Table of Contents
- Introduction
- MergeTree table engines are the core of ClickHouse
- ClickHouse Cloud enters the stage
- Challenges with running ReplicatedMergeTree in ClickHouse Cloud
- Zero-copy replication does not address the challenges
- SharedMergeTree for cloud-native data processing
- Benefits for ClickHouse Cloud users
- The new ClickHouse Cloud default table engine
- SharedMergeTree in action
- Introducing Lightweight Updates, boosted by SharedMergeTree
- Summary
Introduction
ClickHouse is the fastest and most resource-efficient database for real-time applications and analytics. Tables from the family of MergeTree table engines are a core component of ClickHouse’s fast data processing capabilities. In this post, we describe the motivation and mechanics behind a new member of this family – the SharedMergeTree table engine.
This table engine is a more efficient drop-in replacement for the ReplicatedMergeTree table engine in ClickHouse Cloud and is engineered and optimized for cloud-native data processing. We look under the hood of this new table engine, explain its benefits, and demonstrate its efficiency with a benchmark. And we have one more thing for you. We are introducing lightweight updates which have a synergy effect with the SharedMergeTree.
MergeTree table engines are the core of ClickHouse
Table engines from the MergeTree family are the main table engines in ClickHouse. They are responsible for storing the data received by an insert query, merging that data in the background, applying engine-specific data transformations, and more. Automatic data replication is supported for most tables in the MergeTree family through the replication mechanism of the ReplicatedMergeTree base table engine.
In traditional shared-nothing ClickHouse clusters, replication via ReplicatedMergeTree is used for data availability, and sharding can be used for cluster scaling. ClickHouse Cloud took a new approach to build a cloud-native database service based on ClickHouse, which we describe below.
ClickHouse Cloud enters the stage
ClickHouse Cloud entered public beta in October 2022 with a radically different architecture optimized for the cloud (and we explained how we built it from scratch in a year). By storing data in virtually limitless shared object storage, storage and compute are separated: All horizontally and vertically scalable ClickHouse servers have access to the same physical data and are effectively multiple replicas of a single limitless shard:
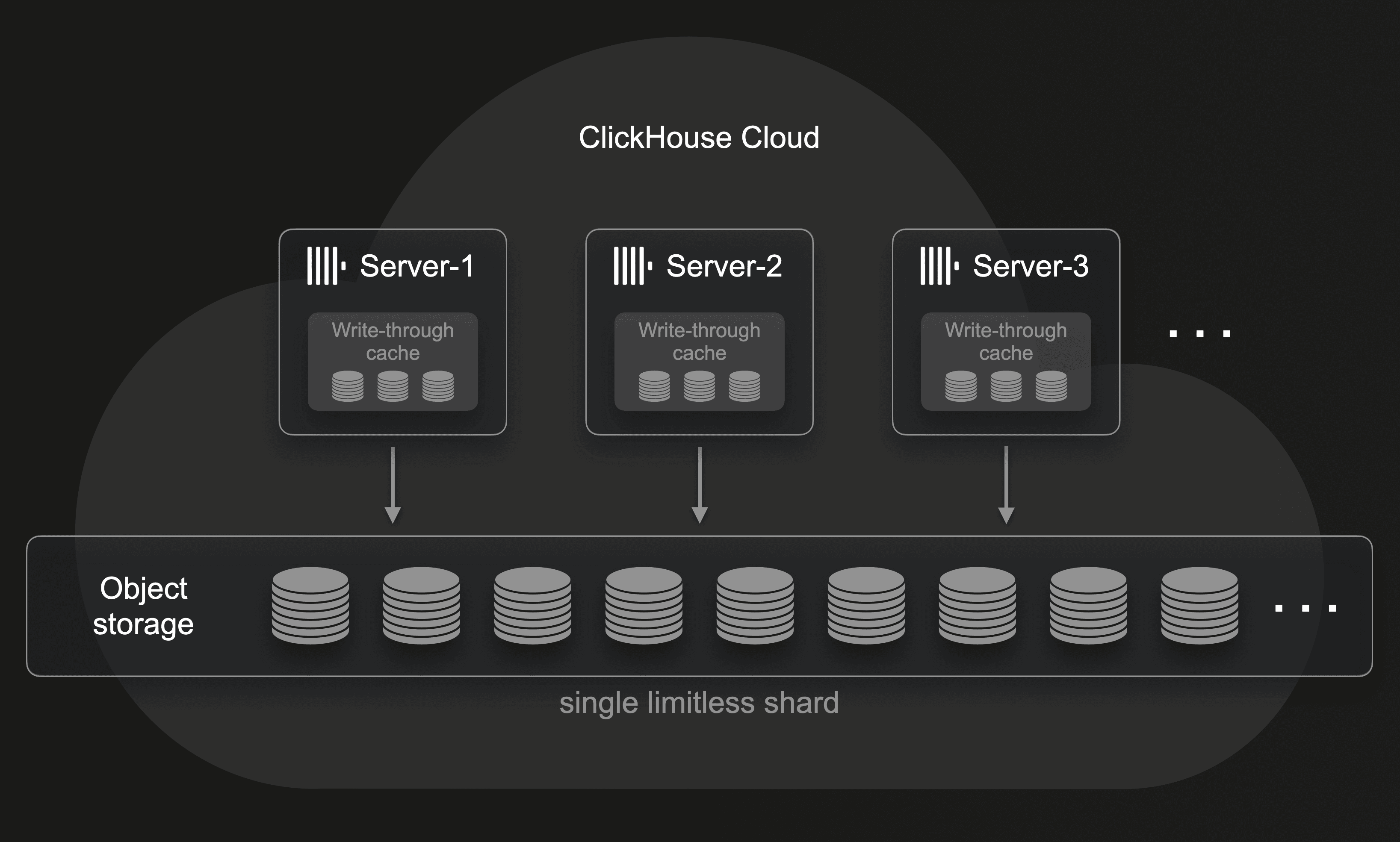
Shared object storage for data availability
Because ClickHouse Cloud stores all data in shared object storage, there is no need to create physical copies of data on different servers explicitly. Object storage implementations like Amazon AWS Simple Storage Service, Google GCP Cloud Storage, and Microsoft Azure Blob Storage ensure storage is highly available and fault tolerant.
Note that ClickHouse Cloud services feature a multi-layer read-through and write-through cache (on local NVMe SSDs) that is designed to work natively on top of object storage to provide fast analytical query results despite the slower access latency of the underlying primary data store. Object storage exhibits slower access latency, but provides highly concurrent throughput with large aggregate bandwidth. ClickHouse Cloud exploits this by utilizing multiple I/O threads for accessing object storage data, and by asynchronously prefetching the data.
Automatic cluster scaling
Instead of using sharding for scaling the cluster size, ClickHouse Cloud allows users to simply increase the size and number of the servers operating on top of the shared and virtually infinite object storage. This increases the parallelism of data processing for both INSERT and SELECT queries.
Note that the ClickHouse Cloud servers are effectively multiple replicas of a single limitless shard, but they are not like replica servers in shared-nothing clusters. Instead of containing local copies of the same data, these servers have access to the same data stored in shared object storage. This turns these servers into dynamic compute units or compute nodes, respectively, whose size and number can be easily adapted to workloads. Either manually or fully automatically. This diagram illustrates that:
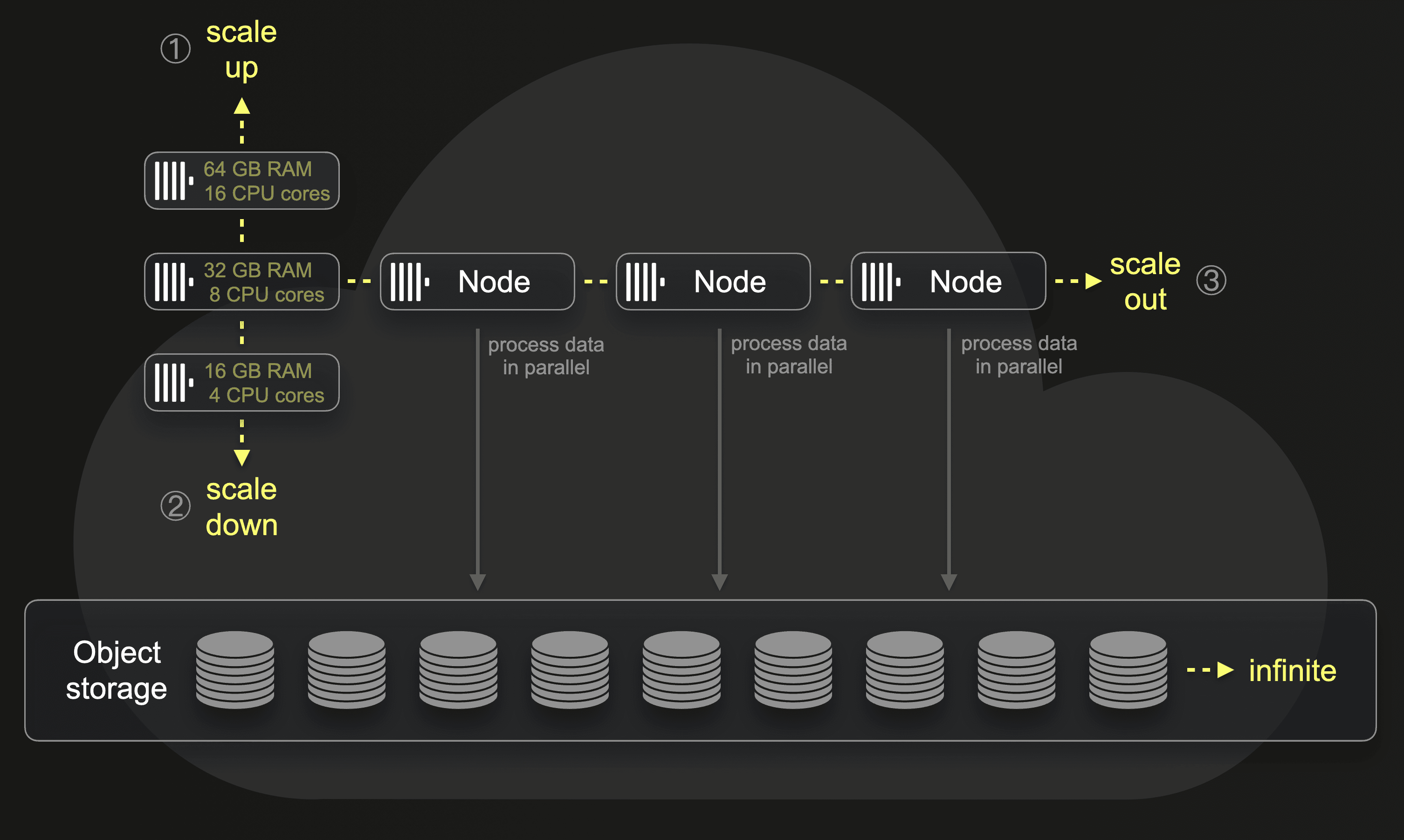 ① Via scale up and ② scale down operations, we can change the size (amount of CPU cores and RAM) of a node. And per ③ scale out, we can increase the number of nodes participating in parallel data processing. Without requiring any physical resharding or rebalancing of the data, we can freely add or remove nodes.
① Via scale up and ② scale down operations, we can change the size (amount of CPU cores and RAM) of a node. And per ③ scale out, we can increase the number of nodes participating in parallel data processing. Without requiring any physical resharding or rebalancing of the data, we can freely add or remove nodes.
For this cluster scaling approach, ClickHouse Cloud needs a table engine supporting higher numbers of servers accessing the same shared data.
Challenges with running ReplicatedMergeTree in ClickHouse Cloud
The ReplicatedMergeTree table engine isn’t ideal for the intended architecture of ClickHouse Cloud since its replication mechanism is designed to create physical copies of data on a small number of replica servers. Whereas ClickHouse Cloud requires an engine with support for a high amount of servers on top of shared object storage.
Explicit data replication is not required
We briefly explain the replication mechanism of the ReplicatedMergeTree table engine. This engine uses ClickHouse Keeper (also referred to as “Keeper”) as a coordination system for data replication via a replication log. Keeper acts as a central store for replication-specific metadata and table schemas and as a consensus system for distributed operations. Keeper ensures sequential block numbers are assigned in order for part names. Assignment of merges and mutations to specific replica servers is made with the consensus mechanisms that Keeper provides.
