
Welcome, chDB.
At ClickHouse, we often speak about community and open-source. Embedded in this conversation is the belief that sometimes the coolest and most exciting ideas come from our community. For this reason, we have started to highlight some of the amazing things the community is creating on our monthly ClickHouse Community call.
This month, we had the opportunity to highlight chDB.
Developed by ClickHouse community contributors Auxten and Lorenzo Mangani, with the help of the community, chDB is an embedded SQL OLAP Engine powered by ClickHouse. More simply, this makes the ClickHouse engine available as an “out-of-the-box” Python module, allowing users to exploit the full power and performance of ClickHouse directly in their code.
This model of database interaction has shown to be increasingly popular amongst data scientists and data engineers, with projects such as DuckDB gaining popularity in recent years. While ClickHouse is a fully-fledged OLAP database for real-time analytics, capable of being run in a multi-node architecture hosting petabytes of data and still providing sub-second query response times, we’re also aware that a lot of analytics is performed on user laptops and workstations - especially for smaller datasets. These data interactions are typical in many project stages, whether it be early data exploration, one-off ETL tasks, development, and testing, or simple questions on smaller datasets that require SQL but don’t require the horsepower of a server. With Python, often the language of choice for these tasks, chDB provides a first-class integration and allows users to exploit ClickHouse from within their code.
Why Embed ClickHouse?
For some time, ClickHouse has provided clickhouse-local. This offers a single locally executable binary from which users can query local and remote files (e.g., in S3) with the full functionality of ClickHouse. Providing both a full client console and a means of passing queries and responses through stdout for integration into scripts, clickhouse-local addresses the common ad hoc data tasks described above and avoids the need for users to deploy a full server. We continue to invest in clickhouse-local, which benefits from the same core code as the server, with it particularly benefiting recent improvements such as faster Parquet querying.
While clickhouse-local has proved immensely popular and especially powerful when a simple SQL query is sufficient, we also understand that Python is ubiquitous and often the tool of choice for data tasks. For example, users often need to integrate SQL into their wider logic - especially with Python as the most popular means of training and invoking Machine Learning models. chDB addresses this very problem, allowing users to use ClickHouse with standard data manipulation and analysis libraries such as Pandas.
One of the first things which caught our attention is how chDB had addressed the challenge of providing ClickHouse as a Python module: the how was just as important to us as the why. A naive implementation might directly include the clickhouse-local binary in the Python package and pass queries and responses through stdin and stdout via something like popen. This piped approach, while maybe simple and sufficient for a one-off script, has several disadvantages, such as:
- Starting an independent process for each query would slightly impact performance, adding around 10..50 milliseconds for the query time.
- Multiple copies of SQL query results are inevitable.
- Integration with Python is limited, making it difficult to implement Python UDFs and support SQL on Pandas DataFrame.
Most important to the team, it lacked elegance ????
The team had spent considerable time (and his Lunar New Year) implementing a robust and performant integration. Rather than rely on pipes, chDB tightly integrates with ClickHouse’s read and write buffers to exchange queries and results via MemoryView. This addresses the above challenges, ensuring a single process of ClickHouse can be used within the code as well as avoiding expensive memory copies and inherently supporting parallel pipelines without blocking.
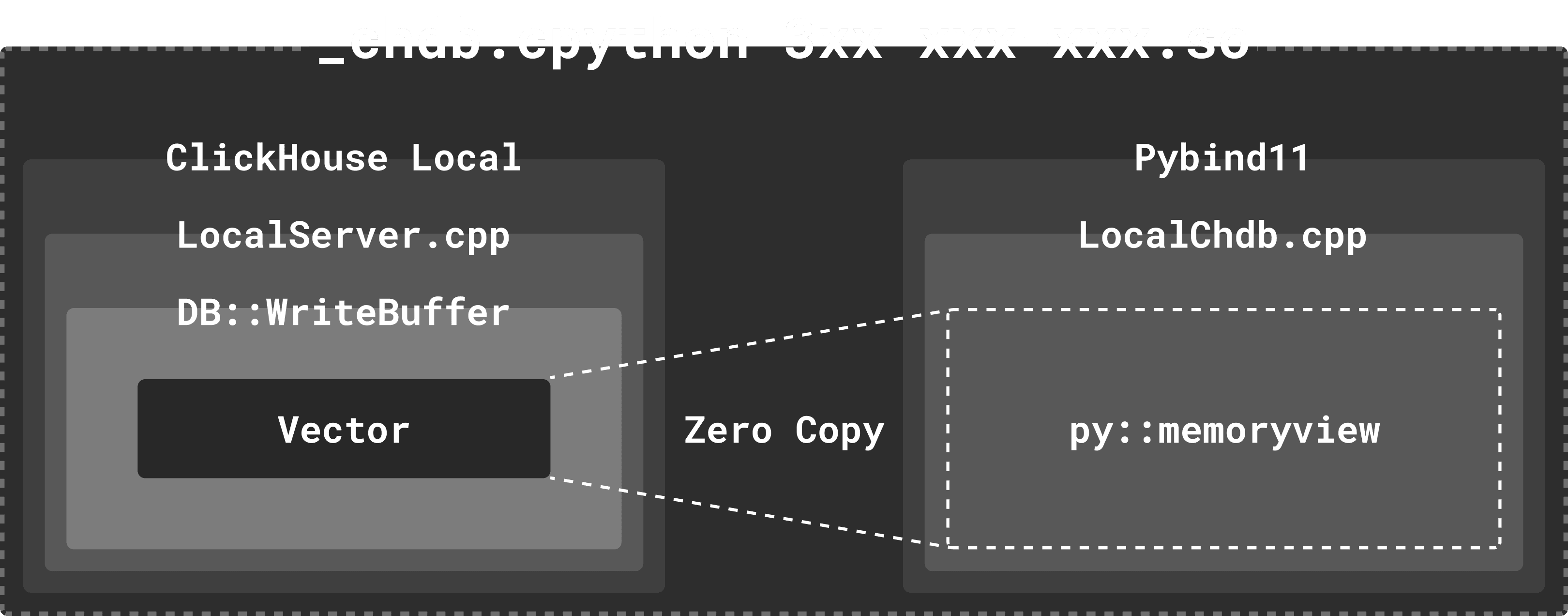
For those interested, we intend to follow up this blog with a deeper guest blog that dives into the implementation and some of the challenges auxen and Lorenzo faced. Alternatively, if you can’t wait for the details, just visit the open-source repo!
A few quick examples
Using chDB in your Python code is straightforward. Like any other python module, a quick pip install gets you started.
pip install chdb
One of the popular features of ClickHouse is the ability to query a huge range of file formats hosted in object stores such as S3. Below, we use the s3 table function to query the popular UK property prices dataset represented as a set of Parquet files. Note that we aren’t required to specify the structure of the file or its format - ClickHouse’s schema inference handles this automatically.
Note: We ask explicitly for the column headers in the response with the format CSVWithNames - the default of CSV, omits these.
import chdb
data = chdb.query("SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices_2*.parquet') LIMIT 5","CSVWithNames")
print(data)
"price","date","postcode1","postcode2","type","is_new","duration","addr1","addr2","street","locality","town","district","county"
62000,9339,"SS6","8PN",2,0,1,"50","","CHURCH ROAD","RAYLEIGH","RAYLEIGH","ROCHFORD","ESSEX"
53500,9400,"SS6","8PW",2,0,1,"10","","LODGE CLOSE","RAYLEIGH","RAYLEIGH","ROCHFORD","ESSEX"
55950,9430,"SS6","8PX",2,0,1,"56","","GROVE ROAD","RAYLEIGH","RAYLEIGH","ROCHFORD","ESSEX"
50000,9198,"SS6","8PX",2,0,1,"58","","GROVE ROAD","RAYLEIGH","RAYLEIGH","ROCHFORD","ESSEX"
109995,9152,"SS6","8PY",3,1,1,"18","","THE RAMPARTS","RAYLEIGH","RAYLEIGH","ROCHFORD","ESSEX"
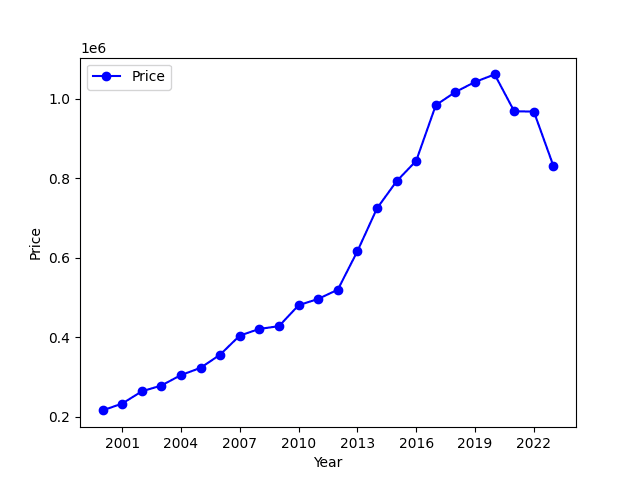
The Pandas library is almost ubiquitous for data manipulation and analysis in Python, with the data frame as the principal means of efficiently representing tabular data. Exploiting chDB’s integration with this library is straightforward. Below, we perform a simple aggregation to compute average house prices in London per year from 2000.
