Introduction
In a recent blog post, we explored how users can supercharge their website analytics by using ClickHouse and Superset to deliver a fast and flexible means of querying raw data from Google Analytics for minimal cost.
Superset's easy learning curve prompted me to explore how LLMs could offer an even simpler approach to exploring Google Analytics data for less technical users. Amidst the widespread use of acronyms like RAG, ML, and LLM in technical blogs, I seized this chance to delve into an area of Computer Science where my experience is admittedly limited. This post serves as both a record of my journey and experiments in using LLMs and RAG to simplify application interfaces.
Armed with a rather generous set of AWS account permissions granting me access to Amazon Bedrock, I set about trying to build a natural language interface to my raw Google Analytics data. The objective here was simple: to allow users to ask a question in natural language and the appropriate SQL be generated, that ultimately answers their question with the underlying data. If successful, this could form the basis of a simple interface from which a user could ask a question and a sensible chart be rendered.
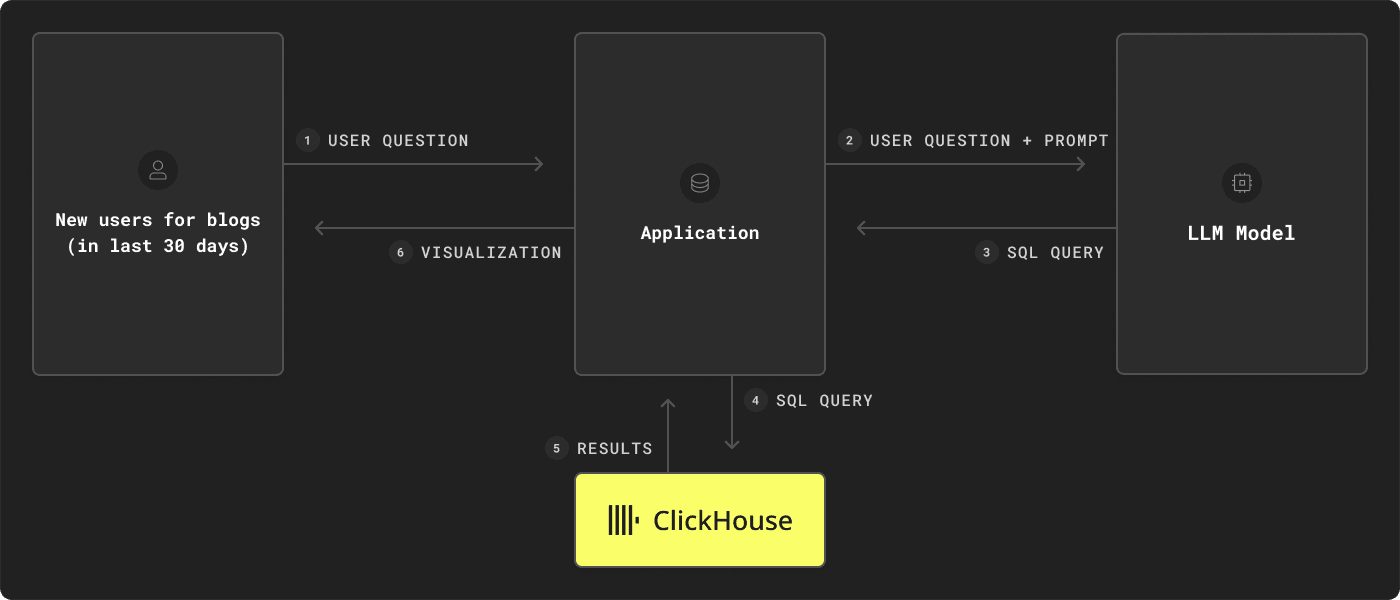
Google Analytics with concepts
From our previous blog, recall we proposed the following schema to hold Google Analytics data in ClickHouse:
CREATE TABLE default.ga_daily
(
`event_date` Date,
`event_timestamp` DateTime64(3),
`event_name` String,
`event_params` Map(String, String),
`ga_session_number` MATERIALIZED CAST(event_params['ga_session_number'], 'Int64'),
`ga_session_id` MATERIALIZED CAST(event_params['ga_session_id'], 'String'),
`page_location` MATERIALIZED CAST(event_params['page_location'], 'String'),
`page_title` MATERIALIZED CAST(event_params['page_title'], 'String'),
`page_referrer` MATERIALIZED CAST(event_params['page_referrer'], 'String'),
`event_previous_timestamp` DateTime64(3),
`event_bundle_sequence_id` Nullable(Int64),
`event_server_timestamp_offset` Nullable(Int64),
`user_id` Nullable(String),
`user_pseudo_id` Nullable(String),
`privacy_info` Tuple(analytics_storage Nullable(String), ads_storage Nullable(String), uses_transient_token Nullable(String)),
`user_first_touch_timestamp` DateTime64(3),
`device` Tuple(category Nullable(String), mobile_brand_name Nullable(String), mobile_model_name Nullable(String), mobile_marketing_name Nullable(String), mobile_os_hardware_model Nullable(String), operating_system Nullable(String), operating_system_version Nullable(String), vendor_id Nullable(String), advertising_id Nullable(String), language Nullable(String), is_limited_ad_tracking Nullable(String), time_zone_offset_seconds Nullable(Int64), browser Nullable(String), browser_version Nullable(String), web_info Tuple(browser Nullable(String), browser_version Nullable(String), hostname Nullable(String))),
`geo` Tuple(city Nullable(String), country Nullable(String), continent Nullable(String), region Nullable(String), sub_continent Nullable(String), metro Nullable(String)),
`app_info` Tuple(id Nullable(String), version Nullable(String), install_store Nullable(String), firebase_app_id Nullable(String), install_source Nullable(String)),
`traffic_source` Tuple(name Nullable(String), medium Nullable(String), source Nullable(String)),
`stream_id` Nullable(String),
`platform` Nullable(String),
`event_dimensions` Tuple(hostname Nullable(String)),
`collected_traffic_source` Tuple(manual_campaign_id Nullable(String), manual_campaign_name Nullable(String), manual_source Nullable(String), manual_medium Nullable(String), manual_term Nullable(String), manual_content Nullable(String), gclid Nullable(String), dclid Nullable(String), srsltid Nullable(String)),
`is_active_user` Nullable(Bool)
)
ENGINE = MergeTree
ORDER BY (event_timestamp, event_name, ga_session_id)
This table holds a row per GA4 event, from which questions such as “Show me returning users over the last 30 days for blog posts,” can be deduced with the right SQL questions.
