Get started with ClickHouse Cloud today and receive $300 in credits. To learn more about our volume-based discounts, contact us or visit our pricing page.
Blog / Engineering
Real-time Event Streaming with ClickHouse, Kafka Connect and Confluent Cloud
Dale McDiarmid
Jun 22, 2023
Introduction to the ClickHouse Kafka Connector
Earlier this year, we introduced a new official open-source ClickHouse Kafka connector based on the Kafka Connect framework. This connector was designed to use new features of ClickHouse, specifically the Keeper Map table engine, to provide exactly-once semantics. We are pleased to announce that this connector has been tested in Confluent Cloud and is now available via the “Confluent Cloud Custom Connectors” offering.
This blog post demonstrates using this new deployment method to reliably stream Ethereum Cryptocurrency events to ClickHouse Cloud from a Google Pub/Sub via a Confluent Cloud Kafka topic. We achieve this with zero code and only UI-based configuration.
We use a development instance of a ClickHouse Cloud cluster for our examples. However, these examples should be reproducible on an equivalently sized self-managed cluster. Note that a larger instance would be required to host the entire Ethereum dataset - see our dedicated blog post on this topic. Alternatively, start your ClickHouse Cloud cluster today, and receive $300 of credit. Let us worry about the infrastructure and get querying!
Examples assume you have Google Cloud and Confluent accounts. These examples, which use the smallest subset of the data, should cost less than $1 a month for Google Cloud and around $6 per day for Confluent.
Confluent Cloud & Custom Connectors
Apache Kafka is a ubiquitous open-source distributed event streaming platform that thousands of companies use for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
As well as maintaining and distributing an enterprise version of Kafka, Confluent offers a fully-managed Cloud environment where users can deploy Kafka. This includes a managed offering of the Kafka Connect framework, a component of Kafka that works as a centralized data hub for simple data integration between databases, key-value stores, search indexes, and file systems. Historically, users could only deploy officially supported connectors in Confluent Cloud, simply defining the level of parallelism (tasks) without needing to worry about managing the associated infrastructure.
Recently, Confluent extended this offering with support for Custom Connectors. This allows users to deploy any Java-based connector built on the Kafka connect framework by simply uploading the compiled package and specifying the key configuration details. These connectors can, in turn, be deployed using the same managed offering as official connectors owned by Confluent.
Here at ClickHouse, we often see users using Kafka streaming capabilities to process and buffer events prior to inserting them into ClickHouse for real-time analytics. This offering is, therefore, exciting for ClickHouse Cloud users and existing Confluent customers, who can now easily stream data between their Kafka topics and ClickHouse instances using the official ClickHouse Kafka Connect connector without worrying about managing infrastructure.
The full documentation for Confluent’s Custom Connector and the currently supported AWS regions can be found here.
Test Dataset
For our test dataset, we use an Ethereum Cryptocurrency dataset made available by Google in a public project.
No prior experience with crypto is required for reading this blog post, but for those interested, the Introduction to Ethereum provides a useful overview, as well as Google’s blog on how this dataset was constructed.
In summary, our dataset consists of 4 tables. This is a subset of the full data but is sufficient for most common questions:
- Blocks - Blocks are batches of transactions with a hash of the previous block in the chain. Approximately 17 million rows with a growth rate of 7k per day.
- Transactions - Transactions are cryptographically signed instructions from accounts. An account will initiate a transaction to update the state of the Ethereum network, e.g., transferring ETH from one account to another. Over 2 billion with around 1 million additions per day.
- Traces - Internal transactions that allow querying all Ethereum addresses with their balances. Over 7 billion with 5 million additions per day.
- Contracts - A "smart contract" is simply a program that runs on the Ethereum blockchain. Over 60 million with around 50k additions per day.
From Batch to Streaming
We have already explored this dataset in detail in an earlier blog post, comparing BigQuery to ClickHouse, where we proposed a batch-based approach to keep this dataset up-to-date in ClickHouse. This was achieved by periodically exporting data from the public BigQuery table (via a scheduled query) to GCS and importing this into ClickHouse via a simple scheduled cron job.