pip install pyarrow pandas matplotlib
import chdb
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator
df = chdb.query("SELECT toYear(date::Date32) AS year, round(avg(price)) AS price "
"FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices_20*.parquet') WHERE town = 'LONDON' GROUP BY year ORDER BY year","Dataframe")
df['year'] = df['year'].astype(int)
plt.plot(df['year'], df['price'], marker='o', linestyle='-', color='b', label='Price')
plt.xlabel('Year')
plt.ylabel('Price')
plt.legend()
plt.gca().xaxis.set_major_locator(MaxNLocator(integer=True))
plt.show(block=True)
Users can also use chDB for querying existing tabular structures such as Pandas data frames, allowing code to be simplified and accelerated with ClickHouse SQL. In the example below we populate a dataframe with some dummy date, before repeating the above query. Note the __table__ syntax used in the query.
import chdb.dataframe as cdf
from datetime import datetime, timedelta
import pandas as pd
import random
# Populate the DataFrame with random house sales data
data = []
start_date = datetime(2010, 1, 1)
end_date = datetime(2023, 12, 31)
for _ in range(10000):
date = start_date + timedelta(days=random.randint(0, (end_date - start_date).days)) # Random date
price = random.randint(100000, 1000000) # Random price between 100000 and 1000000
data.append({'date': date, 'price': price})
df = pd.DataFrame(data)
tbl = cdf.Table(dataframe=df)
df = tbl.query('SELECT toYear(date::Date32) AS year, round(avg(price)) AS price FROM __table__ GROUP BY year ORDER BY year')
print(df)
year price
0 2010 562323.0
1 2011 557704.0
2 2012 556884.0
3 2013 553141.0
4 2014 550012.0
5 2015 555865.0
6 2016 560128.0
7 2017 558746.0
8 2018 560938.0
9 2019 559185.0
10 2020 565041.0
11 2021 535593.0
12 2022 540023.0
13 2023 543916.0
Finally, users can also query and return data in any of the many formats supported by ClickHouse. Below we query a gzip CSV sample of the UK house price dataset, returning the result in Arrow.
import chdb
res = chdb.query(
f"SELECT town, district, count() AS c, round(avg(price)) AS price "
f"FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/csv/house_prices.csv.gz') "
f"GROUP BY town, district HAVING c >= 100 ORDER BY price DESC LIMIT 10",
"ArrowTable")
print(res)
pyarrow.Table
town: binary
district: binary
c: uint64 not null
price: double
----
town: [[4C4F4E444F4E,4C4F4E444F4E,4C4F4E444F4E,56495247494E4941205741544552,4C45415448455248454144,4C4F4E444F4E,4E4F525448574F4F44,57494E44534F52,57494E444C455348414D,434F4248414D]]
district: [[43495459204F46204C4F4E444F4E,43495459204F4620574553544D494E53544552,4B454E53494E47544F4E20414E44204348454C534541,52554E4E594D454445,454C4D425249444745,43414D44454E,544852454520524956455253,425241434B4E454C4C20464F52455354,535552524559204845415448,454C4D425249444745]]
c: [[729,9605,6549,379,262,7399,150,111,232,925]]
price: [[3212987,2888615,2447372,2115944,2085028,1619476,1493810,1360590,1323741,1307596]]
For more examples, see the chDB repository, where the authors provide solutions to common questions and tasks.
More than Python
While providing Python bindings was the initial focus of the project, chDB has quickly benefited from community interest and contributions. Bindings for Rust, NodeJS, and Golang are under active development! We’re excited to see this work and the potential applications they will unlock.
chDB has already opened the door to a few interesting possibilities. As well as making AWS lambda functions with ClickHouse simpler to write and deploy, a server version of chDB provides a stateless experience helpful in testing functions and performing fast data analysis without even needing to write a line of Python. Lorenzo has even demonstrated this running on fly.io using a simple recipe to provide a free SQL query engine for querying remote files.
The future
The pace of chDB’s development since its inception has been impressive. Recently adding sessions to Python bindings allows users to persist state across queries by creating tables where data can be inserted and queried. This brings the full power of the ClickHouse MergeTree and sparse indices to Python code and will hopefully unlock a new scale of local analytics!
The community plans to extend these sessions to other bindings, including support for User-Defined Functions (UDFs). As well as ensuring chDB is promptly updated to support the latest versions of ClickHouse, the team has even found time to recently add ARM64/AARCH64 support.
We look forward to seeing how chDB develops and would love to hear how you’ve already used it.
Finally, for users wishing to highlight their ClickHouse-based projects on our monthly community call, please reach out to [email protected].