The following diagram sketches a shared-nothing ClickHouse cluster with 3 replica servers and shows the data replication mechanism of the ReplicatedMergeTree table engine:
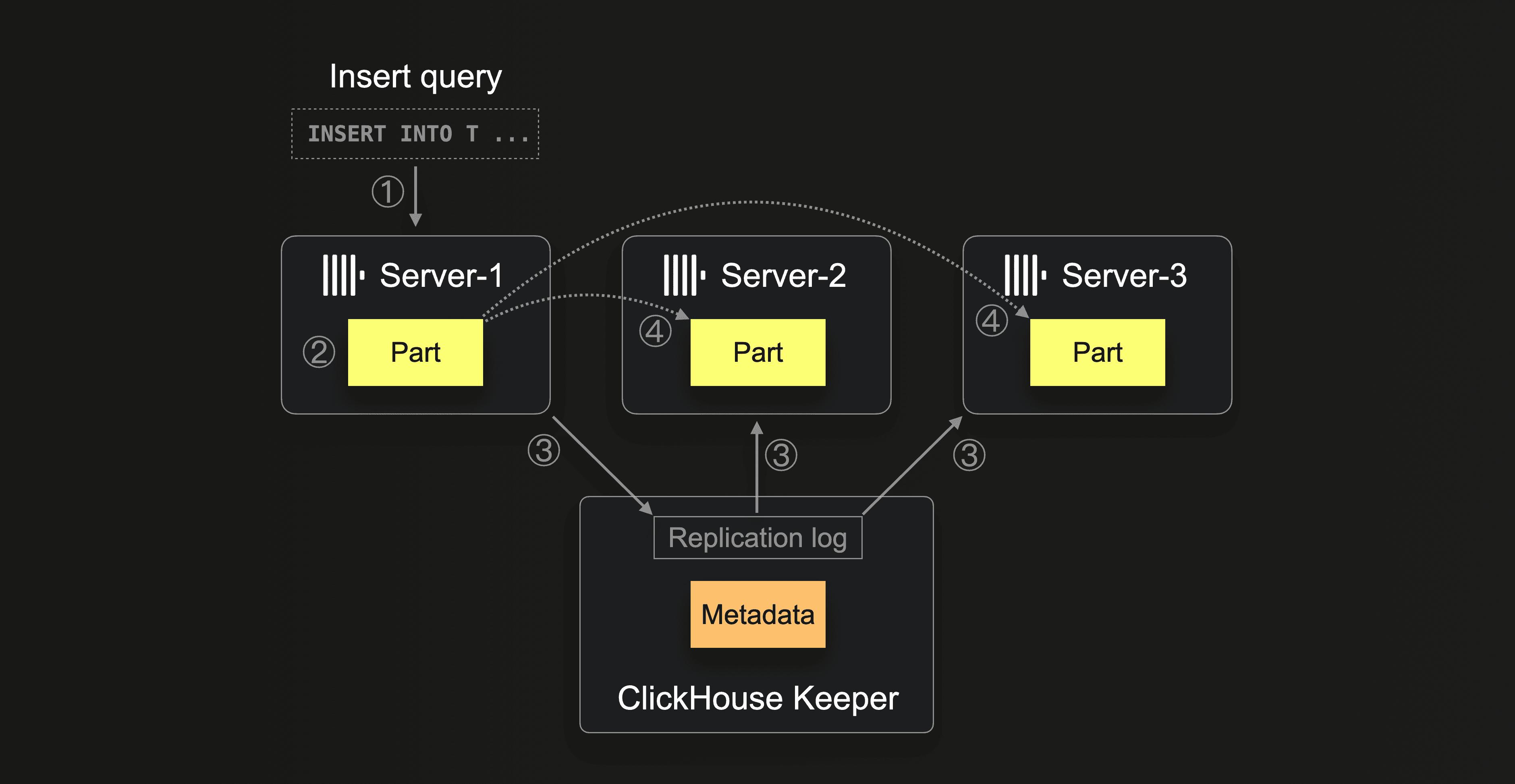 When ① server-1 receives an insert query, then ② server-1 creates a new data part with the query's data on its local disk. ③ Via the replication log, the other servers (server-2, server-3) are informed that a new part exists on server-1. At ④, the other servers independently download (“fetch”) the part from server-1 to their own local filesystem. After creating or receiving parts, all three servers also update their own metadata describing their set of parts in Keeper.
When ① server-1 receives an insert query, then ② server-1 creates a new data part with the query's data on its local disk. ③ Via the replication log, the other servers (server-2, server-3) are informed that a new part exists on server-1. At ④, the other servers independently download (“fetch”) the part from server-1 to their own local filesystem. After creating or receiving parts, all three servers also update their own metadata describing their set of parts in Keeper.
Note that we only showed how a newly created part is replicated. Part merges (and mutations) are replicated in a similar way. If one server decides to merge a set of parts, then the other servers will automatically execute the same merge operation on their local part copies (or just download the merged part).
In case of a complete loss of local storage or when new replicas are added, the ReplicatedMergeTree clones data from an existing replica.
ClickHouse Cloud uses durable shared object storage for data availability and doesn’t need the explicit data replication of the ReplicatedMergeTree.
Sharding for cluster scaling is not needed
Users of shared-nothing ClickHouse clusters can use replication in combination with sharding for handling larger datasets with more servers. The table data is split over multiple servers in the form of shards (distinct subsets of the table’s data parts), and each shard usually has 2 or 3 replicas to ensure storage and data availability. Parallelism of data ingestion and query processing can be increased by adding more shards. Note that ClickHouse abstracts clusters with more complex topologies under a distributed table so that you can do distributed queries in the same way as local ones.
ClickHouse Cloud doesn’t need sharding for cluster scaling, as all data is stored in virtually limitless shared object storage, and the level of parallel data processing can be simply increased by adding additional servers with access to the shared data. However, the replication mechanism of the ReplicatedMergeTree is designed initially to work on top of local filesystems in shared-nothing cluster architectures and with a small number of replica servers. Having a high number of replicas of ReplicatedMergeTree is an anti-pattern, with the servers creating too much contention on the replication log and overhead on the inter-server communication.
Zero-copy replication does not address the challenges
ClickHouse Cloud offers automatic vertical scaling of servers – the number of CPU cores and RAM of servers is automatically adapted to workloads based on CPU and memory pressure. We started with each ClickHouse Cloud service having a fixed number of 3 servers and eventually introduced horizontal scaling to an arbitrary number of servers.
In order to support these advanced scaling operations on top of shared storage with ReplicatedMergeTree, ClickHouse Cloud used a special modification called zero-copy replication for adapting the ReplicatedMergeTree tables’ replication mechanism to work on top of shared object storage.
This adaptation uses almost the same original replication model, except that only one copy of data is stored in object storage. Hence the name zero-copy replication. Zero data is replicated between servers. Instead, we replicate just the metadata:
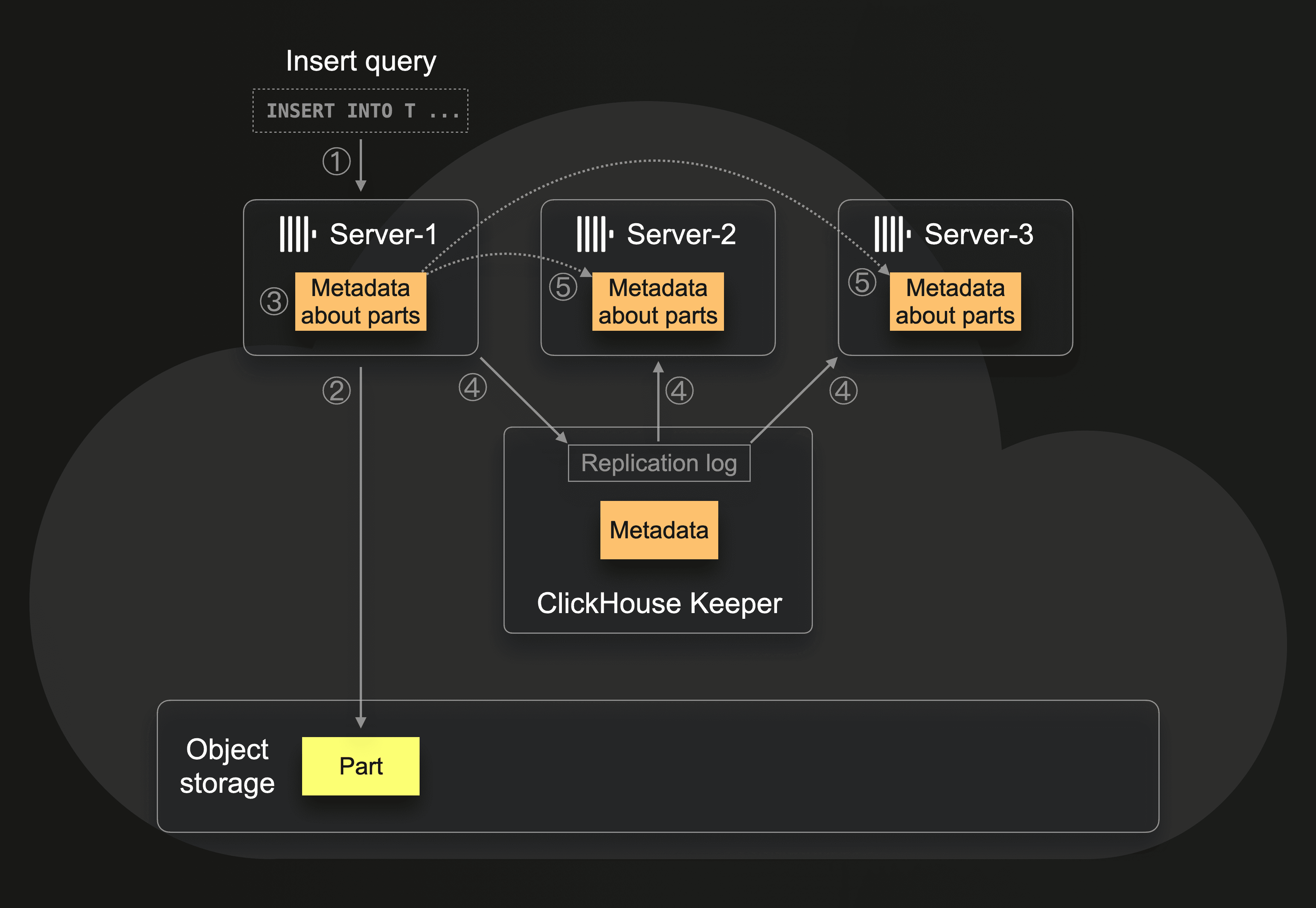 When ① server-1 receives an insert query, then ② the server writes the inserted data in the form of a part to object storage, and ③ writes metadata about the part (e.g., where the part is stored in object storage) to its local disk. ④ Via the replication log, the other servers are informed that a new part exits on server-1, although the actual data is stored in object storage. And ⑤ the other servers independently download (“fetch”) the metadata from server-1 to their own local filesystem. To ensure data is not deleted until all the replicas remove metadata pointing to the same object, a distributed mechanism of reference counting is used: After creating or receiving metadata, all three servers also update their own metadata set of parts info in ClickHouse Keeper.
When ① server-1 receives an insert query, then ② the server writes the inserted data in the form of a part to object storage, and ③ writes metadata about the part (e.g., where the part is stored in object storage) to its local disk. ④ Via the replication log, the other servers are informed that a new part exits on server-1, although the actual data is stored in object storage. And ⑤ the other servers independently download (“fetch”) the metadata from server-1 to their own local filesystem. To ensure data is not deleted until all the replicas remove metadata pointing to the same object, a distributed mechanism of reference counting is used: After creating or receiving metadata, all three servers also update their own metadata set of parts info in ClickHouse Keeper.
For this, and for assigning operations like merges and mutations to specific servers, the zero-copy replication mechanism relies on creating exclusive locks in Keeper. Meaning that these operations can block each other and need to wait until the currently executed operation is finished.
Zero-copy replication does not sufficiently address the challenges with ReplicatedMergeTree on top of shared object storage:
- Metadata is still coupled with servers: metadata storage is not separated from compute. Zero-copy replication still requires a local disk on each server for storing the metadata about parts. Local disks are additional points of failure with reliability depending on the number of replicas, which is tied to compute overhead for high availability.
- Durability of zero-copy replication depends on guarantees of 3 components: object storage, Keeper, and local storage. This number of components adds complexity and overhead as this stack was built on top of existing components and not reworked as a cloud-native solution.
- This is still designed for a small number of servers: metadata is updated using the same replication model designed initially for shared-nothing cluster architectures with a small number of replica servers. A high number of servers creates too much contention on the replication log and creates a high overhead on locks and inter-server communication. Additionally, there is a lot of complexity in the code implementing the replication and cloning of data from one replica to another. And it is impossible to make atomic commits for all replicas as metadata is changed independently.
SharedMergeTree for cloud-native data processing
We decided (and planned from the beginning) to implement a new table engine from scratch for ClickHouse Cloud called SharedMergeTree – designed to work on top of a shared storage. The SharedMergeTree is the cloud-native way for us to (1) make the MergeTree code more straightforward and maintainable, (2) to support not only vertical but also horizontal auto-scaling of servers, and (3) to enable future features and improvements for our Cloud users, like higher consistency guarantees, better durability, point-in-time restores, time-travel through data, and more.
Here we describe briefly how the SharedMergeTree natively supports ClickHouse Cloud's automatic cluster scaling model. As a reminder: the ClickHouse Cloud servers are compute units with access to the same shared data whose size and number can be automatically changed. For this mechanism, the SharedMergeTree completely separates the storage of data and metadata from the servers and uses interfaces to Keeper to read, write and modify the shared metadata from all servers. Each server has a local cache with subsets of the metadata and gets automatically informed about data changes by a subscription mechanism.