While we expected most questions for our GA data to be structured like the example above, we also wanted to be able to answer more nuanced questions based on concepts. For example, suppose we wanted “The total number of new users over time who have visited pages based on materialized views”. Most of this question is structured and requires exact column matches and a GROUP BY date. The concept of “materialized views,” however, is a little more nuanced. Needing a stretch goal, this seemed achievable if we could come up with a way of representing a concept as something more concrete the user could possibly refine.
Amazon Bedrock
At this point, it's probably reasonable to assume most readers have used or heard about Large Language Models (LLM's) and Generative AI, and likely even used services such as ChatGPT, which expose them as a service. These services have proven useful for a wide range of applications, including technical users needing to write code snippets. SQL generation performs remarkably well when a schema and question is provided. At ClickHouse, we actually already exploit these capabilities, exposing the ability to query with natural language in our ClickHouse Cloud SQL console.
While ChatGPT is often sufficient to get started, when we want to build something at scale or integrate these capabilities into a production app, it invariably makes sense to explore equivalent services in a cloud provider. For AWS, the Bedrock service provides these capabilities by exposing foundational machine learning models (including LLMs) as a fully managed service. These models are contributed by companies such as Anthropic and Cohere and are made available through a simple API. This represented the simplest way to get started for my app.
Retrieval-Augmented Generation (RAG)
The term RAG also seems to be currently very widespread, with some companies gambling on its need being so pervasive that an entire class of databases has arisen to service this. Retrieval-augmented generation (RAG) is a technique that aims to combine the power of pre-trained language models with the benefits of information retrieval systems. The objective here is typically simple: to enhance the quality and relevance of generated text by providing the model with additional information. This falls into the field of prompt engineering, where we modify our question or prompt to include more useful information to help the LLM formulate a more accurate answer.
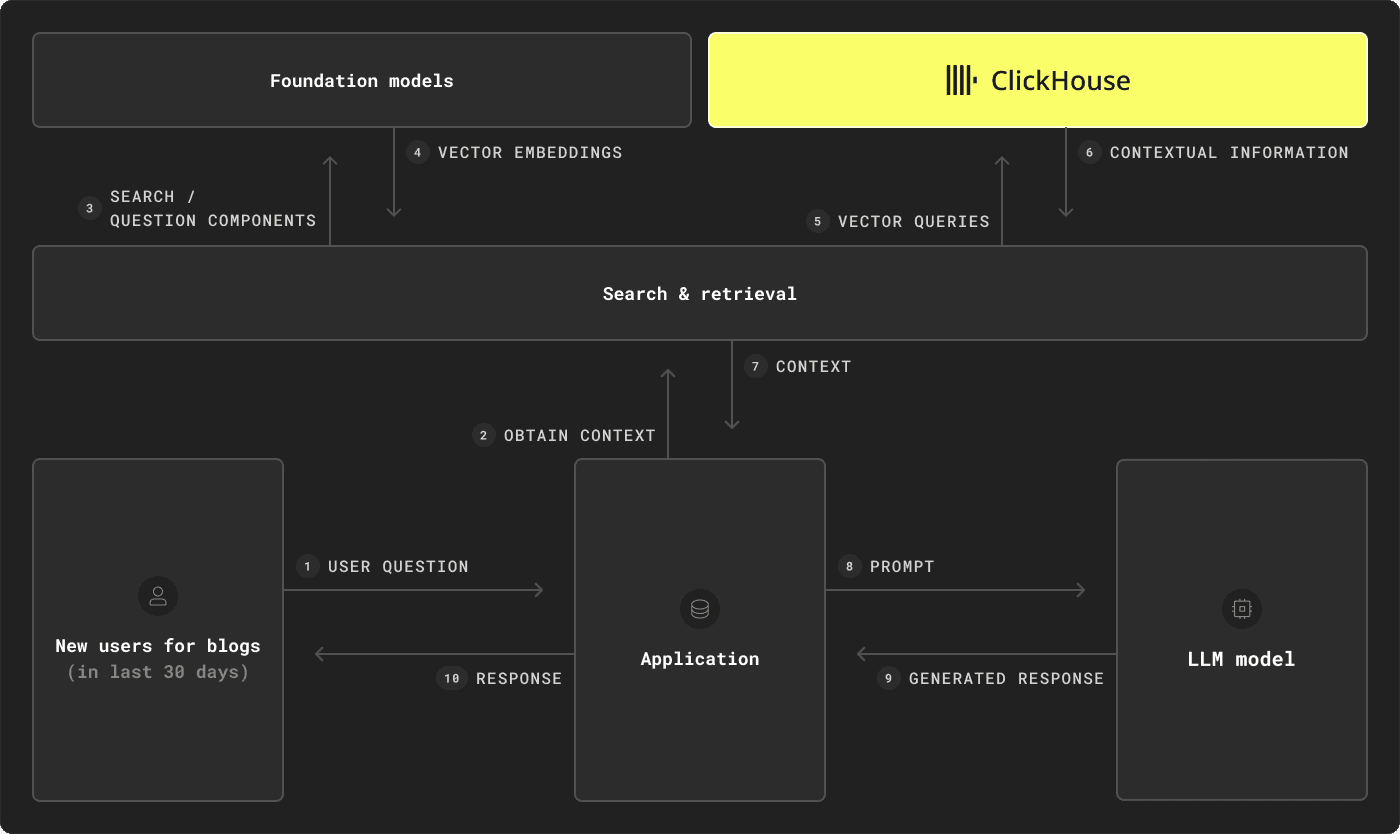
By providing additional information to the LLM, RAG aims to overcome a few problems users often experience when relying on models to generate text, most of which are the result of the LLM's internal knowledge being based on a fixed training corpus from a point in time. Without access to domain-specific or up-to-date information, the model can struggle in scenarios where the question goes beyond this foundational knowledge, resulting in either no answer or "hallucinations" where responses are not grounded in reality and are factually incorrect.
