instance. Because of the workers’ lightweight working fashion, a moderately sized machine can run 100s of parallel worker instances.
Insert throughput can be easily scaled
Multiple workers and multiple ClickHouse servers (with a load balancer in front in ClickHouse Cloud) can be utilized for scaling the ingest throughput:
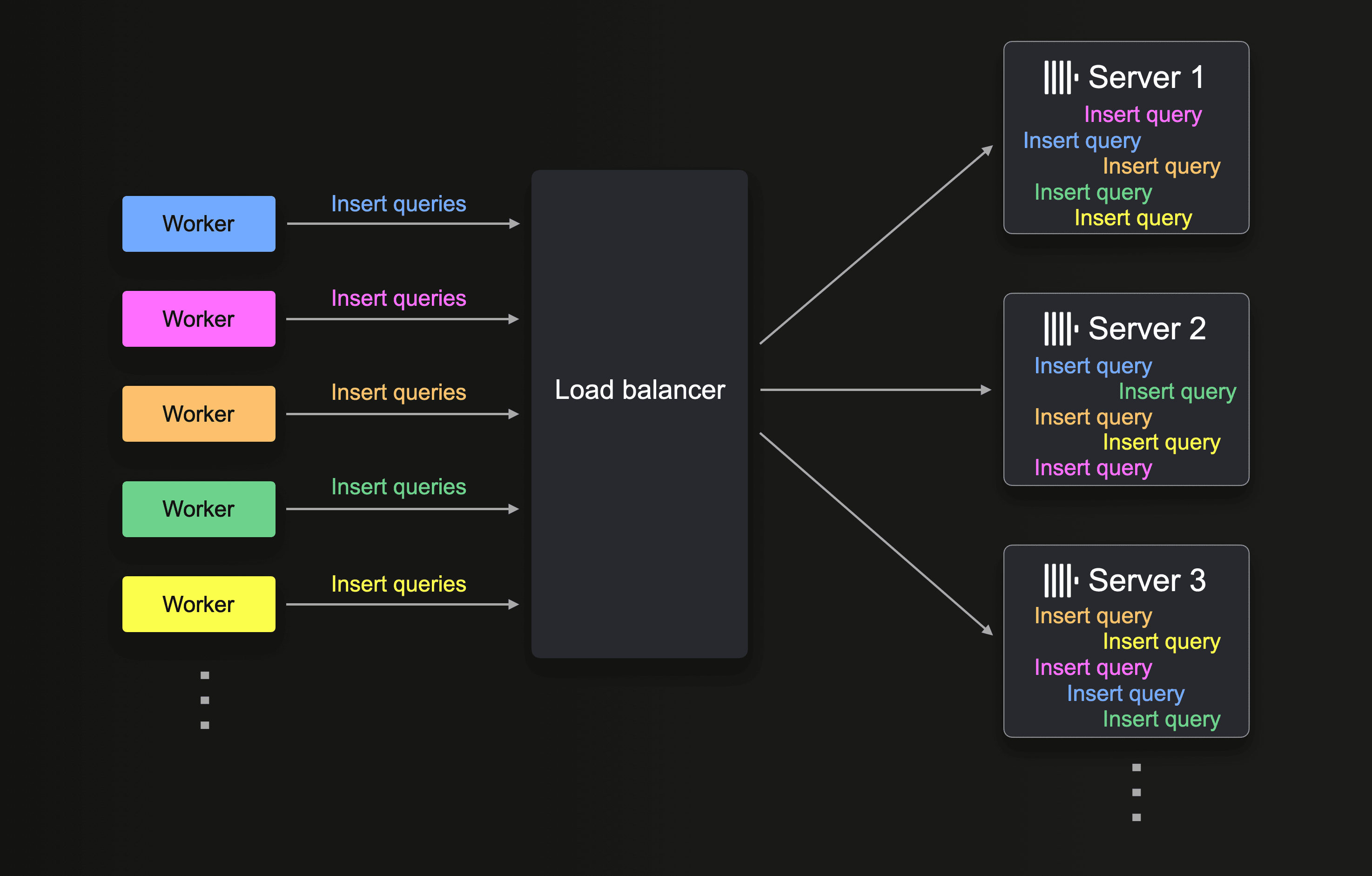
The INSERT INTO SELECT FROM queries from all workers are evenly distributed to, and then executed in parallel, by the number of available ClickHouse servers. Note that each worker has its own staging table.
Doubling the number of workers can double the ingest throughput, provided the ClickHouse servers executing the insert queries have enough resources.