This diagram sketches how a new server is added to the cluster with the SharedMergeTree:
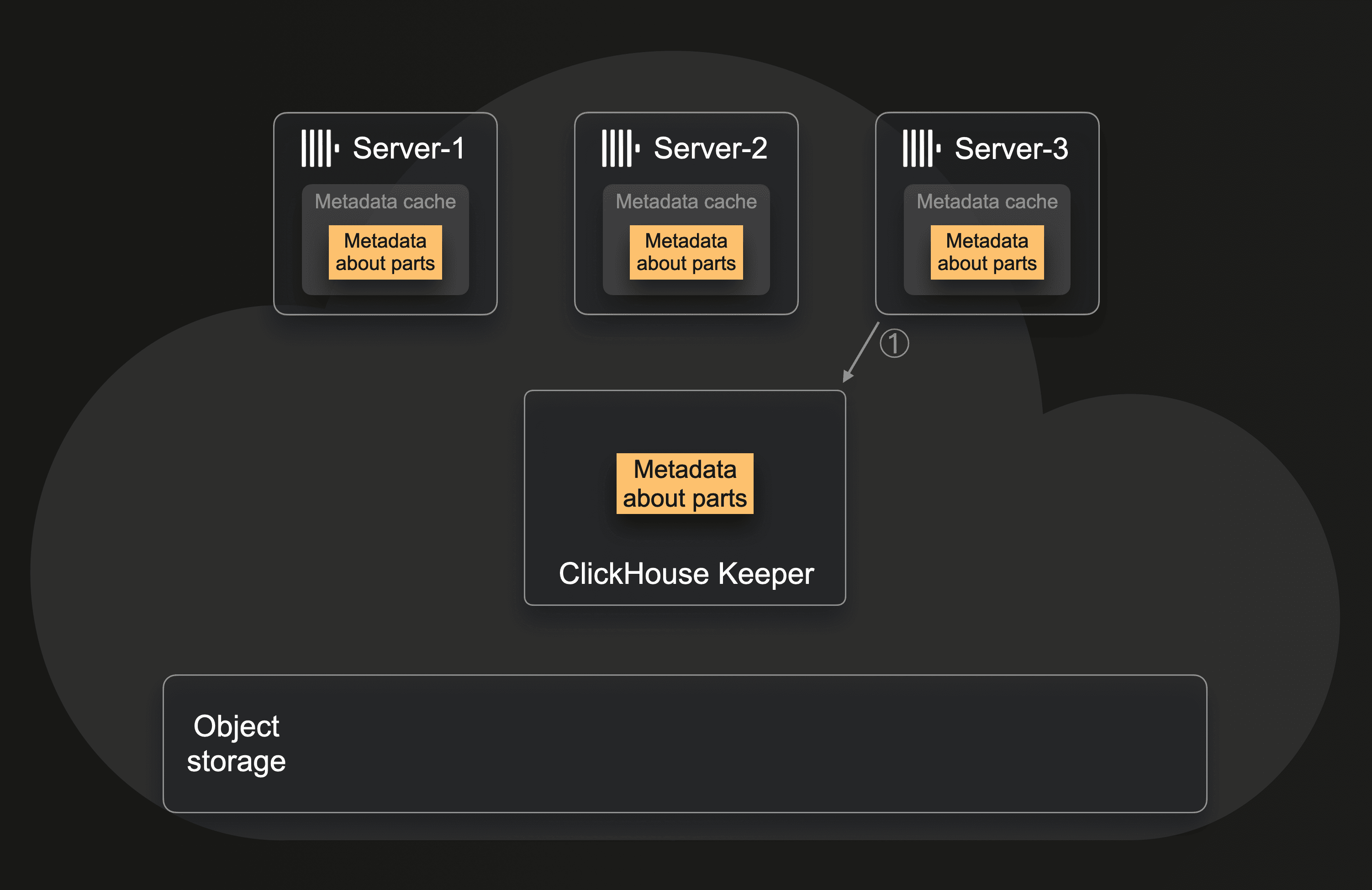 When server-3 is added to the cluster, then this new server ① subscribes for metadata changes in Keeper and fetches parts of the current metadata into its local cache. This doesn't require any locking mechanism; the new server basically just says, "Here I am. Please keep me up to date about all data changes". The newly added server-3 can participate in data processing almost instantly as it finds out what data exists and where in object storage by fetching only the necessary set of shared metadata from Keeper.
When server-3 is added to the cluster, then this new server ① subscribes for metadata changes in Keeper and fetches parts of the current metadata into its local cache. This doesn't require any locking mechanism; the new server basically just says, "Here I am. Please keep me up to date about all data changes". The newly added server-3 can participate in data processing almost instantly as it finds out what data exists and where in object storage by fetching only the necessary set of shared metadata from Keeper.
The following diagram shows how all servers get to know about newly inserted data:
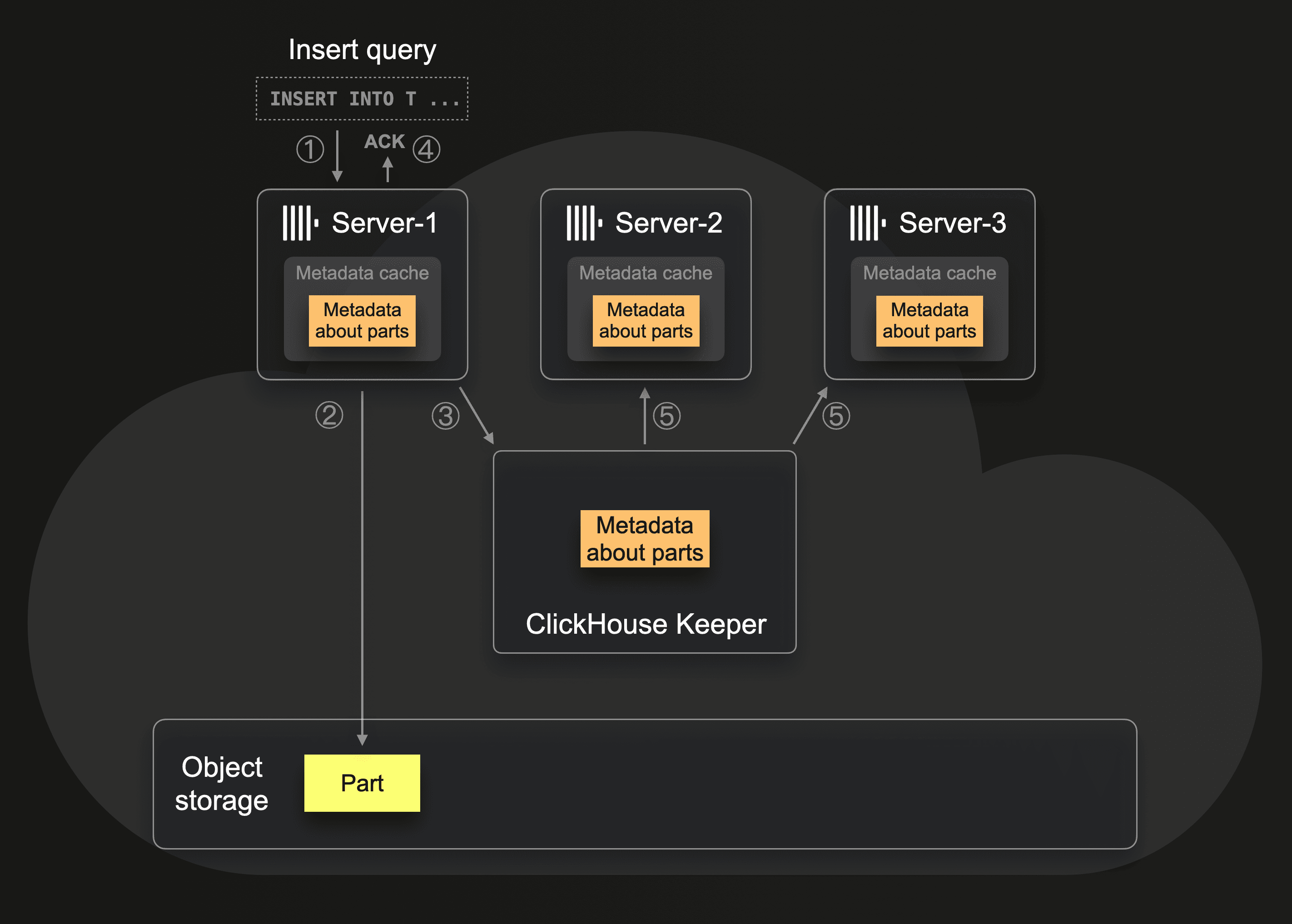 When ① server-1 receives an insert query, then ② the server writes the query’s data in the form of a part to object storage. ③ Server-1 also stores information about the part in its local cache and in Keeper (e.g., which files belong to the part and where the blobs corresponding to files reside in object storage). After that, ④ ClickHouse acknowledges the insert to the sender of the query. The other servers (server-2, server-3) are ⑤ automatically notified about the new data existing in object storage via Keeper’s subscription mechanism and fetch metadata updates into their local caches.
When ① server-1 receives an insert query, then ② the server writes the query’s data in the form of a part to object storage. ③ Server-1 also stores information about the part in its local cache and in Keeper (e.g., which files belong to the part and where the blobs corresponding to files reside in object storage). After that, ④ ClickHouse acknowledges the insert to the sender of the query. The other servers (server-2, server-3) are ⑤ automatically notified about the new data existing in object storage via Keeper’s subscription mechanism and fetch metadata updates into their local caches.
Note that the insert query’s data is durable after step ④. Even if Server-1 crashes, or any or all of the other servers, the part is stored in highly available object storage, and the metadata is stored in Keeper (which has a highly available setup of at least 3 Keeper servers).
Removing a server from the cluster is a straightforward and fast operation too. For a graceful removal, the server just deregisters himself from Keeper in order to handle ongoing distributed queries properly without warning messages that a server is missing.
Benefits for ClickHouse Cloud users
In ClickHouse Cloud, the SharedMergeTree table engine is a more efficient drop-in replacement for the ReplicatedMergeTree table engine. Bringing the following powerful benefits to ClickHouse Cloud users.
Seamless cluster scaling
ClickHouse Cloud stores all data in virtually infinite, durable, and highly available shared object storage. The SharedMergeTree table engine adds shared metadata storage for all table components. It enables virtually limitless scaling of the servers operating on top of that storage. Servers are effectively stateless compute nodes, and we can almost instantly change their size and number.
Example
Suppose a ClickHouse Cloud user is currently using three nodes, as shown in this diagram:
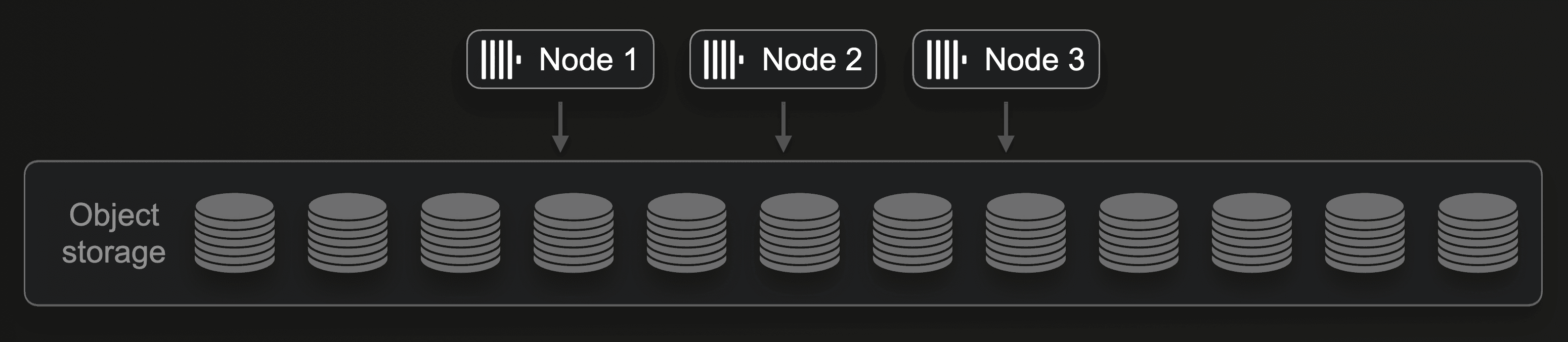 It is straightforward to (manually or automatically) double the amount of compute by either doubling the size of each node or (for example, when the maximum size per node is reached) by doubling the number of nodes from three to six:
It is straightforward to (manually or automatically) double the amount of compute by either doubling the size of each node or (for example, when the maximum size per node is reached) by doubling the number of nodes from three to six:
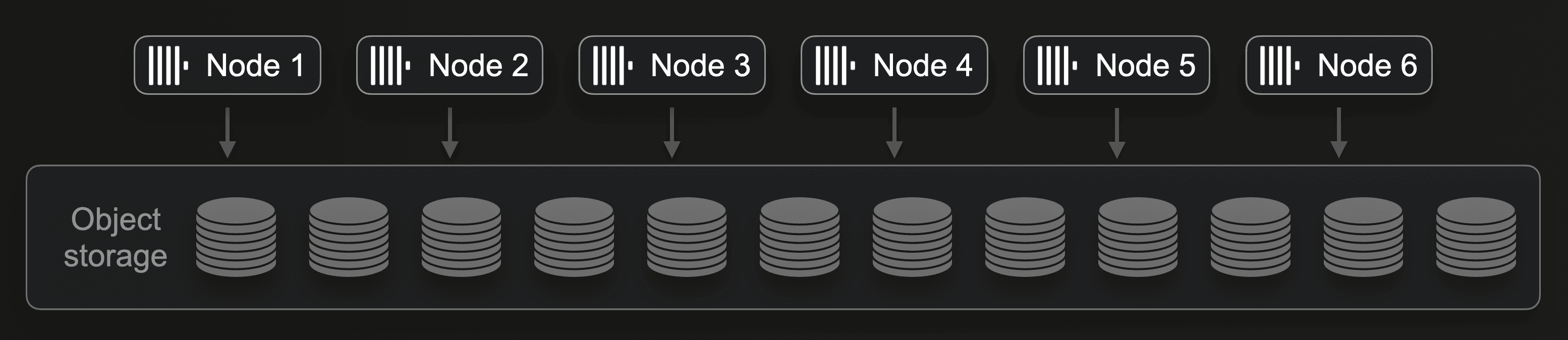 This doubles the ingest throughput. For SELECT queries, increasing the number of nodes increases the level of parallel data processing for both the execution of concurrent queries and the concurrent execution of a single query. Note that increasing (or decreasing) the number of nodes in ClickHouse Cloud doesn’t require any physical resharding or rebalancing of the actual data. We can freely add or remove nodes with the same effect as manual sharding in shared-nothing clusters.