To provide additional supporting information to the model for our Google Analytics use case, we need a means of finding content that is contextually relevant to the question at hand. In an earlier blog post, we explored how this can be done with vector embeddings. To do this, we could use another model to generate embeddings for documents we will use as context, (e.g., internal documentation) and store these in a database. We can then use the same model to convert our user’s natural language question to an embedding and retrieve the most relevant content (e.g., top 10 documents) to use as context when making the request to our LLM model/service.
While dedicated vector databases were specifically designed for only this function, databases like ClickHouse have native support for vector functionality as well. This means that ClickHouse can serve as both a vector and an analytics database, which simplifies overall architectures by removing the need for multiple bespoke data stores in RAG pipelines.
This 2 step process of retrieval and generation is admittedly a simplistic overview of RAG (not least glossing over the biggest challenge of relevancy for the retrieved documents) but sufficient for our needs.
As we’ll discover below, for our use case, RAG is also relevant as we needed to provide not only the table schema but also likely example queries for problems such as how to identify returning users or how the LLM should deal with less structured questions such as “Posts about Materialized views”.
A little bit of research
The foundation of our app is text to SQL. This is an active domain of research and thanks to the Spider: Yale Semantic Parsing and Text-to-SQL Challenge it is relatively easy to see which approaches are leading in providing the best accuracy.
“The goal of the Spider challenge is to develop natural language interfaces to cross-domain databases. It consists of 10,181 questions and 5,693 unique complex SQL queries on 200 databases with multiple tables covering 138 different domains. To do well on it, systems must generalize well to not only new SQL queries but also new database schemas.”
This specific challenge is more general than that of our Google Analytics question-to-text problem - ours is domain-specific, whereas Spider aims to measure the performance of cross-domain zero-shot performance. Despite this, the leader papers seemed worth exploring for inspiration. Reassuringly, the current leaders including DAIL-SQL rely on the principle of using prompt engineering and a RAG-based approach.
The principle innovation with DAIL-SQL is to mask keywords (e.g. columns and values) in a set of possible useful prompt questions (the “candidate set”), with an embedding generated for the question. A “skeleton” query is then generated (and masked) using a specialist pre-trained transformer model. Example questions for the prompt are in turn identified by comparing the question and its skeleton SQL against the candidate questions and their SQL. See here for a more detailed overview. This is surprisingly simple and effective and offers some useful pointers on achieving decent results.
While I did not need the flexibility of the cross-domain features of the above process, it did provide some hints on the need to achieve good results. Providing SQL examples for similar questions seemed essential to good performance - especially in our domain where concepts such as “returning users” cannot easily be deduced from the schema. However, the masking of questions and comparison of SQL queries seemed unnecessary, given the domain-specific nature of my problem.
Most importantly, it's clear the problem should be decomposed into multiple steps.
UDF’s to generate embeddings
Given the above research, our RAG flow would invariably require us to be able to generate embeddings for text (e.g., to find similar questions). For this, we utilize a simple Python UDF embed.py, which can be invoked at query or insert time. This utilizes Amazon’s titan-embed-text-v1 model available through Bedrock. The main code for embed.py is shown below, with full supporting files here:
#!/usr/bin/python3
import json
import sys
from bedrock import get_bedrock_client
from tenacity import (
retry,
stop_after_attempt,
wait_random_exponential,
)
import logging
logging.basicConfig(filename='embed.log', level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
bedrock_runtime = get_bedrock_client(region="us-east-1", silent=True)
accept = "application/json"
contentType = "application/json"
modelId = "amazon.titan-embed-text-v1"
char_limit = 10000 # 1500 tokens effectively
@retry(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(20))
def embeddings_with_backoff(**kwargs):
return bedrock_runtime.invoke_model(**kwargs)
for size in sys.stdin:
# collect batch to process
for row in range(0, int(size)):
try:
text = sys.stdin.readline()
text = text[:char_limit]
body = json.dumps({"inputText": text})
response = embeddings_with_backoff(
body=body, modelId=modelId, accept=accept, contentType=contentType
)
response_body = json.loads(response.get("body").read())
embedding = response_body.get("embedding")
print(json.dumps(embedding))
except Exception as e:
logging.error(e)
print(json.dumps([]))
sys.stdout.flush()
The associated ClickHouse configuration is located under /etc/clickhouse-server/:
<functions>
<function>
<name>embed</name>
<type>executable_pool</type>
<pool_size>3</pool_size>
<send_chunk_header>true</send_chunk_header>
<format>TabSeparated</format>
<return_type>Array(Float32)</return_type>
<argument>
<type>String</type>
</argument>
<command>embed.py</command>
<command_read_timeout>10000000</command_read_timeout>
<command_write_timeout>10000000</command_write_timeout>
<max_command_execution_time>1000000</max_command_execution_time>
</function>
</functions>
A few important points regarding the above:
- We use the tenacity library to ensure we retry failed calls with a backoff. This is essential in case we hit quota limits for Bedrock on either the throughput of tokens or API calls per minute. Note that Bedrock allows requests to be provisioned for higher throughput workloads.
- We use an executable pool to ensure more than one request can be issued at once. This effectively starts N (3 in the config) Python processes, allowing requests to be parallelized.
- The parameter
send_chunk_headerensures multiple row values are sent to the UDF at once. This includes an initial line indicating the number of rows. We therefore read this first fromstdin, before iterating over the lines. This is essential for performance. - Our UDF receives the text and responds with an Array of Float32s.
To invoke this UDF we can simply run:
SELECT embed('some example text')
FORMAT Vertical
Row 1:
──────
embed('some example text'): [0.5078125,0.09472656,..,0.18652344]
1 row in set. Elapsed: 0.444 sec.
This function can also be invoked at insert time. The following INSERT INTO SELECT reads rows from a table site_pages_raw, invoking the embed function on a content field.
INSERT INTO pages SELECT url, title, content, embed(content) as embedding FROM site_pages_raw SETTINGS merge_tree_min_rows_for_concurrent_read = 1, merge_tree_min_bytes_for_concurrent_read=0, min_insert_block_size_rows=10, min_insert_block_size_bytes=0
Note the following with respect to the settings used above:
- The settings
merge_tree_min_rows_for_concurrent_read = 1andmerge_tree_min_bytes_for_concurrent_read = 0ensure the tabletempis read in parallel. These settings are often required when the number of rows in the source table is small. This ensures that our UDF is not invoked with a single thread. Larger tables with more rows and bytes than the default values of 163840 and 251658240, respectively, do not need these settings. However, users will typically be generating embeddings for smaller tables, and hence these are useful. For further details on these settings, see this video. - The settings
min_insert_block_size_rows=10andmin_insert_block_size_bytes=0ensure that we invoke the UDF with fewer rows. Given the throughput is typically 10-20 rows per second when invoking Bedrock, the above values ensure rows appear in the target table at a reasonable rate. Higher throughputs e.g. from invoking local models, would require these settings to be increased to 128 to 4096 (testing required). For further details on these settings, see here. The settingmax_block_sizeis relevant if performing large reads on embeddings.