Similarly, doubling the number of ClickHouse servers can double the ingest throughput. In our tests, when loading a 600+ billion row dataset (with 100 parallel workers), increasing the number of ClickHouse servers in a ClickHouse Cloud service from 3 to 6 exactly doubled the ingest throughput (from 4 million rows/second to 8 million rows/second).
Continuous data ingestion is possible
As mentioned above, each worker executes an endless loop checking for unprocessed tasks in the task table with sleep breaks in case no new task is found. This allows the easy implementation of a continuous data ingestion process by adding new file load tasks into the task table in case new files are detected in the object storage bucket. The running workers will then automatically claim these new scheduled tasks. We describe a concrete example here but leave this implementation to the reader
Any partitioning key is supported
The ClickLoad worker's file load mechanism is independent of any partitioning scheme of the target table. The workers don’t create any partitions by themselves. We also don’t require that each loaded file belong to a specific partition. Instead, the target table can have any (or no) custom partition key, which we duplicate in the staging table (which is a DDL-level clone of the target table).
After each successful files chunk transfer, we just move over all (parts belonging to) partitions that were naturally created for the staging table during the ingest of data from the currently processed files. This means that overall, exactly the same number of partitions are created for the target table as if we inserted all data (without using our ClickLoad script) directly into the target table.
You can find a more detailed explanation here.
Projections and Materialized views are fully supported
Loading trillions of rows reliably into the target table is a good first step. However, projections and materialized views can supercharge your queries by allowing a table to have automatic incremental aggregations and multiple-row orders with additional primary indexes.
Creating projections or materialized views on the target table after the trillions of rows are initially loaded would require expensive projection materializations or a ClickHouse-side table-to-table reload of the data for triggering materialized views. Both of these would again take a long period of time, including the risk that something goes wrong. Therefore, the most efficient option is to create projections and materialized views before the initial data load. ClickLoad fully (and transparently) supports this.
Projections support
The staging table created by our ClickLoad worker script is a full DDL-level clone of the target table, including all defined projections. Because the data parts of projections are stored as subdirectories within the part directories of the projection's host table, they are automatically moved over from the staging table to the target table after each file load task.
Materialized views support
The following diagram shows the basic logic for ClickLoad’s materialized views support:
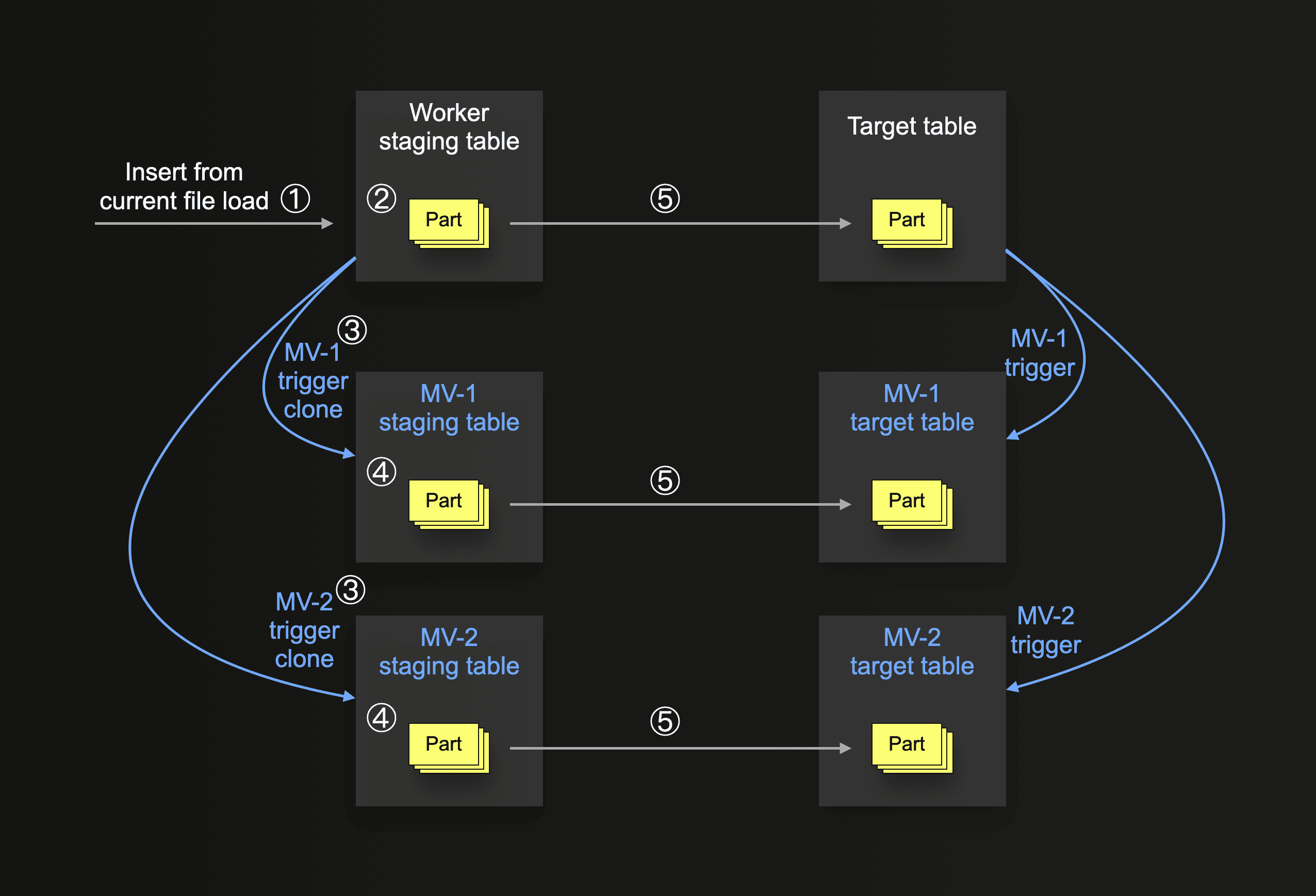
In the diagram above, the target table has two connected materialized views (MV-1 and MV-2) that would trigger on new direct inserts into the target table and store the data (in a transformed form) in their own target tables.
Our ClickLoad worker script replicates this behavior by automatically creating a staging table not just for the main target table but also for all materialized view (mv) target tables. Together with the additional staging tables, we automatically create clones of the materialized view triggers but configure them to react to inserts on the staging table and then target their corresponding target staging tables.