This doubles the ingest throughput. For SELECT queries, increasing the number of nodes increases the level of parallel data processing for both the execution of concurrent queries and the concurrent execution of a single query. Note that increasing (or decreasing) the number of nodes in ClickHouse Cloud doesn’t require any physical resharding or rebalancing of the actual data. We can freely add or remove nodes with the same effect as manual sharding in shared-nothing clusters.
Changing the number of servers in a shared-nothing cluster requires more effort and time. If a cluster currently consists of three shards with two replicas per shard:
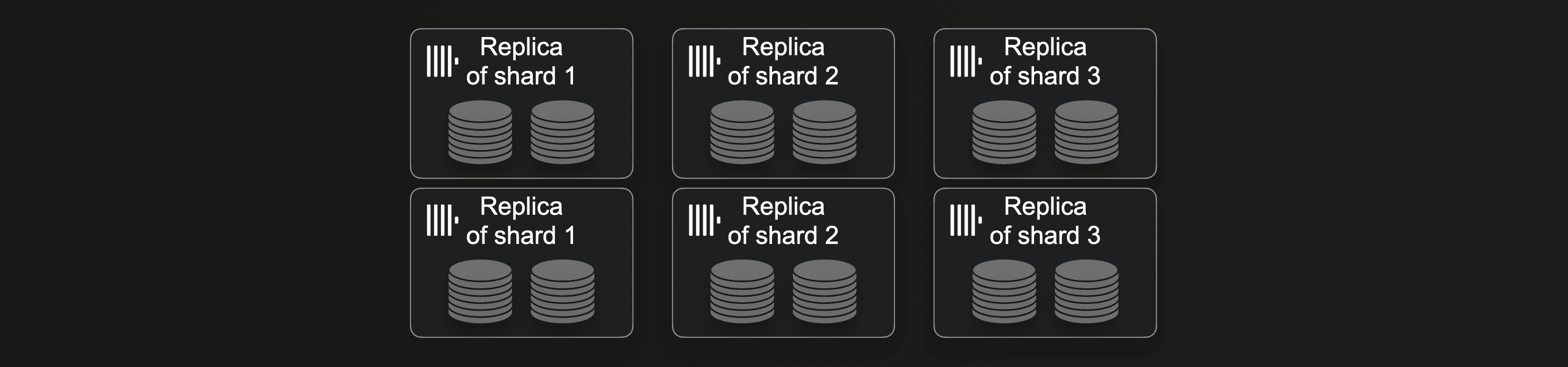 Then doubling the number of shards requires resharding and rebalancing of the currently stored data:
Then doubling the number of shards requires resharding and rebalancing of the currently stored data:

Automatic stronger durability for insert queries
With the ReplicatedMergeTree, you can use the insert_quorum setting for ensuring data durability. You can configure that an insert query only returns to the sender when the query’s data (meta-data in case of zero-copy replication) is stored on a specific number of replicas. For the SharedMergeTree, insert_quorum is not needed. As shown above, when an insert query successfully returns to the sender, then the query’s data is stored in highly available object storage, and the metadata is stored centrally in Keeper (which has a highly available setup of at least 3 Keeper servers).
More lightweight strong consistency for select queries
If your use case requires consistency guarantees that each server is delivering the same query result, then you can run the SYNC REPLICA system statement, which is a much more lightweight operation with the SharedMergeTree. Instead of syncing data (or metadata with zero-copy replication) between servers, each server just needs to fetch the current version of metadata from Keeper.
Improved throughput and scalability of background merges and mutations
With the SharedMergeTree, there is no performance degradation with higher amounts of servers. The throughput of background merges scales with the number of servers as long as Keeper has enough resources. The same is true for mutations which are implemented via explicitly triggered and (by default) asynchronously executed merges.
This has positive implications for other new features in ClickHouse, like lightweight updates, which get a performance boost from the SharedMergeTree. Similarly, engine-specific data transformations (aggregations for AggregatingMergeTree, deduplication for ReplacingMergeTree, etc.) benefit from the better merge throughput of the SharedMergeTree. These transformations are incrementally applied during background part merges. To ensure correct query results with potentially unmerged parts, users need to merge the unmerged data at query time by utilising the FINAL modifier or using explicit GROUP BY clauses with aggregations. In both cases, the execution speed of these queries benefits from better merge throughput. Because then the queries have less query-time data merge work to do.
The new ClickHouse Cloud default table engine
The SharedMergeTree table engine is now generally available as the default table engine in ClickHouse Cloud for new Development tier services. Please reach out to us if you would like to create a new Production tier service with the SharedMergeTree table engine.
All table engines from the MergeTree family that are supported by ClickHouse Cloud are automatically based on the SharedMergeTree. For example, when you create a ReplacingMergeTree table, ClickHouse Cloud will automatically create a SharedReplacingMergeTree table under the hood:
CREATE TABLE T (id UInt64, v String)
ENGINE = ReplacingMergeTree
ORDER BY (id);
SELECT engine
FROM system.tables
WHERE name = 'T';
┌─engine───────────────────┐
│ SharedReplacingMergeTree │
└──────────────────────────┘
Note that existing services will be migrated from ReplicatedMergeTree to the SharedMergeTree engine overtime. Please reach out to the ClickHouse Support team if you'd like to discuss this.
Also note that the current implementation of SharedMergeTree does not yet have support for more advanced capabilities present in ReplicatedMergeTree, such as deduplication of async inserts and encryption at rest, but this support is planned for future versions.
SharedMergeTree in action
In this section, we are going to demonstrate the seamless ingest performance scaling capabilities of the SharedMergeTree. We will explore the performance scaling of SELECT queries in another blog.
Ingest scenarios
For our example, we load the first six months of 2022 from the WikiStat data set hosted in an S3 bucket into a table in ClickHouse Cloud. For this, ClickHouse needs to load ~26 billion records from ~4300 compressed files (one file represents one specific hour of one specific day). We are using the s3Cluster table function in conjunction with the parallel_distributed_insert_select setting to utilize all of the cluster’s compute nodes. We are using four configurations, each with a different number of nodes. Each node has 30 CPU cores and 120 GB RAM:
- 3 nodes
- 10 nodes
- 20 nodes
- 80 nodes
Note that the first two cluster configurations both use a dedicated 3-node ClickHouse Keeper service, with 3 CPU cores and 2 GB RAM per node. For the 20-node and 80-node configurations, we increased the size of Keeper to 6 CPU cores and 6 GB RAM per node. We monitored Keeper during the data loading runs to ensure that Keeper resources were not a bottleneck.
Results
The more nodes we use in parallel, the faster (hopefully) the data is loaded, but also, the more parts get created per time unit. To achieve maximum performance of SELECT queries, it is necessary to minimize the number of parts processed. For that, each ClickHouse MergeTree family table engine is, in the background, continuously merging data parts into larger parts. The default healthy amount of parts (per table partition) of a table is 3000 (and used to be 300).
Therefore we are measuring for each data load run the time it took (from the start of each data load) for the engine to merge the parts created during ingest to a healthy number of less than 3000 parts. For that, we use a SQL query over a ClickHouse system table to introspect (and visualize) the changes over time in the number of active parts.
Note that we optionally also include numbers for the data ingest runs with the ReplicatedMergeTree engine with zero-copy replication. As mentioned above, this engine was not designed to support a high number of replica servers, we want to highlight that here.
This chart shows the time (in seconds) it took to merge all parts to a healthy amount of less than 3000 parts:
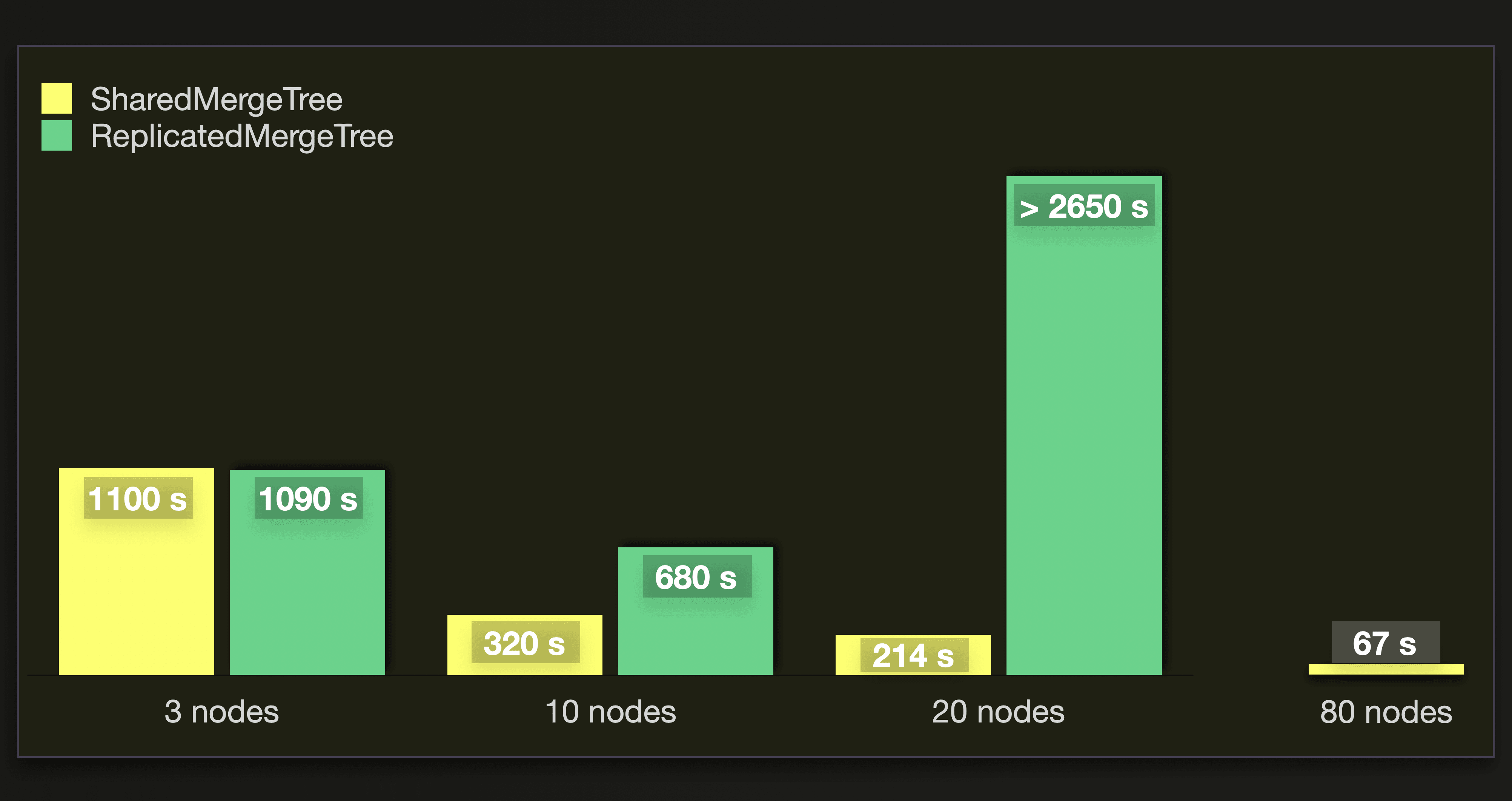 The SharedMergeTree supports seamless cluster scaling. We can see that the throughput of background merges scales quite linearly with the number of nodes in our test runs. When we approximately triple the number of nodes from 3 to 10, then we also triple the throughput. And when we again increase the number of nodes by a factor of 2 to 20 nodes and then by a factor of 4 to 80 nodes, then the throughput is approximately doubled and quadrupled, respectively, as well. As expected, the ReplicatedMergeTree with zero-copy replication doesn’t scale as well (or even decreases ingest performance with larger cluster sizes) as the SharedMergeTree with an increasing amount of replica nodes. Because its replication mechanics were never designed to work with a large number of replicas.
The SharedMergeTree supports seamless cluster scaling. We can see that the throughput of background merges scales quite linearly with the number of nodes in our test runs. When we approximately triple the number of nodes from 3 to 10, then we also triple the throughput. And when we again increase the number of nodes by a factor of 2 to 20 nodes and then by a factor of 4 to 80 nodes, then the throughput is approximately doubled and quadrupled, respectively, as well. As expected, the ReplicatedMergeTree with zero-copy replication doesn’t scale as well (or even decreases ingest performance with larger cluster sizes) as the SharedMergeTree with an increasing amount of replica nodes. Because its replication mechanics were never designed to work with a large number of replicas.
