
This post continues our bite-sized series, where we highlight cool queries and share interesting tips and tricks related to ClickHouse.
Interested in trying UDFs in ClickHouse Cloud? Get started instantly with $300 free credit for 30 days.
Introduction
Today, we focus on a query from the analysis of the ClickHouse repository using the Git data captured by the git-import tool distributed with ClickHouse and presented in a previous post in this series. This query uses a powerful feature of ClickHouse: SQL User-defined functions, which we’ve recently made available in ClickHouse Cloud!
For this post, we’ll create a query that shows the entire commit history of a file in the ClickHouse repository. This query will utilize a UDF to allow for renames in the file. Our final solution is included in the documentation, and we welcome improvements.
All examples in this post can be reproduced in our play.clickhouse.com environment (see the git_clickhouse database). Alternatively, if you want to dive deeper into this dataset, ClickHouse Cloud is a great starting point and now supports UDFs - spin up a cluster using a free trial, load the data, let us deal with the infrastructure, and get querying!
A UDF Refresher
User-defined functions (UDF) allow users to extend the behavior of ClickHouse, by creating lambda expressions that can utilize SQL constructs and functions. These functions can then be used like any in-built function in a query.
To create our UDF, we use the CREATE FUNCTION <name> syntax and specify our method signature as a lambda expression. In it its simplest form, this might look like the following, which returns the string odd or even depending on the parity of the number:
CREATE FUNCTION parity_str AS (n) -> if(n % 2, 'odd', 'even'); SELECT number, parity_str(number) FROM numbers(5) ┌─number─┬─if(modulo(number, 2), 'odd', 'even')─┐ │ 0 │ even │ │ 1 │ odd │ │ 2 │ even │ │ 3 │ odd │ │ 4 │ even │ └────────┴──────────────────────────────────────┘✎
This is deliberately simple. As we’ll demonstrate, these can get considerably more complex.
The Problem
Our git-import generates data for several tables from the git commit history of a repository. One of these, file_changes, contains a row for every file changed in a commit. A commit that modifies more than one file will therefore generate multiple rows, allowing us to construct the history of a file with a simple SELECT statement. For example, below, we look at the recent commits to our ReplicatedMergeTree:
SELECT time, substring(commit_hash, 1, 11) AS commit, change_type, author, lines_added AS added, lines_deleted AS deleted FROM git.file_changes WHERE path = 'src/Storages/StorageReplicatedMergeTree.cpp' ORDER BY time DESC LIMIT 5 ┌────────────────time─┬─commit──────┬─change_type─┬─author─────────────┬─added─┬─deleted─┐ │ 2022-10-30 16:30:51 │ c68ab231f91 │ Modify │ Alexander Tokmakov │ 13 │ 10 │ │ 2022-10-23 16:24:20 │ b40d9200d20 │ Modify │ Anton Popov │ 28 │ 30 │ │ 2022-10-23 01:23:15 │ 56e5daba0c9 │ Modify │ Anton Popov │ 28 │ 44 │ │ 2022-10-21 13:35:37 │ 851f556d65a │ Modify │ Igor Nikonov │ 3 │ 2 │ │ 2022-10-21 13:02:52 │ 13d31eefbc3 │ Modify │ Igor Nikonov │ 4 │ 4 │ └─────────────────────┴─────────────┴─────────────┴────────────────────┴───────┴─────────┘ 5 rows in set. Elapsed: 0.011 sec. Processed 3.91 thousand rows, 704.14 KB (350.59 thousand rows/s., 63.19 MB/s.)✎
This approach works until a commit renames a file. A rename is denoted by the change_type having the value Rename. As shown below, the path column holds the new name of the file (also used in subsequent modification commits), while the original name is referenced in the old_path column for this row only.