When ① data gets inserted into the target table’s staging table (and ② stored in the form of parts), this insert ③ automatically triggers the mv copies, ④ causing corresponding inserts into the target tables of the staging mvs. If the whole insert succeeds, we ⑤ move all parts (partitions) from the staging tables into their counterparts. If something goes wrong, e.g., one of the materialized views has a problem with the current data, we just drop all parts from all staging tables and retry the insert. If the maximum number of retries is exceeded, we skip (and log) the current file and continue with the next one. With this mechanism, we ensure that the insert is atomic and the data is always consistent between the main target table and all connected materialized views.
Note that moving parts into the target table in step ⑤ does not trigger any of the connected original materialized views.
Detailed error information about failed materialized views is in the query_views_log system table.
Also, as explained above, the target tables for the materialized views can have any (or no) custom partition key. Our orchestration logic is independent of this.
Our ClickLoad worker script currently only supports materialized views created with the TO target_table clause and doesn’t support chained (cascaded) materialized views.
ClickLoad works best with moderate file sizes
The worker’s processing unit is a whole file. If something goes wrong while a file is loaded, we reload the whole file. Therefore, we recommend using moderately sized files with millions but not trillions of rows per file and approximately 100 to 150 MB in compressed size. This ensures an efficient retry mechanism.
PRs are welcome
As mentioned above, the origin of our ClickLoad script was helping some of our ClickHouse Cloud customers migrate their large data amounts during support interactions. Therefore, the script currently relies on cloud-specific features like MOVE PARTITION being a lightweight operation for the SharedMergeTree engine. This engine also allows the easy scaling up of the number of ClickHouse servers for increasing the ingest throughput. We haven’t had a chance to test the script on alternative setups yet, but we welcome contributions. In principle, it should work on alternative setups with minimal tweaks. The MOVE PARTITION operations must run on all shards in a sharded cluster, e.g., by utilizing the ON CLUSTER clause. Also, note that MOVE PARTITION currently cannot be run concurrently when zero-copy replication is used. We hope the script serves as a helpful starting point, and we welcome its use in more use cases and scenarios and collaborating on improvements!
In the future, we expect the mechanics of this script to be considered as we build out support in ClickPipes for ingesting files from object storage. Stay tuned for updates!
Summary
Loading large datasets with trillions of rows can be a challenge. To overcome this, ClickHouse Cloud has ClickPipes - a built-in managed integration solution featuring support for resiliently loading large data volumes robust to interruptions with automatic retries. If your external data source is not supported yet, we explored the mechanics of ClickLoad - a script for loading large datasets incrementally and reliably over a long period of time.
This finishes our three-part blog series about supercharging large data loads.