Overview of RAG flow
The final flow is shown below. The components of the RAG flow were largely assembled independently with testing to ensure each delivered accurate results.
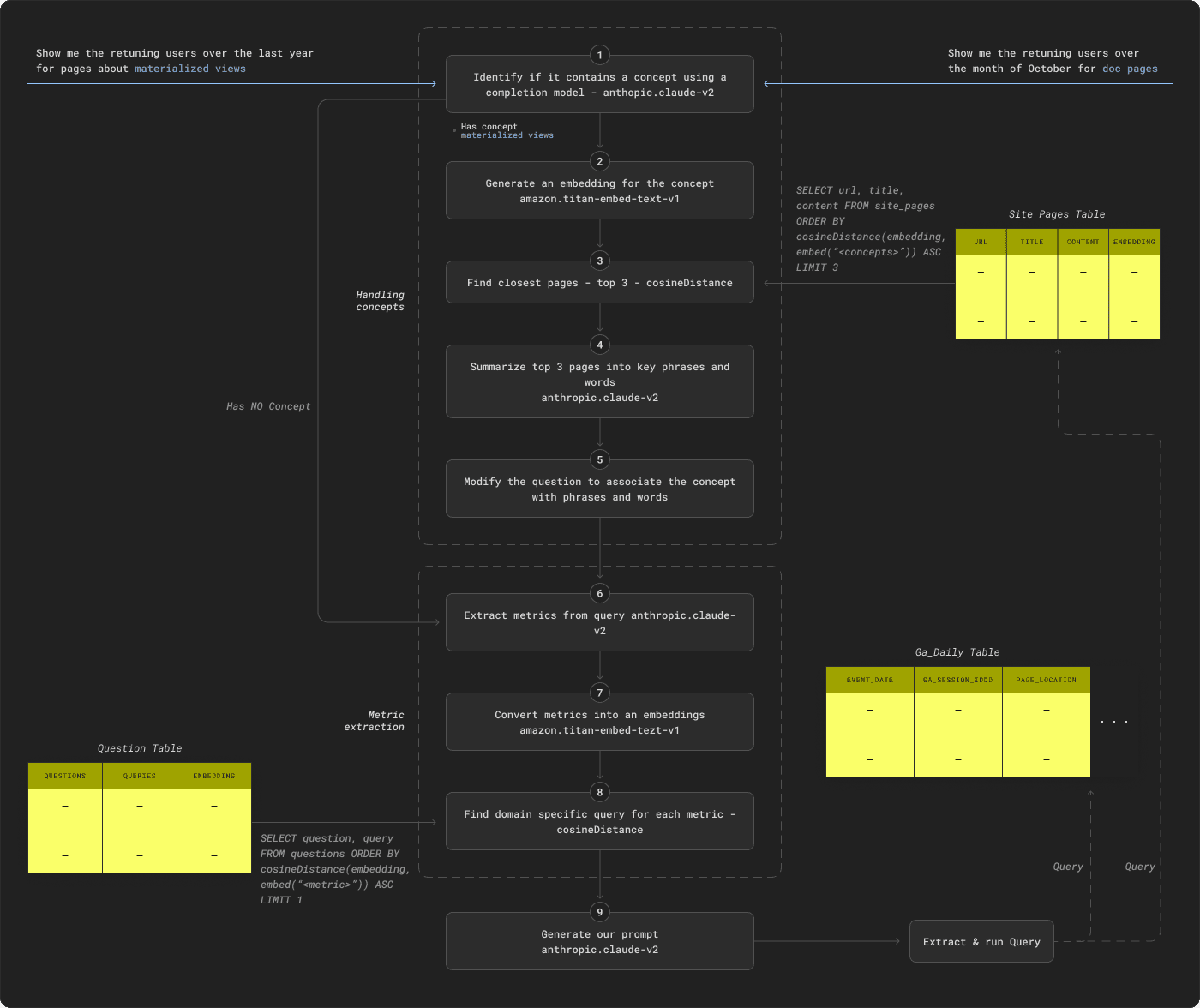
In summary, our flow consists of two main stages to assist with prompt generation: Handling Concepts and Metric Extraction.
Extraction of concepts attempts to identify if the question contains a conceptual filter and takes steps (1) to (5):
- We first identify if the question contains a concept using the
anthropic.claude-v2model and a simple prompt. If not, go to Metric Extraction and step (6). - Convert the concept into an embedding using the
amazon.titan-embed-text-v1model. - Search ClickHouse for the top 3 most relevant pages using the embedding from step (2).
- Prompt the
anthropic.claude-v2model to extract they key words and phrases from the pages returned in step (3) - Modify the original question to associate the concept with the above words.
Metric extraction aims to identify the main metrics which the question needs to compute, in order to ensure relevant examples are added to the prompt. This takes steps (6) to (9):
- Extract GA metrics by prompting the
anthropic.claude-v2model. - Convert metrics into embeddings using the
amazon.titan-embed-text-v1model. - Query for the top matching question for each metric using the embeddings from step (7). Add these to the set of examples.
- Use a simple regex to establish if an area of the site is being targeted and add examples.
Finally, we generate the prompt:
- Generate the final SQL prompt for the
anthropic.claude-v2model to produce the SQL. Execute this against the site pages andga_dailytable.
Handling concepts (steps 1 to 5)
As described above, we also wanted to have the flexibility to handle conceptual questions such as "pages about X". For this, we need the text content for the contextual information, which for our use case, are pages on our website. While writing a generic crawler can be challenging, a simple Scrapy-based crawler for our limited site that exploited our sitemaps[1][2] and page structure should be more than sufficient. The code should be reusable as a basis for those looking to implement a similar service on their own site.