SELECT time, substring(commit_hash, 1, 11) AS commit, change_type, path, old_path FROM git.file_changes WHERE path = 'src/Storages/StorageReplicatedMergeTree.cpp' ORDER BY time ASC LIMIT 2 FORMAT Vertical Row 1: ────── time: 2020-04-03 16:14:31 commit: 06446b4f08a change_type: Rename path: src/Storages/StorageReplicatedMergeTree.cpp old_path: dbms/Storages/StorageReplicatedMergeTree.cpp Row 2: ────── time: 2020-04-07 16:28:29 commit: 82a87bc0d2d change_type: Modify path: src/Storages/StorageReplicatedMergeTree.cpp old_path: 2 rows in set. Elapsed: 0.009 sec. Processed 122.88 thousand rows, 7.93 MB (13.46 million rows/s., 867.97 MB/s.)✎
While we could potentially modify our query to match the old_path and path fields as shown below, this will only allow for one rename. This problem might typically be solved by recursive CTEs, which are not supported in ClickHouse.
path = 'src/Storages/StorageReplicatedMergeTree.cpp' OR old_path = 'src/Storages/StorageReplicatedMergeTree.cpp`
Ideally, we want to recurse through the complete rename hierarchy and collect the full list of files. We could then simply modify our restriction to be path IN (set of filenames). For this we will use a UDF.
Note: this problem could also be solved at data insertion time. We could modify the original git-import tool to add an authoritative file id on all commits, giving us a consistent field value across all commits. Humor us and assume we can’t do this :)
Creating the UDF
In our case, we need a recursive behavior where the function calls itself - each time passing the previous path name and finding the next rename event.
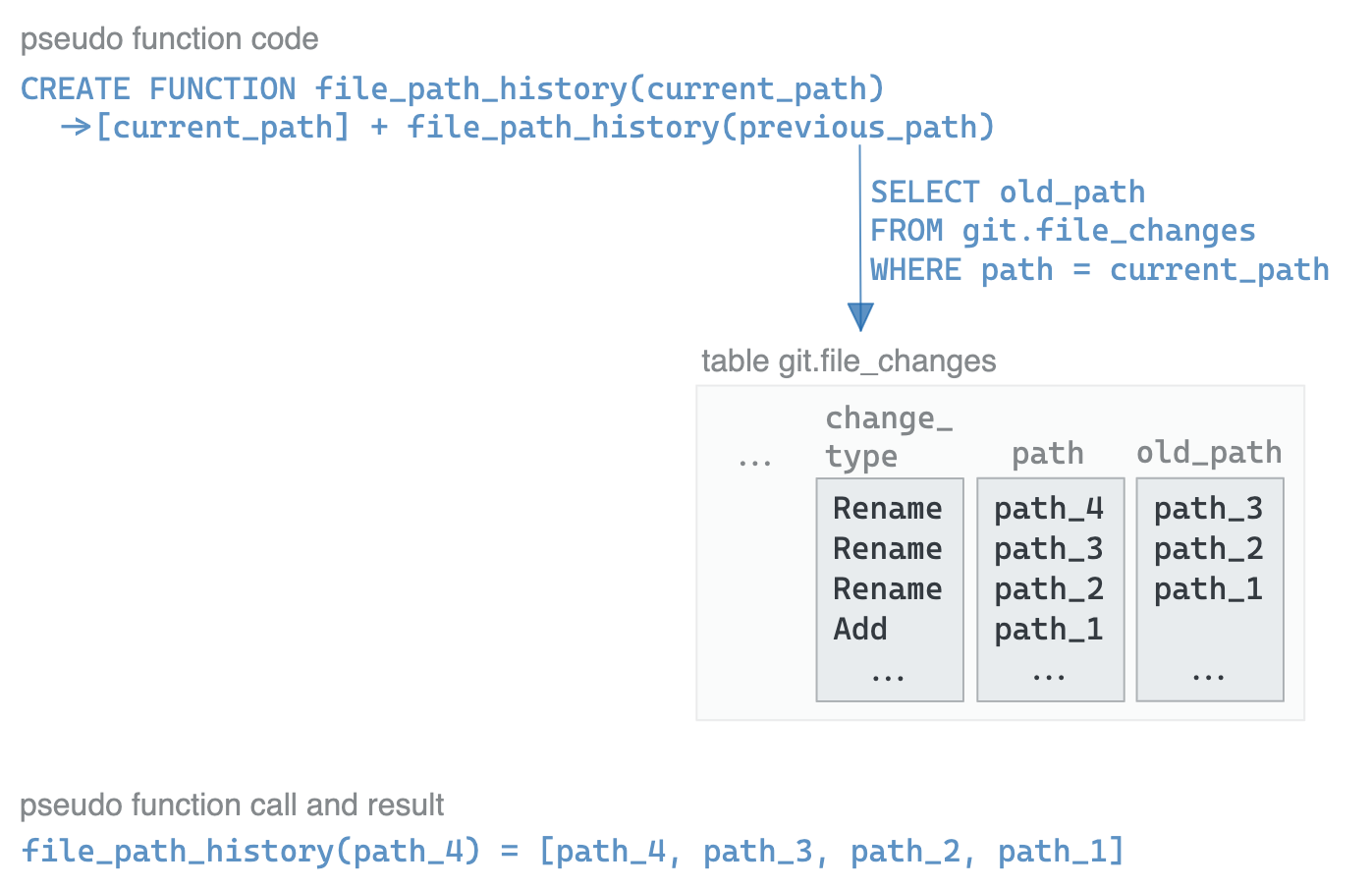
Unfortunately, recursion is not currently supported in ClickHouse UDFs. We can work around this limitation by specifying the function N times, where each function calls another. While this limits us to a rename depth of N, it should be sufficient for our use case. Below we create our first function to show the general structure:
CREATE FUNCTION file_path_history AS n -> if(empty(n), [], arrayConcat([n], file_path_history_01(( SELECT if(empty(old_path), NULL, old_path) FROM git.file_changes WHERE (path = n) AND ((change_type = 'Rename') OR (change_type = 'Add')) LIMIT 1 ))))
Our function file_path_history accepts the file's name of interest as a parameter n - likely the current known path on the first call. This path is then concatenated to the current result using the arrayConcat function, in addition to the result of a UDF call to the next level via file_path_history_01 (we haven’t defined this yet). To this function, we pass the previous filename via the query:
SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1 ))))
The following function, file_path_history_01, is very similar, except it will receive the old path of the original file specified by the user. It, in turn, finds the previous path for this file, invoking file_path_history_02. This artificial recursion continues until either we reach the maximum depth (i.e., the file has been renamed more than five times) or no result is returned from a SELECT (effectively a Null).
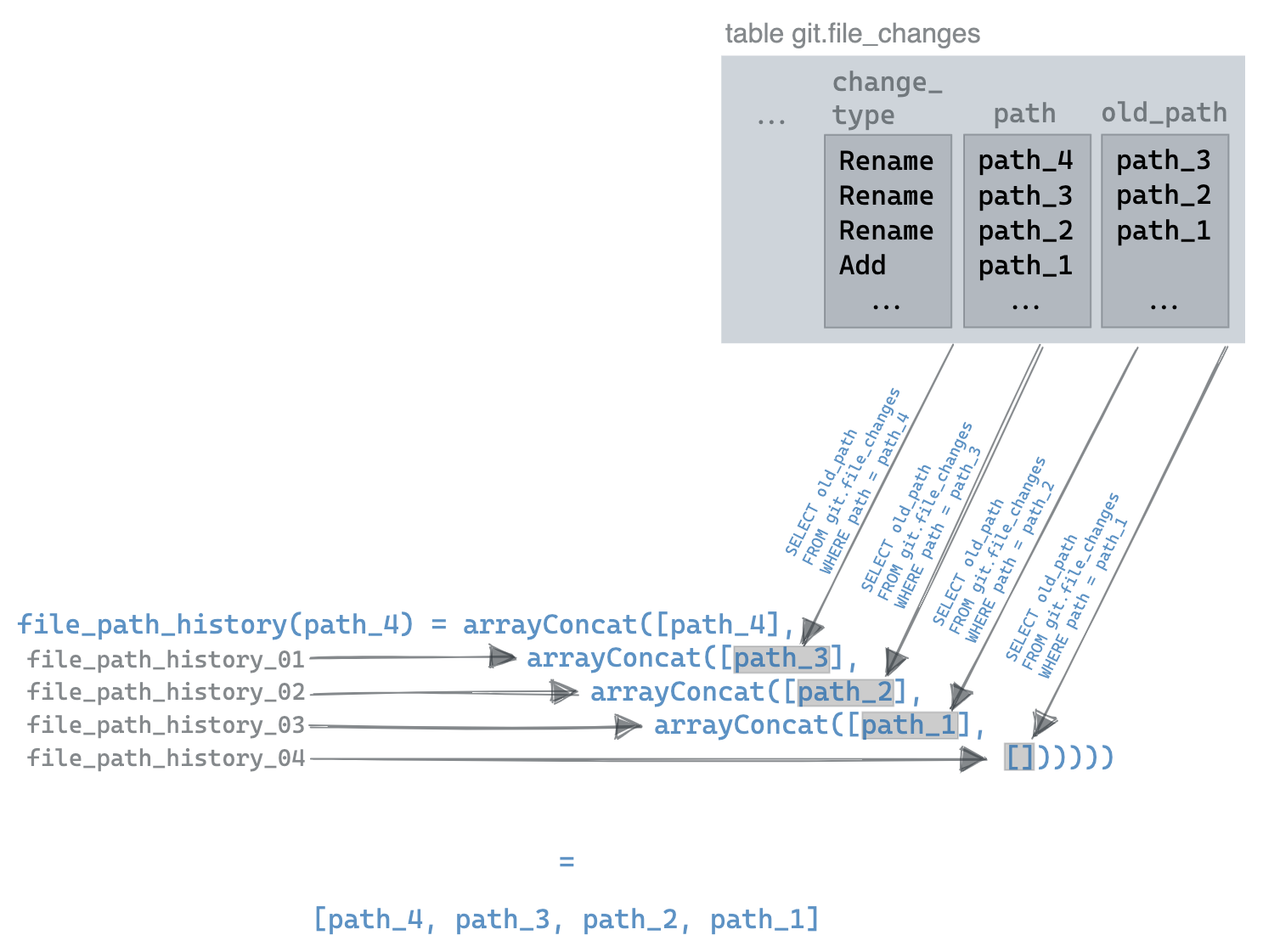
Our complete function definitions look like this. Note our final function is different and provides a base case:
CREATE FUNCTION file_path_history AS (n) -> if(empty(n), [], arrayConcat([n], file_path_history_01((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1)))); CREATE FUNCTION file_path_history_01 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_02((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1)))); CREATE FUNCTION file_path_history_02 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_03((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1)))); CREATE FUNCTION file_path_history_03 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_04((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1)))); CREATE FUNCTION file_path_history_04 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_05((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1)))); CREATE FUNCTION file_path_history_05 AS (n) -> if(isNull(n), [], [n]);