For completeness, this chart shows the time to merge until less than 300 parts remain:
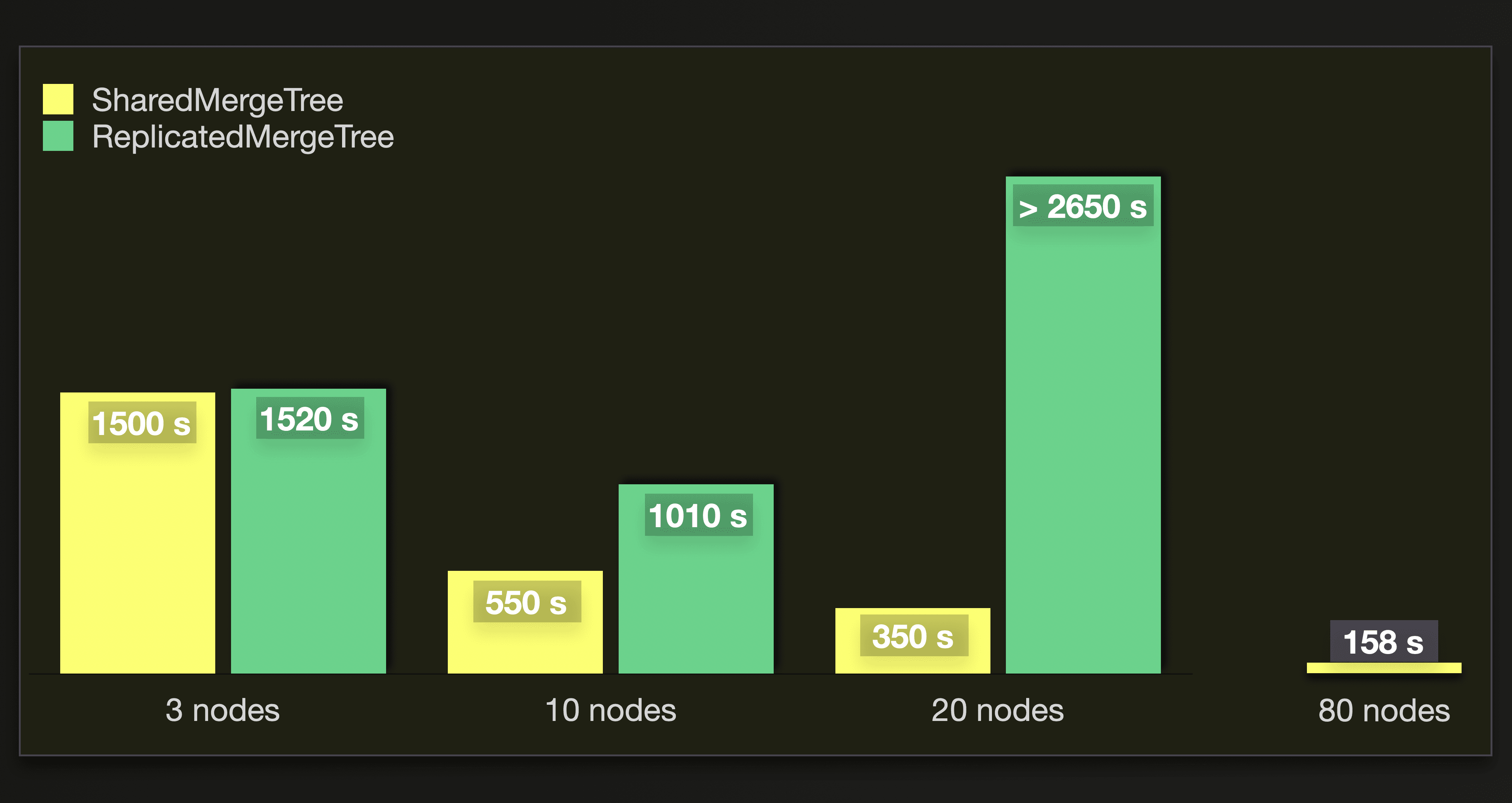
Detailed results
3 nodes
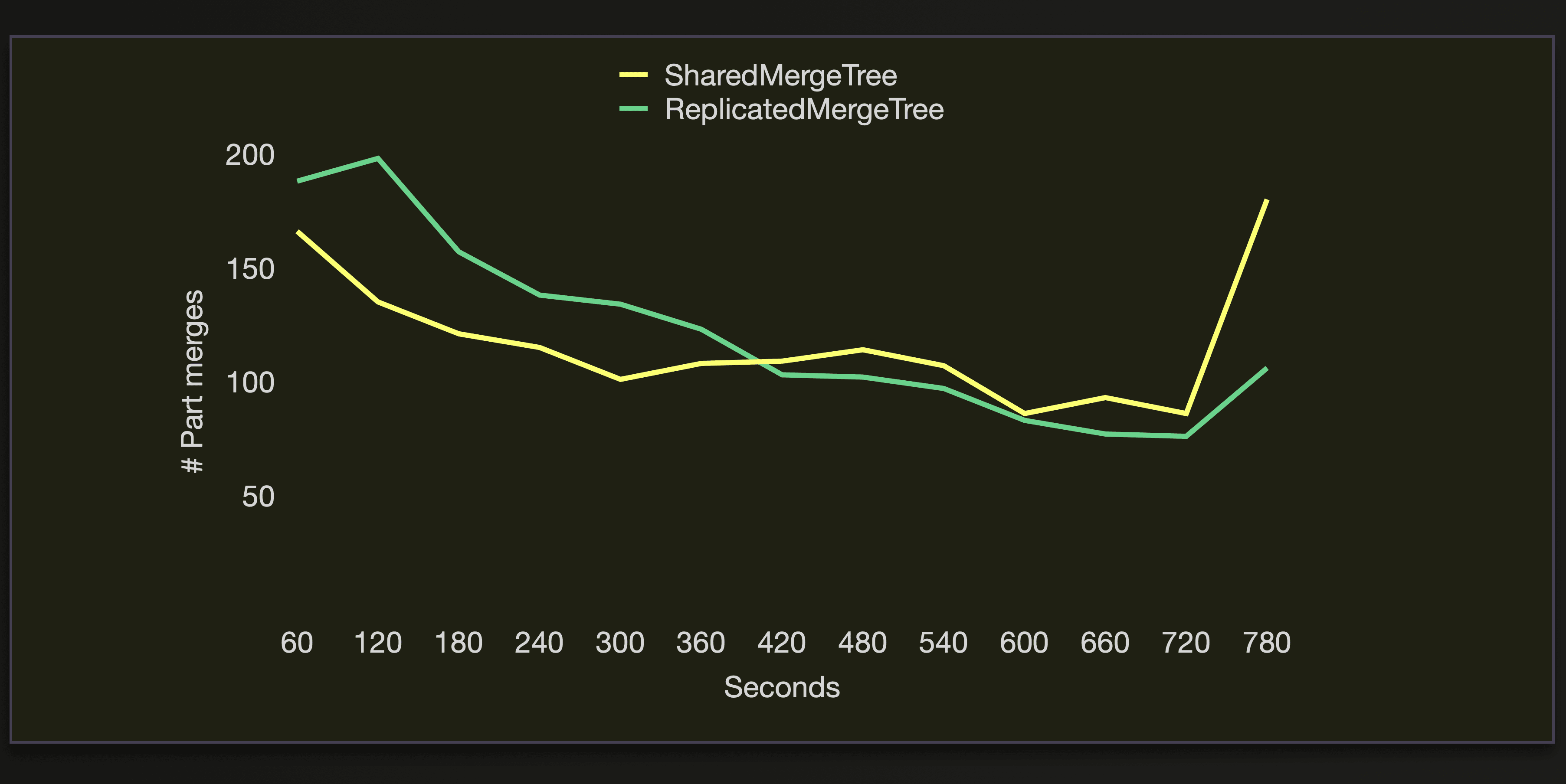
The following chart visualizes the number of active parts, the number of seconds it took to successfully load the data (see the Ingest finished marks), and the amount of seconds it took to merge the parts to less than 3000, and 300 active parts during the benchmark runs on the cluster with 3 replica nodes:
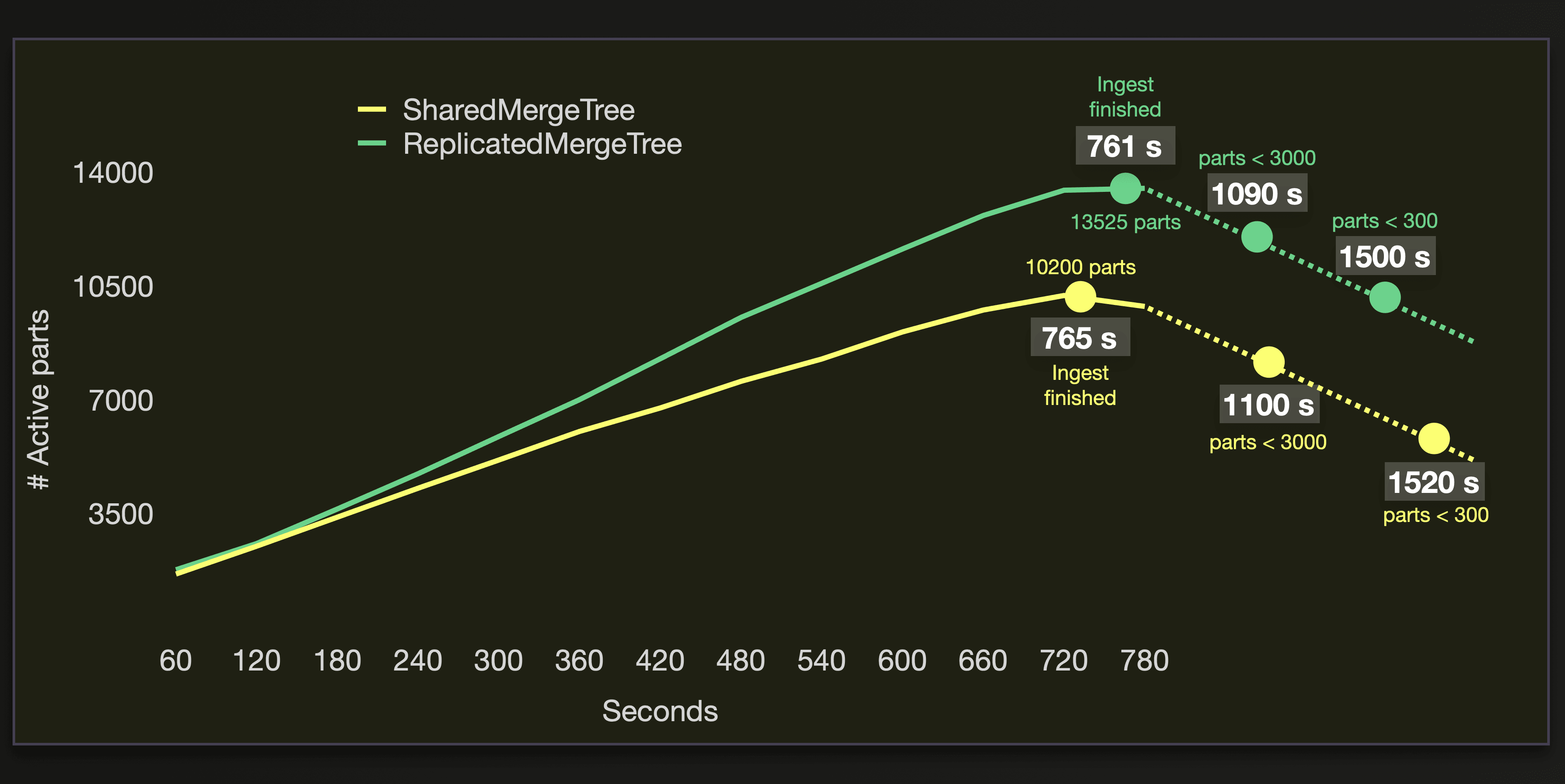 We see that the performance of both tables engines is very similar here.
We see that the performance of both tables engines is very similar here.