To compare pages with a concept we need a means of:
- Extracting concepts from questions.
- Representing the concepts such that relevant pages can be identified.
For (1), we experimented with a number of techniques but found the anthropic.claude-v2 model, available in Bedrock, to be highly effective. With an appropriate prompt containing examples, this proved accurate at extracting the target concept.
For (2), we first identify pages relevant to the concept extracted from step (1). For this, we create and store embeddings for each of our site pages based on their textual content as well as the concept itself. Given a source table source_pages with url, raw_title, and raw_content columns as shown below, we can insert rows to a target table site_pages invoking the embed function at insert time. Note we also extract the content from the page using the extractTextFromHTML function and limit embedding generation to 300 tokens (using the tokens function to clean the text).
CREATE TABLE source_pages
(
`url` String,
`raw_title` String,
`raw_content` String
)
ENGINE = MergeTree
ORDER BY url
CREATE TABLE site_pages
(
`url` String,
`raw_title` String,
`raw_content` String,
`title` String,
`content` String,
`embedding` Array(Float32)
)
ENGINE = MergeTree
ORDER BY url
INSERT INTO site_pages
SELECT url, raw_title, raw_content, extractTextFromHTML(raw_title) AS title, extractTextFromHTML(raw_content) AS content, embed(arrayStringConcat(arraySlice(tokens(concat(title, content)), 1, 300), ' ')) AS embedding
FROM source_pages
SETTINGS merge_tree_min_rows_for_concurrent_read = 1, merge_tree_min_bytes_for_concurrent_read = 0, min_insert_block_size_rows = 10, min_insert_block_size_bytes = 0
0 rows in set. Elapsed: 390.835 sec. Processed 2.95 thousand rows, 113.37 MB (7.55 rows/s., 290.08 KB/s.)
Peak memory usage: 266.70 MiB.
We can search this table using the following query which uses the earlier embed function to create an embedding for our concept using the titan model. We found cosineDistance to deliver the best results here for this model:
SELECT url, title, content FROM site_pages ORDER BY cosineDistance(embedding, embed('<concept>')) ASC LIMIT 3
Using the aggregated text for the 3 most relevant pages, we in turn extract the main phrases and keywords (again using the anthropic.claude-v2 model). These phrases and keywords are added to the prompt as an example question and answer. This is our domain-specific context that will help the LLM perform more accurately for our use case. For example, the concept “dictionaries” might result in the following being added to the prompt:
/* Answer the following: To filter by pages containing words: */
SELECT page_location FROM ga_daily WHERE page_location IN (SELECT url FROM site_pages WHERE content ILIKE 'dictionary engine' OR content ILIKE 'dictionary functions' OR content ILIKE 'dictionary' OR content ILIKE 'dictionary configuration' OR content ILIKE 'cache' OR content ILIKE 'dictionary updates' OR content ILIKE 'dictionaries')
In addition, we rewrite the original question to indicate that the concept involves filtering on words.
What are the number of new users for blogs about dictionaries over time?
becomes…
What are the number of new users for blogs about dictionaries over time? For the topic of dictionaries, filter by dictionary configuration,dictionaries,dictionary functions,cache,dictionary engine,dictionary,dictionary updates
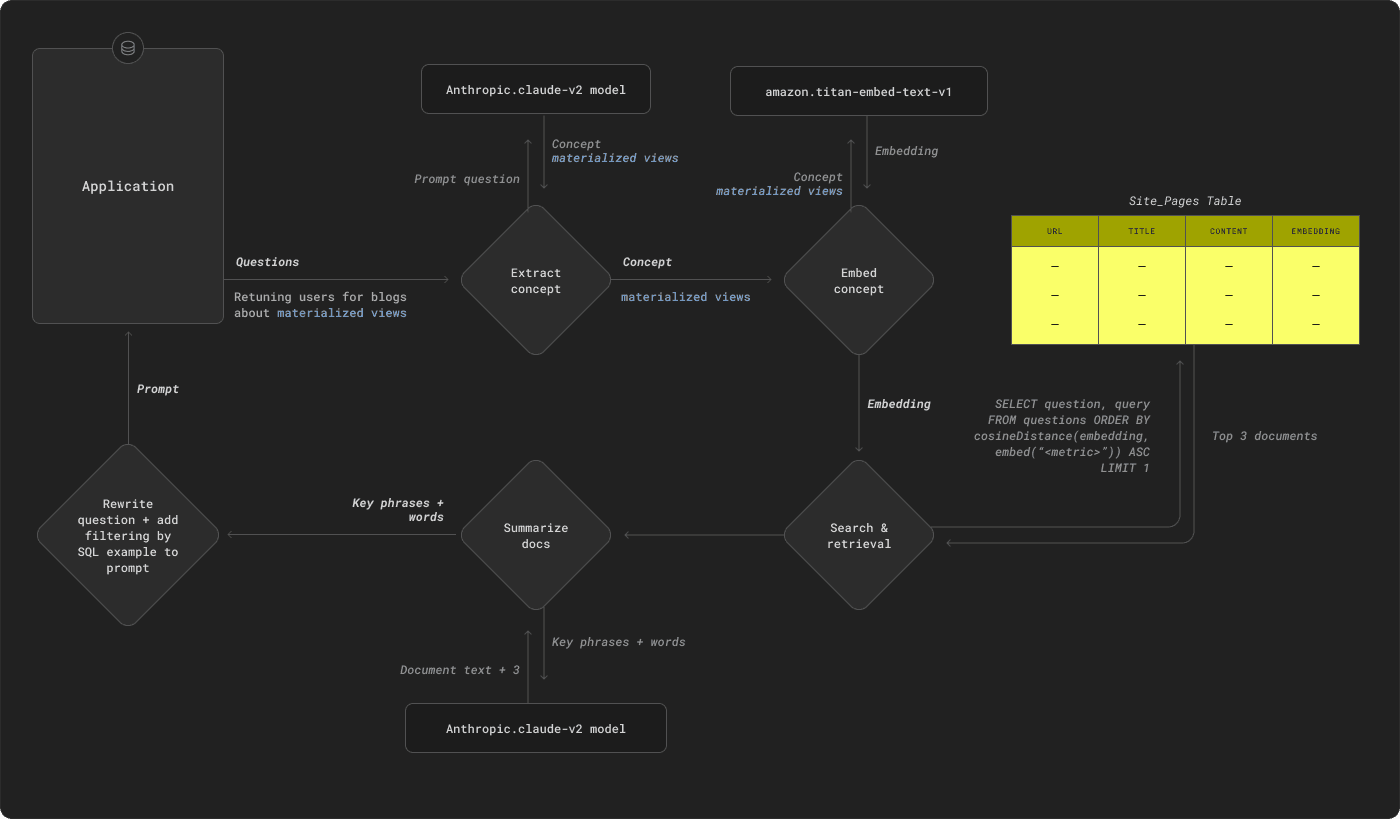
The principle idea here is we would present these phrases to the user as those most representing the target concept, possibly with the matching pages. They could in turn choose to add or remove phases and words based on the results. While this is not necessarily the only way to represent a concept, it has the advantage of turning a loose idea such as a concept into something concrete. This approach is also simpler than the other obvious alternative: simply adding a filter to the main query, which filters pages based on as a distance function to the concept’s embedding. This latter approach requires us to either define a minimum score, which would need to be established, or only using the top K. Neither of these seemed realistic and explainable to the end user.