Using our function
We can now use our function file_path_history like any other. Below we get the full path history of our Replicated Merge Tree.
SELECT file_path_history('src/Storages/StorageReplicatedMergeTree.cpp') AS paths FORMAT Vertical Row 1: ────── paths: ['src/Storages/StorageReplicatedMergeTree.cpp', 'dbms/Storages/StorageReplicatedMergeTree.cpp', 'dbms/src/Storages/StorageReplicatedMergeTree.cpp'] 1 row in set. Elapsed: 0.041 sec. Processed 286.72 thousand rows, 20.11 MB (6.99 million rows/s., 490.36 MB/s.)✎
We can also now use our function in our original query to get the full commit history of a file and solve our original question. Below we modify our query slightly to return two commits per filename.
SELECT time, substring(commit_hash, 1, 11) AS commit, path FROM git.file_changes WHERE path IN file_path_history('src/Storages/StorageReplicatedMergeTree.cpp') ORDER BY time DESC LIMIT 2 BY path ┌────────────────time─┬─commit──────┬─path─────────────────────────────────────────────┐ │ 2022-10-30 16:30:51 │ c68ab231f91 │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 2022-10-23 16:24:20 │ b40d9200d20 │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 2020-04-03 15:21:24 │ 38a50f44d34 │ dbms/Storages/StorageReplicatedMergeTree.cpp │ │ 2020-04-02 17:11:10 │ 5b133dd1ce7 │ dbms/Storages/StorageReplicatedMergeTree.cpp │ │ 2020-04-01 19:21:27 │ 1d5a77c1132 │ dbms/src/Storages/StorageReplicatedMergeTree.cpp │ │ 2020-04-01 13:43:09 │ 46322370c00 │ dbms/src/Storages/StorageReplicatedMergeTree.cpp │ └─────────────────────┴─────────────┴──────────────────────────────────────────────────┘ 6 rows in set. Elapsed: 0.079 sec. Processed 552.77 thousand rows, 47.69 MB (6.96 million rows/s., 600.46 MB/s.)✎
Conclusion
In this post we’ve demonstrated how User Defined functions can be used to extend the behavior of ClickHouse to solve otherwise challenging queries. Now available in ClickHouse Cloud, we’d love to hear about your own usage of UDFs!