We can see that both engines execute approximately the same number of merge operations during the data loading:
10 nodes
On our cluster with 10 replica nodes, we can see a difference:
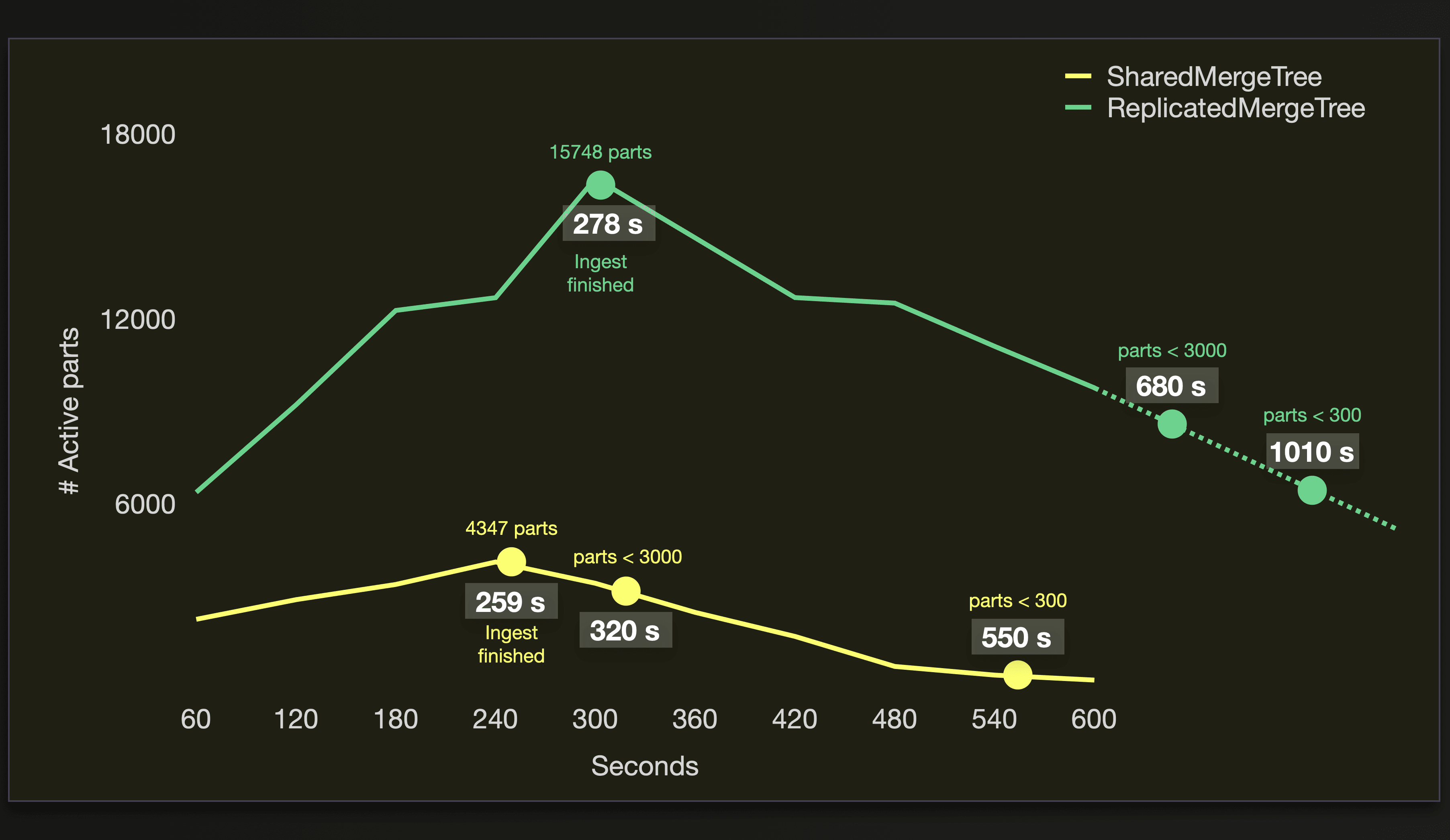 The difference in ingest time is just 19 seconds. The amount of active parts, when the ingest is finished, is very different for both table engines, though. For the ReplicatedMergeTree with zero-copy replication, the amount is more than three times higher. And it takes twice as much time to merge the parts to an amount of less than 3000 and 300 with the ReplicatedMergeTree. Meaning that we get faster query performance sooner with the SharedMergeTree. The amount of ~4 thousand active parts when the ingest is finished is still ok to query. Whereas ~15 thousand is infeasible.
The difference in ingest time is just 19 seconds. The amount of active parts, when the ingest is finished, is very different for both table engines, though. For the ReplicatedMergeTree with zero-copy replication, the amount is more than three times higher. And it takes twice as much time to merge the parts to an amount of less than 3000 and 300 with the ReplicatedMergeTree. Meaning that we get faster query performance sooner with the SharedMergeTree. The amount of ~4 thousand active parts when the ingest is finished is still ok to query. Whereas ~15 thousand is infeasible.
Both engines create the same amount of ~23 thousand initial parts with a size of ~10 MB containing ~ 1 million rows for ingesting the ~26 billion rows from the WikiStat data subset:
WITH
'default' AS db_name,
'wikistat' AS table_name,
(
SELECT uuid
FROM system.tables
WHERE (database = db_name) AND (name = table_name)
) AS table_id
SELECT
formatReadableQuantity(countIf(event_type = 'NewPart')) AS parts,
formatReadableQuantity(avgIf(rows, event_type = 'NewPart')) AS rows_avg,
formatReadableSize(avgIf(size_in_bytes, event_type = 'NewPart')) AS size_in_bytes_avg,
formatReadableQuantity(sumIf(rows, event_type = 'NewPart')) AS rows_total
FROM clusterAllReplicas(default, system.part_log)
WHERE table_uuid = table_id;
┌─parts──────────┬─rows_avg─────┬─size_in_bytes_avg─┬─rows_total────┐
│ 23.70 thousand │ 1.11 million │ 9.86 MiB │ 26.23 billion │
└────────────────┴──────────────┴───────────────────┴───────────────┘
And the creation of the ~23 thousand initial parts is evenly distributed over the 10 replica nodes:
WITH
'default' AS db_name,
'wikistat' AS table_name,
(
SELECT uuid
FROM system.tables
WHERE (database = db_name) AND (name = table_name)
) AS table_id
SELECT
DENSE_RANK() OVER (ORDER BY hostName() ASC) AS node_id,
formatReadableQuantity(countIf(event_type = 'NewPart')) AS parts,
formatReadableQuantity(sumIf(rows, event_type = 'NewPart')) AS rows_total
FROM clusterAllReplicas(default, system.part_log)
WHERE table_uuid = table_id
GROUP BY hostName()
WITH TOTALS
ORDER BY node_id ASC;
┌─node_id─┬─parts─────────┬─rows_total───┐
│ 1 │ 2.44 thousand │ 2.69 billion │
│ 2 │ 2.49 thousand │ 2.75 billion │
│ 3 │ 2.34 thousand │ 2.59 billion │
│ 4 │ 2.41 thousand │ 2.66 billion │
│ 5 │ 2.30 thousand │ 2.55 billion │
│ 6 │ 2.31 thousand │ 2.55 billion │
│ 7 │ 2.42 thousand │ 2.68 billion │
│ 8 │ 2.28 thousand │ 2.52 billion │
│ 9 │ 2.30 thousand │ 2.54 billion │
│ 10 │ 2.42 thousand │ 2.68 billion │
└─────────┴───────────────┴──────────────┘
Totals:
┌─node_id─┬─parts──────────┬─rows_total────┐
│ 1 │ 23.71 thousand │ 26.23 billion │
└─────────┴────────────────┴───────────────┘
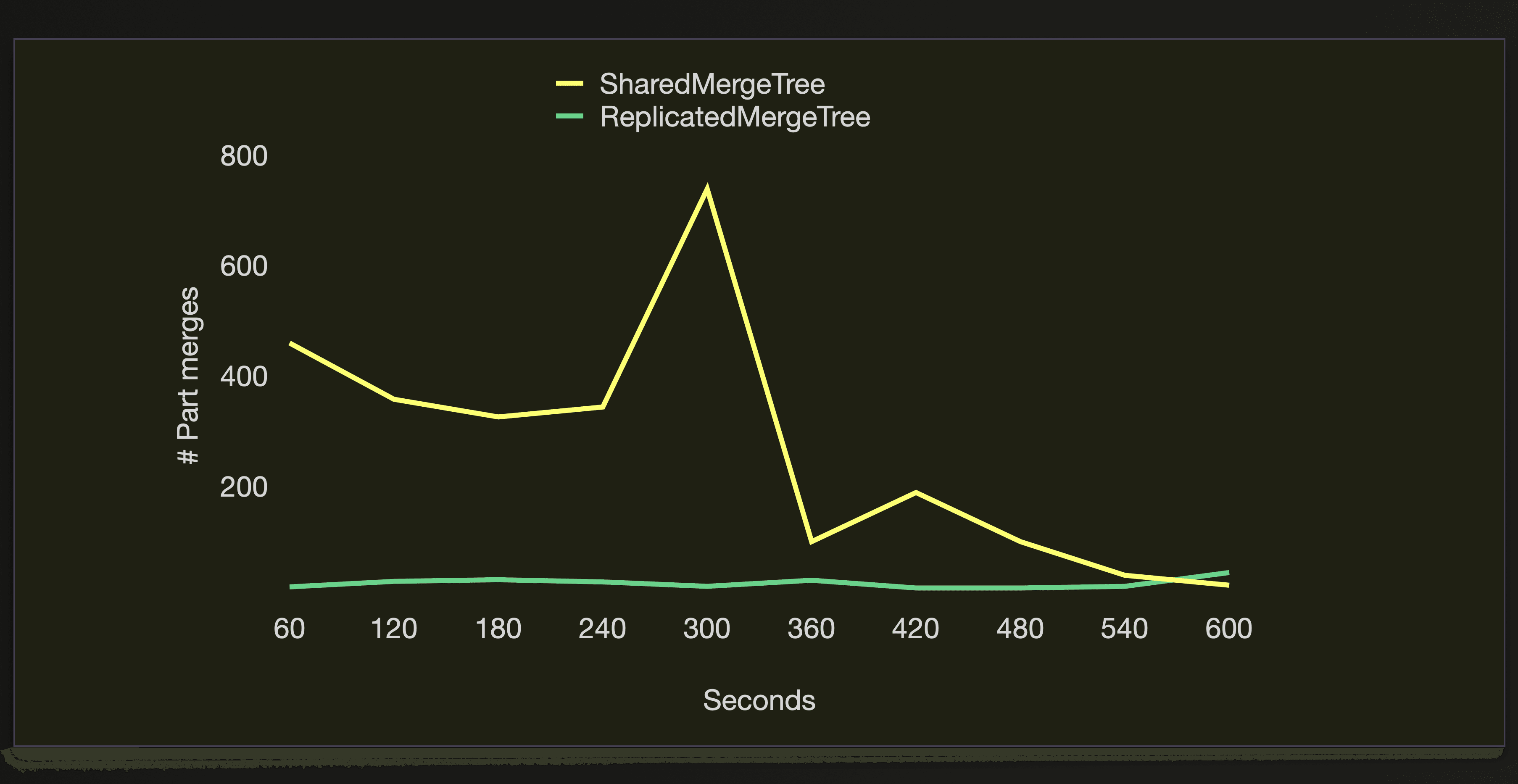
But the SharedMergeTree engine is merging the parts much more effectively during the data load run:
20 nodes
When 20 nodes are inserting the data in parallel, the ReplicatedMergeTree with zero-copy replication struggles to cope with the amount of newly created parts per time unit:
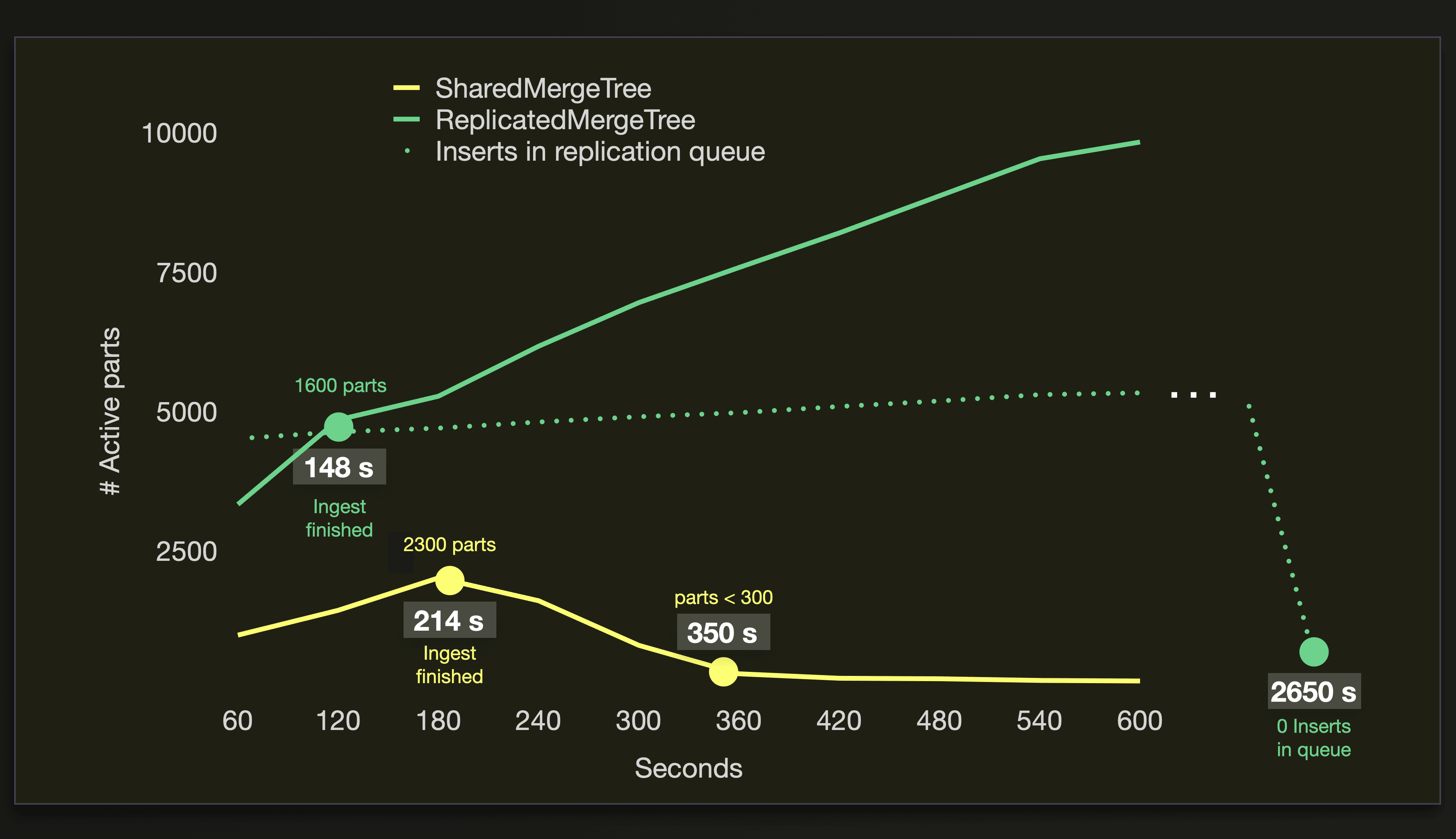 Although the ReplicatedMergeTree finishes the data ingestion process before the SharedMergeTree, the amount of active parts continues to increase to ~10 thousand parts. Because the engine still has insert operations in a queue that still need to be replicated across the 20 nodes. See the
Although the ReplicatedMergeTree finishes the data ingestion process before the SharedMergeTree, the amount of active parts continues to increase to ~10 thousand parts. Because the engine still has insert operations in a queue that still need to be replicated across the 20 nodes. See the Inserts in replication queue line whose values we got with this query. It took almost 45 minutes to process this queue. 20 nodes creating a high amount of newly created parts per time unit causes too much contention on the replication log and too high overhead on locks and inter-server communication. A way to mitigate this would be to throttle the amount of newly created parts by manually tuning some settings of the insert query. E.g., you can reduce the number of parallel insert threads per node and increase the number of rows written into each new part. Note that the latter increases main memory usage.