Extracting metrics (steps 6 to 9)
Based on the research, it appeared that adding questions to the prompt would be essential in obtaining good results. This seemed even more important given that for many of the Google Analytics metrics such as “Returning users” or “Total sessions,” there is no easy way to deduce them from the schema. For example, as shown in our earlier blog, we estimate the metric of “Returning users” as the following query:
SELECT event_date, uniqExact(user_pseudo_id) AS returning_users
FROM ga_daily
WHERE (event_name = 'session_start') AND is_active_user AND (ga_session_number > 1 OR user_first_touch_timestamp < event_date)
GROUP BY event_date
ORDER BY event_date ASC
This particular query would be challenging for the LLM to infer from just a schema. We therefore aim to provide this as context, when required, in our prompt. For example:
/*Answer the following: find returning users:*/
SELECT uniqExact(user_pseudo_id) AS returning_users FROM ga_daily WHERE (event_name = 'session_start') AND is_active_user AND (ga_session_number > 1 OR user_first_touch_timestamp < event_date)
Based on some initial experimentations, it also became apparent that providing all of the possible metrics as questions, with their SQL examples, in the prompt would degrade the prediction quality of the generated text. Longer prompts result in critical details being ignored and are also slower, consuming more tokens. We therefore opted for a simple supplementary table containing the question, its SQL response, and an embedding of the question itself:
CREATE TABLE default.questions
(
`question` String,
`query` String,
`embedding` Array(Float32)
)
ENGINE = MergeTree
ORDER BY question
We can populate this using the same UDF embed function as before.
Initial experiments used the following query to identify the top 3 most relevant example questions:
SELECT question, query FROM questions ORDER BY cosineDistance(embedding, embed("Show me returning users over the last 30 days for blog posts")) ASC LIMIT 3
While simple, this delivered unsatisfactory results with the results not always including the GA metric that was required. We needed a means to extract:
- The specific Google Analytics metrics that the question included e.g. “returning users”.
- Whether an area of the site was being targeted by the question e.g. blogs or docs. This was likely common for our use case and translates to a specific filter on the url. This “domain knowledge” is also not inferable from the schema.
For this task, we reuse the Claude model to extract the key metrics from the query using a prompt with examples. This returns the key metrics which in turn is embedded and used to identify appropriate questions.
For example, for the question “What are the number of returning users per day for the month of October for doc pages?” we extract the metric “returning users” leading to the following query:
SELECT question, query FROM questions ORDER BY cosineDistance(embedding, embed("returning users")) ASC LIMIT 1
The matching questions and their accompanying SQL are in turn added to our final prompt. Finally, if the question filters by blogs or documentation (established through a simple regex match) we add an example of how to filter by this site area.
The prompt (step 10)
Considering the earlier research emphasizing the importance of prompt structure, we also attempted to follow the guidelines laid out by the anthropic documentation for the claude model. This includes an excellent deck for prompt engineering for the model from which the following seemed relevant to my task:
- Follow the Human/Assistance required structure.
- Utilize XML tags to provide prompt structures in the question and to allow the response to be delimited e.g. provide examples in
<example>tags, schema in<schema>tags. - Provide additional information as rules for the schema.
- Ordering of the prompt patterns. This includes ensuring requests for output formatting and the question are at the bottom of the prompt.
Considering this, our prompt looks something like this:
Human: You have to generate ClickHouse SQL using natural language query/request <request></request>. Your goal -- create accurate ClickHouse SQL statements and help the user extract data from ClickHouse database. You will be provided with rules <rules></rules>, database schema <schema></schema> and relevant SQL statement examples </examples></examples>.
This is the table schema for ga_daily.
<schema>
CREATE TABLE ga_daily
(
`event_date` Date,
`event_timestamp` DateTime64(3),
`event_name` Nullable(String),
`event_params` Map(String, String),
`ga_session_number` MATERIALIZED CAST(event_params['ga_session_number'], 'Int64'),
`ga_session_id` MATERIALIZED CAST(event_params['ga_session_id'], 'String'),
`page_location` MATERIALIZED CAST(event_params['page_location'], 'String'),
`page_title` MATERIALIZED CAST(event_params['page_title'], 'String'),
`page_referrer` MATERIALIZED CAST(event_params['page_referrer'], 'String'),
`event_previous_timestamp` DateTime64(3),
`event_bundle_sequence_id` Nullable(Int64),
`event_server_timestamp_offset` Nullable(Int64),
`user_id` Nullable(String),
`user_pseudo_id` Nullable(String),
`privacy_info` Tuple(analytics_storage Nullable(String), ads_storage Nullable(String), uses_transient_token Nullable(String)),
`user_first_touch_timestamp` DateTime64(3),
`device` Tuple(category Nullable(String), mobile_brand_name Nullable(String), mobile_model_name Nullable(String), mobile_marketing_name Nullable(String), mobile_os_hardware_model Nullable(String), operating_system Nullable(String), operating_system_version Nullable(String), vendor_id Nullable(String), advertising_id Nullable(String), language Nullable(String), is_limited_ad_tracking Nullable(String), time_zone_offset_seconds Nullable(Int64), browser Nullable(String), browser_version Nullable(String), web_info Tuple(browser Nullable(String), browser_version Nullable(String), hostname Nullable(String))),
`geo` Tuple(city Nullable(String), country Nullable(String), continent Nullable(String), region Nullable(String), sub_continent Nullable(String), metro Nullable(String)),
`app_info` Tuple(id Nullable(String), version Nullable(String), install_store Nullable(String), firebase_app_id Nullable(String), install_source Nullable(String)),
`traffic_source` Tuple(name Nullable(String), medium Nullable(String), source Nullable(String)),
`stream_id` Nullable(String),
`platform` Nullable(String),
`event_dimensions` Tuple(hostname Nullable(String)),
`collected_traffic_source` Tuple(manual_campaign_id Nullable(String), manual_campaign_name Nullable(String), manual_source Nullable(String), manual_medium Nullable(String), manual_term Nullable(String), manual_content Nullable(String), gclid Nullable(String), dclid Nullable(String), srsltid Nullable(String)),
`is_active_user` Nullable(Bool)
)
ENGINE = MergeTree
ORDER BY event_timestamp
</schema>
This is the table schema for site_pages.