Note that Keeper hardware was not overloaded during the test runs. The following screenshots show the CPU and memory usage of Keeper for both table engines:
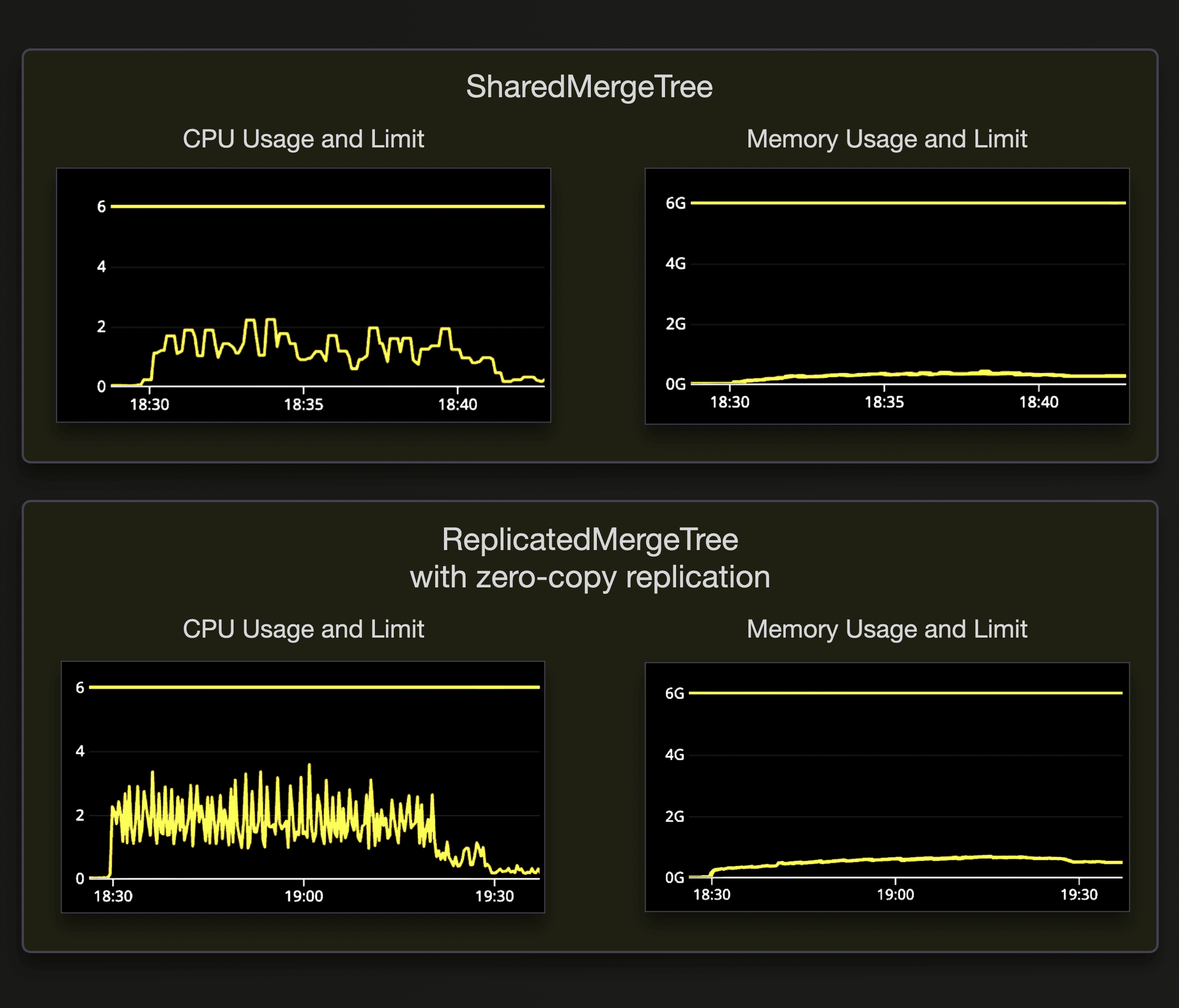
80 nodes
On our cluster with 80 nodes, we load the data only into a SharedMergeTree table. We already showed above that the ReplicatedMergeTree with zero-copy replication is not designed for higher replica node numbers.
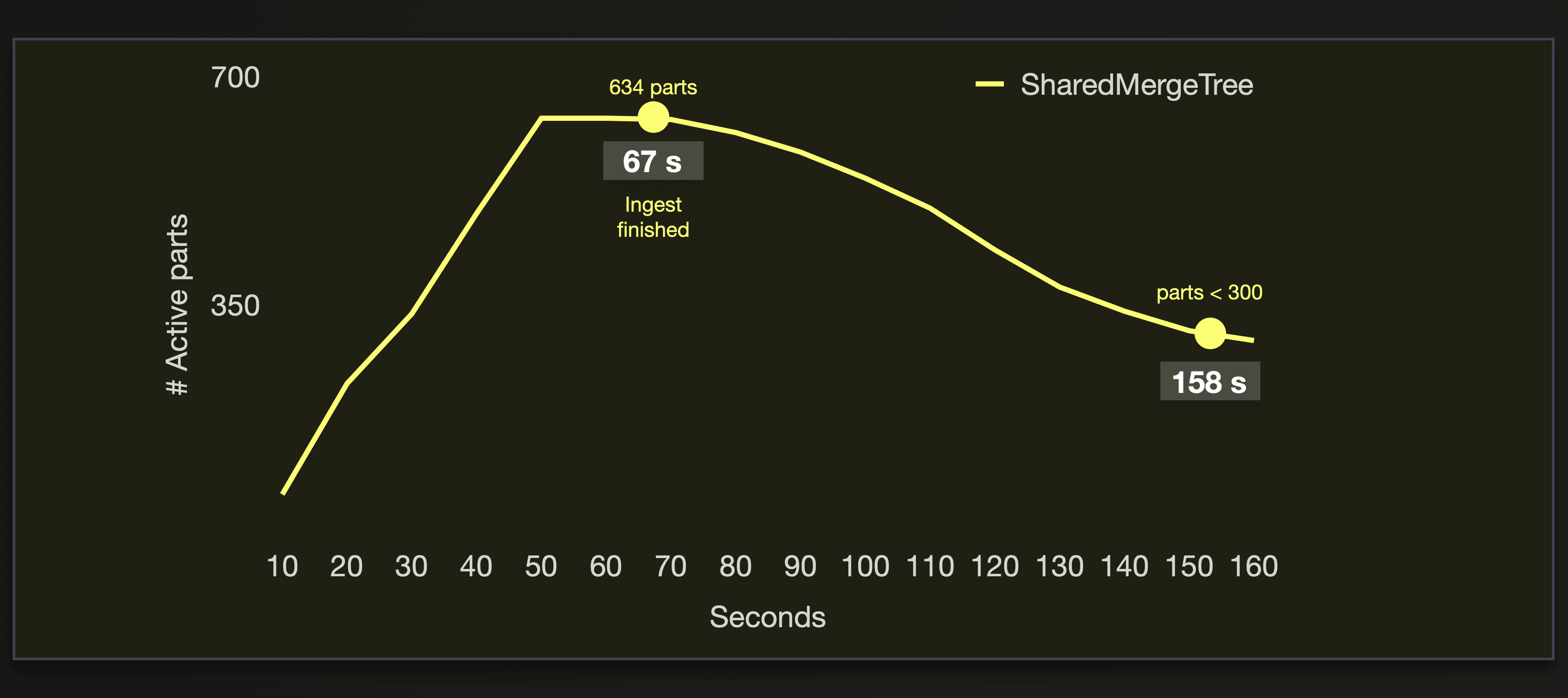
The insertion of 26 billion rows finished in 67 seconds, which gives 388 million rows/sec.
Introducing Lightweight Updates, boosted by SharedMergeTree
SharedMergeTree is a powerful building block that we see as a foundation of our cloud-native service. It allows us to build new capabilities and improve existing ones when it was not possible or too complex to implement before. Many features benefit from working on top of SharedMergeTree and make ClickHouse Cloud more performant, durable, and easy to use. One of these features is “Lightweight Updates” – an optimization that allows to instantly make results of ALTER UPDATE queries available while using fewer resources.
Updates in traditional analytical databases are heavy operations
ALTER TABLE … UPDATE queries in ClickHouse are implemented as mutations. A mutation is a heavyweight operation that rewrites parts, either synchronously or asynchronously.
Synchronous mutations
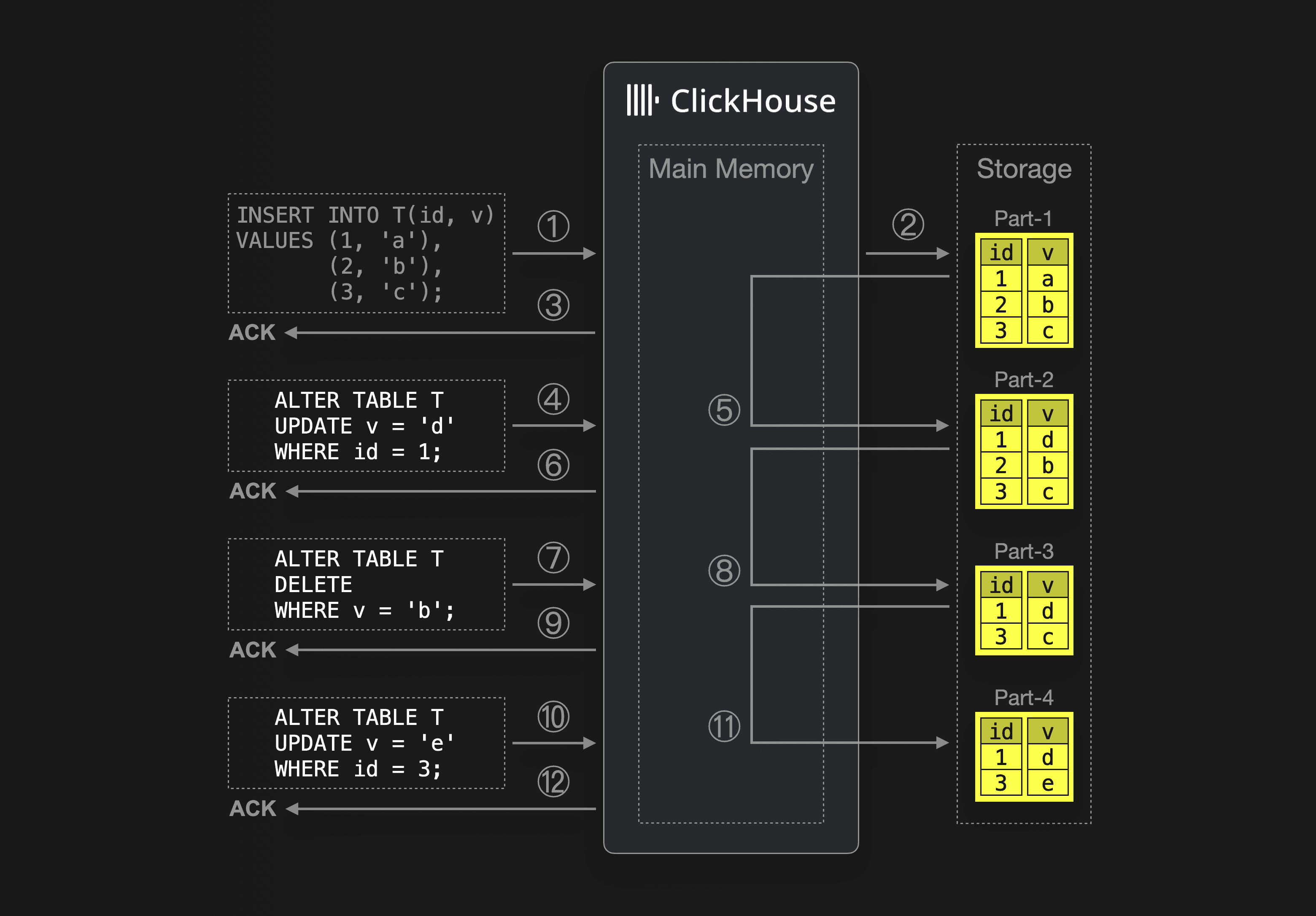 In our example scenario above, ClickHouse ① receives an insert query for an initially empty table, ② writes the query’s data into a new data part on storage, and ③ acknowledges the insert. Next, ClickHouse ④ receives an update query and executes that query by ⑤ mutating Part-1. The part is loaded into the main memory, the modifications are done, and the modified data is written to a new Part-2 on storage (Part-1 is deleted). Only when that part rewrite is finished, ⑥ the acknowledgment for the update query is returned to the sender of the update query. Additional update queries (which can also delete data) are executed in the same way. For larger parts, this is a very heavy operation.