<schema>
CREATE TABLE site_pages
(
`url` String,
`title` String,
`content` String
)
ENGINE = MergeTree
ORDER BY url
</schema>
<rules>
You can use the tables "ga_daily" and "site_pages".
The table ga_daily contains website analytics data with a row for user events. The following columns are important:
- event_name - A string column. Filter by 'first_visit' if identifying new users, 'session_start' for returning users and 'page_view' for page views.
- event_date - A Date column on which the event occured
- event_timestamp - A DateTime64(3) with the event time to milli-second accuracy
- ga_session_id - A string identifying a user session.
- ga_session_number - The session number for the user
- user_pseudo_id - A string uniquely identifying a user
- is_active_user - A boolean indicating if the user was active. True if active or engaged.
- user_first_touch_timestamp - The first time a user visited the site.
- page_location - the full url of the page.
- page_title - The page title.
- page_referer - The referer for the page. A full url.
- traffic_source.name provides the source of the traffic.
</rules>
<examples>
/*Answer the following: find new users:*/
SELECT count() AS new_users FROM ga_daily WHERE event_name = 'first_visit'
/*Answer the following: filter by blogs:*/
SELECT page_location FROM ga_daily WHERE page_location LIKE '%/blog/%'
/* Answer the following: To filter by pages containing words: */
SELECT page_location FROM ga_daily WHERE page_location IN (SELECT url FROM site_pages WHERE content ILIKE 'cache' OR content ILIKE 'dictionary' OR content ILIKE 'dictionaries' OR content ILIKE 'dictionary configuration' OR content ILIKE 'dictionary updates' OR content ILIKE 'dictionary functions' OR content ILIKE 'dictionary engine')
</examples>
<request> Considering all above generate a ClickHouse SQL statement for the following query:
<query>What are the number of new users for blogs about dictionaries over time?. For the topic of dictionaries, filter by cache,dictionary,dictionaries,dictionary configuration,dictionary updates,dictionary functions,dictionary engine</query></request>
Put result statement in <sql></sql> tags:
Model Parameters
Per the recommendations of Anthropic, we set the model temperature to 0 to deliver more consistent results over repeated trials. A value of 100 for top_k appeared to deliver reasonably consistent results and avoided random terms being injected that were part of the long tail.
Results & Challenges
So the question is, how well does this perform? To evaluate this, we created a test of questions. Below, we present the question generated and whether this produces the intended answer.
The above is not an extensive test set. A production system would require a far more complete set of questions, with a test framework to evaluate the response of the queries against the authoritative response (testing responses seem more appropriate since question generation may vary).
| Question | Generated Response | Correct |
|---|---|---|
| What are the number of returning users for the month of October 2023 for doc pages per day? | sql SELECT event_date, uniqExact(user_pseudo_id) AS returning_users FROM ga_daily WHERE event_name = 'session_start' AND is_active_user AND (ga_session_number > 1 OR user_first_touch_timestamp < event_date) AND event_date BETWEEN '2023-10-01' AND '2023-10-31' AND page_location LIKE '%/docs/%' GROUP BY event_date ORDER BY event_date | Yes |
| What are the number of new users for blogs about dictionaries over time? | sql SELECT toStartOfMonth(event_date) AS month, count() AS new_users FROM ga_daily WHERE event_name = 'first_visit' AND page_location IN ( SELECT url FROM site_pages WHERE content ILIKE '%dictionary%' OR content ILIKE '%dictionary functions%' OR content ILIKE '%dictionaries%' OR content ILIKE '%dictionary configuration%' OR content ILIKE '%dictionary engine%' OR content ILIKE '%cache%' OR content ILIKE '%dictionary updates%') GROUP BY month ORDER BY month | Yes |
| What are the total sessions since January 2023 by month for pages where the url contains '/docs/en'? | sql SELECT toStartOfMonth(event_date) AS month, uniqExact(ga_session_id, '_', user_pseudo_id) AS total_sessions FROM ga_daily WHERE page_location LIKE '%/docs/en%' AND event_date >= '2023-01-01' GROUP BY month ORDER BY month | Yes |
| What are the total page views over time? | sql SELECT toStartOfDay(event_date) AS day, count() AS total_page_views FROM ga_daily WHERE event_name = 'page_view' GROUP BY day ORDER BY day | Yes |
| How many active users have visited blogs about codecs and compression techniques? | sql SELECT count(DISTINCT user_pseudo_id) AS active_users FROM ga_daily WHERE ((event_name = 'session_start') AND is_active_user) OR (event_name = 'first_visit') AND page_location IN ( SELECT url FROM site_pages WHERE content ILIKE ANY ('%codecs%', '%zstd%', '%lz4%', '%techniques%', '%compression%') ) | Yes |
| What are the total users over time? | sql SELECT toDate(event_timestamp) AS date, uniq(user_pseudo_id) AS total_users FROM ga_daily WHERE event_name = 'session_start' GROUP BY date ORDER BY date | Yes |
| What are the total users over time for pages about materialized views? | sql SELECT toStartOfMonth(event_date) AS month, uniq(user_pseudo_id) AS total_users FROM ga_daily WHERE event_name = 'session_start' AND page_location IN ( SELECT url FROM site_pages WHERE content ILIKE '%monthly aggregated%' OR content ILIKE '%materialized views%' OR content ILIKE '%system tables%' OR content ILIKE '%materialized%' OR content ILIKE '%materialized view%' OR content ILIKE '%queries%' OR content ILIKE '%yearly aggregated%' ) GROUP BY month ORDER BY month | Yes |
| What is the source of traffic over time? | sql SELECT toStartOfHour(event_timestamp) AS hour, traffic_source.name AS source, count(*) AS visits FROM ga_daily WHERE event_name = 'session_start' GROUP BY hour, source ORDER BY hour | Yes but the question is vague e.g. time unit. |
| What are the total website sessions for pages about Snowflake? | sql SELECT count(DISTINCT ga_session_id, '_', user_pseudo_id) AS total_sessions FROM ga_daily WHERE page_location IN ( SELECT url FROM site_pages WHERE content ILIKE '%snowflake%' OR content ILIKE '%cloud data warehouse%' OR content ILIKE '%real-time analytics%' OR content ILIKE '%materialized views%' OR content ILIKE '%micro-partitions%' ) | Yes |