In our example scenario above, ClickHouse ① receives an insert query for an initially empty table, ② writes the query’s data into a new data part on storage, and ③ acknowledges the insert. Next, ClickHouse ④ receives an update query and executes that query by ⑤ mutating Part-1. The part is loaded into the main memory, the modifications are done, and the modified data is written to a new Part-2 on storage (Part-1 is deleted). Only when that part rewrite is finished, ⑥ the acknowledgment for the update query is returned to the sender of the update query. Additional update queries (which can also delete data) are executed in the same way. For larger parts, this is a very heavy operation.
Asynchronous mutations
By default, update queries are executed asynchronously in order to fuse several received updates into a single mutation for mitigating the performance impact of rewriting parts:
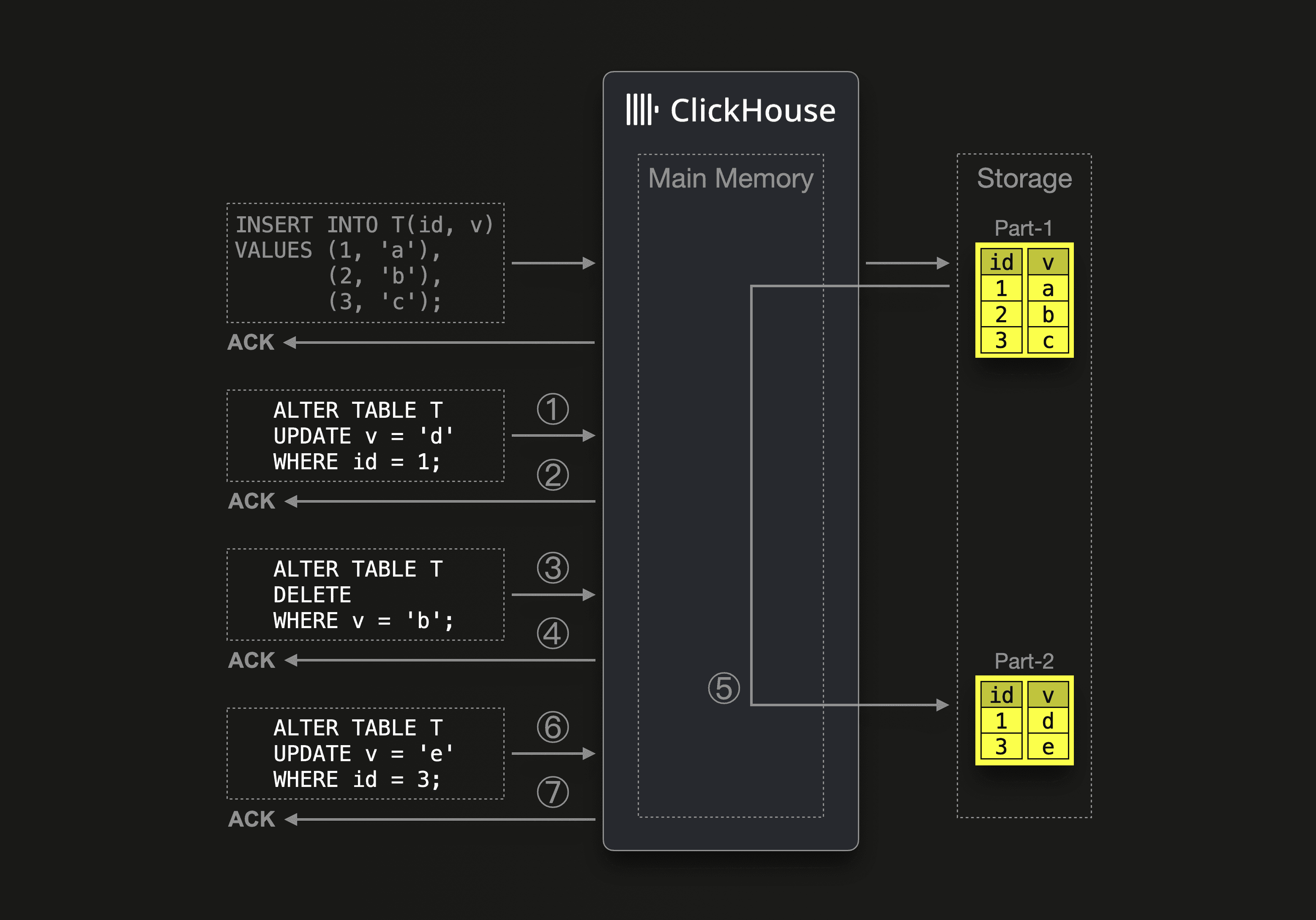 When ClickHouse ① receives an update query, then the update is added to a queue and executed asynchronously, and ② the update query immediately gets an acknowledgment for the update.
When ClickHouse ① receives an update query, then the update is added to a queue and executed asynchronously, and ② the update query immediately gets an acknowledgment for the update.
Note that SELECT queries to the table don’t see the update before it ⑤ gets materialized with a background mutation.
Also, note that ClickHouse can fuse queued updates into a single part rewrite operation. For this reason, it is a best practice to batch updates and send 100s of updates with a single query.
Lightweight updates
The aforementioned explicit batching of update queries is no longer necessary, and from the user's perspective, modifications from single update queries, even when being materialized asynchronously, will occur instantly.
This diagram sketches the new lightweight and instant update mechanism in ClickHouse:
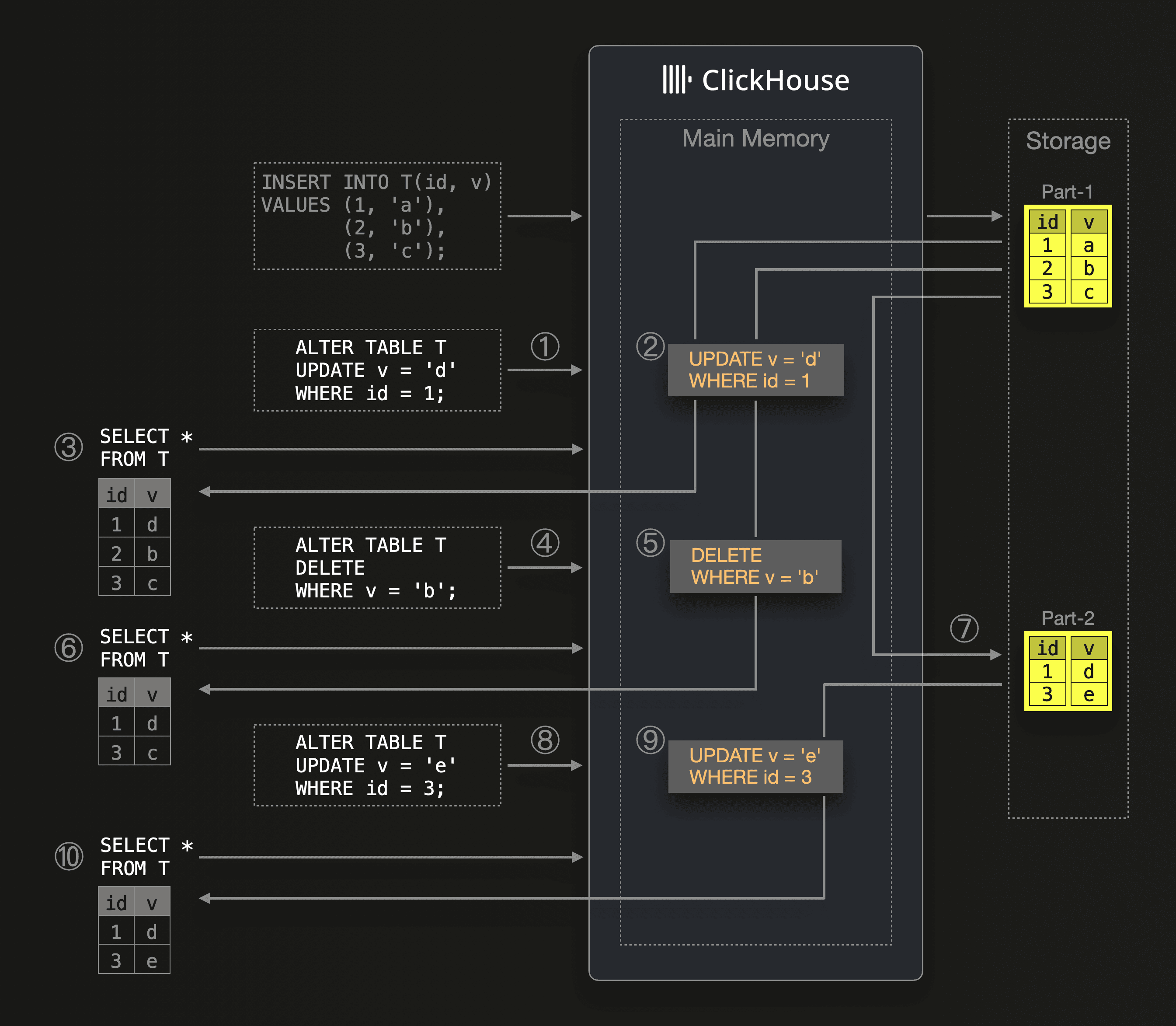 When ClickHouse ① receives an update query, then the update is added to a queue and executed asynchronously. ② Additionally, the update query’s update expression is put into the main memory. The update expression is also stored in Keeper and distributed to other servers. When ③ ClickHouse receives a SELECT query before the update is materialized with a part rewrite, then ClickHouse will execute the SELECT query as usual - use the primary index for reducing the set of rows that need to be streamed from the part into memory, and then the update expression from ② is applied to the streamed rows on the fly. That is why we call this mechanism
When ClickHouse ① receives an update query, then the update is added to a queue and executed asynchronously. ② Additionally, the update query’s update expression is put into the main memory. The update expression is also stored in Keeper and distributed to other servers. When ③ ClickHouse receives a SELECT query before the update is materialized with a part rewrite, then ClickHouse will execute the SELECT query as usual - use the primary index for reducing the set of rows that need to be streamed from the part into memory, and then the update expression from ② is applied to the streamed rows on the fly. That is why we call this mechanism on [the] fly mutations. When ④ another update query is received by ClickHouse, then ⑤ the query’s update (in this case a delete) expression is again kept in main memory, and ⑥ a succeeding SELECT query will be executed by applying both (②, and ⑤) update expressions on the fly to the rows streamed into memory. The on-the-fly update expressions are removed from memory when ⑦ all queued updates are materialized with the next background mutation. ⑧ Newly received updates and ⑩ SELECT queries are executed as described above.
This new mechanism can be enabled by simply setting the apply_mutations_on_fly setting to 1.
Benefits
Users don’t need to wait for mutations to materialize. ClickHouse delivers updated results immediately, while using less resources. Furthermore, this makes updates easier to use for ClickHouse users, who can send updates without having to think about how to batch them.
Synergy with the SharedMergeTree
From the user's perspective, modifications from lightweight updates will occur instantly, but users will experience slightly reduced SELECT query performance until updates are materialized because the updates are executed at query time in memory on the streamed rows. As updates are materialized as part of merge operations in the background, the impact on query latency goes away. The SharedMergeTree table engine comes with improved throughput and scalability of background merges and mutations, and as a result, mutations complete faster, and SELECT queries after lightweight updates return to full speed sooner.
What’s next
The mechanics of lightweight updates that we described above are just the first step. We are already planning additional phases of implementation to improve the performance of lightweight updates further and eliminate current limitations.
Summary
In this blog post, we have explored the mechanics of the new ClickHouse Cloud SharedMergeTree table engine. We explained why it was necessary to introduce a new table engine natively supporting the ClickHouse Cloud architecture, where vertically and horizontally scalable compute nodes are separated from the data stored in virtually limitless shared object storage. The SharedMergeTree enables seamless and virtually limitless scaling of the compute layer on top of the storage. The throughput of inserts and background merges can be easily scaled, which benefits other features in ClickHouse, such as lightweight updates and engine-specific data transformations. Additionally, the SharedMergeTree provides stronger durability for inserts and more lightweight strong consistency for select queries. Finally, it opens the door to new cloud-native capabilities and improvements. We demonstrated the engine’s efficiency with a benchmark and described a new feature boosted by the SharedMergeTree, called Lightweight Updates.
We are looking forward to seeing this new default table engine in action to boost the performance of your ClickHouse Cloud use cases.