| What are the average number views per blog post over time? | sql SELECT toStartOfMonth(event_date) AS month, page_title, count() AS views FROM ga_daily WHERE page_location LIKE '%/blog/%' AND event_name = 'page_view' GROUP BY month, page_title ORDER BY month, views DESC | Yes. page_title may not be unique but users can refine. |
| How many users who visited the blog with the title 'Supercharging your large ClickHouse data loads - Tuning a large data load for speed?' were new? | sql SELECT count() AS new_users FROM ga_daily WHERE event_name = 'first_visit' AND page_location IN ( SELECT url FROM site_pages WHERE content ILIKE '%clickhouse%' OR content ILIKE '%loads%' OR content ILIKE '%large%' OR content ILIKE '%speed%' OR content ILIKE '%data loads%' OR content ILIKE '%supercharging%' OR content ILIKE '%tuning%' OR content ILIKE '%data%' AND title = 'Supercharging your large ClickHouse data loads - Tuning a large data load for speed?' ) | Yes. Unnecessarily filtered on content due to incorrect identification of concept. |
| What was the ratio of new to returning users in October 2023? | sql WITH ( SELECT count() AS new_usersFROM ga_daily WHERE (event_name = 'first_visit') AND (toYYYYMM(event_date) = 202310) ) AS new_users, ( SELECT uniqExact(user_pseudo_id) AS returning_users FROM ga_daily WHERE (event_name = 'session_start') AND is_active_user AND ((ga_session_number > 1) OR (user_first_touch_timestamp < event_date)) AND (toYYYYMM(event_date) = 202310) ) AS returning_users SELECT if(new_users = 0, 0, returning_users / new_users) AS new_to_returning_ratio | Yes |
| What is the average number of views for doc pages for each returning user per day? | sql SELECT user_pseudo_id, event_date, count() AS page_views FROM ga_daily WHERE event_name = 'page_view' AND page_location LIKE '%/docs/%' AND is_active_user = 1 GROUP BY user_pseudo_id, event_date ORDER BY user_pseudo_id, event_date | No. This computes the average user views per day. Does Not filter to returning users. |
| For each day from September 2003 how many blog posts were published? | sql SELECT toDate(event_timestamp) AS event_date, count(*) AS blog_posts_published FROM ga_daily WHERE page_location LIKE '%/blog/%' GROUP BY event_date HAVING event_date >= '2003-09-01' AND event_date <= '2003-09-30' | No. No concept of publishing. |
A few observations from this sample of results:
- When the question can be addressed by a GROUP BY, and it targets a single Google Analytics metric, the provided context seems to work well.
- Filtering by concepts, based on defining a concept as a set of words, seems to work well with it being realized as a sub-query. Any interface would like to ask a user to refine these words since they estimate a concept at best.
- ClickHouse documentation clearly was part of the LLM model training, since functions like
toStartOfMonthare used despite not occurring in the prompt. However, additional docs-based context would likely be useful. - The model provides a decent effort when the time period is vague e.g. “What is the source of traffic over time?” an interval is used. This could likely be addressed with a prompt modification.
- Even when no example questions are provided, the correct answer is delivered e.g., for identifying the source of traffic. In this case, the appropriate column is deduced from the schema and additional context.
- The model struggles with the latter two queries. “What is the average number of views for doc pages for each returning user per day?” combines two GA metrics and requires a sub-query to identify the returning users, with average views per user filtered by this set. However, the query is generated to compute (with an incorrect query) the average number of views for users per day. This query is conceptually challenging and may benefit from fine tuning.
- Our latter question fails from insufficient context. We have no sample questions showing how to compute the publish date of a blog.
Learnings, challenges & next steps
The biggest learning from this implementation was to decompose the RAG flow into multiple steps. In our above flow, we have separate uses of a foundational model to identify concepts and metrics to ensure the appropriate context is provided in the prompt.
The above prompt also took some iterations to ensure it was correct. Prompt structure and adherence to the guidelines of the Anthropic documentation proved essential - especially the prompt ordering and use of XML tags. Without adhering to these standards, we found that information would be ignored - specifically examples. The process of prompt engineering and refinement is highly iterative and, in reality, needs a test harness with a diverse set of example test problems. Without this, the process can prove extremely frustrating.
In general, the above performance is promising, but it is clear that the approach struggles when example queries cannot be provided for a specific issue. Specifically, we lack example questions that assist with structuring more complex join queries or sub-filtering. These are more challenging to generically capture as questions, with the majority of our examples simply showing how to compute a metric. The next steps may be to capture a diverse range of example problems. The closest conceptual match of these may then be included as an example in addition to the existing ones, which are based on explicit metrics.
It is clearly important for questions to be precise and guidelines to be provided to users on how to construct questions. Our RAG pipeline is currently quite slow, with multiple steps that could possibly use lighter-weight models and/or few tokens. Refinement of models may also benefit accuracy in a number of steps. Model refinement may also be worth exploring in each step to improve performance and accuracy.
The current accuracy is not sufficient for an application to automatically render a chart. We have therefore decided to explore an approach where the generated SQL is shown to the user in addition to a chart along with the context that was added to the prompt. This would align with our likely need for users to refine the words used to represent a concept. While this may not solve our initial problem, we suspect users new to the dataset might still find value in this approach.