While this was sufficient for our needs at the time and used to keep our public sql.clickhouse.com environment up-to-date for our crypto enthusiast users, it introduced an unsatisfactory delay (around 30 mins) between the data being available on the blockchain and BigQuery and it being queryable in ClickHouse.
Fortunately, Google also made this dataset available in several public Pub/Sub topics, providing a stream of the events that can be consumed. With a delay of only 4 minutes from the Ethereum blockchain, this source would allow us to provide a comparable service to BigQuery.
Needing a robust pipeline to connect these public Pub/Sub topics to ClickHouse, and wanting to minimize the initial work and any future maintenance overhead, a cloud-hosted approach using our new connector seemed the ideal solution with Confluent hosting the infrastructure. As well as reducing the latency before the data is available in ClickHouse, Kafka would allow us to buffer up to N day's worth of data and provide us with a replay capability if required.
To achieve this architecture, we also need a reliable means of sending messages from Pub/Sub to Kafka. Confluent provides a source connector for this purpose, which is also deployable with zero code. Combining these connectors produces the following simple architecture:
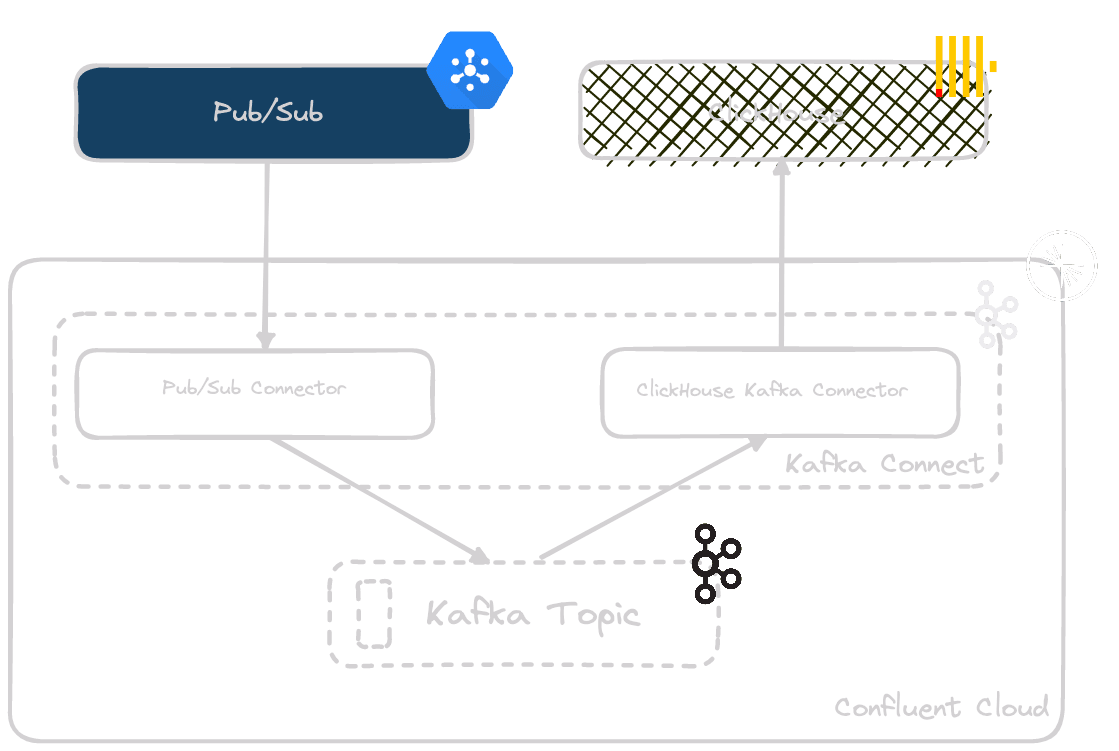
A few simple steps
For our example, we will use the Ethereum blocks dataset. This represents the smallest of the available Ethereum datasets, with around 17m rows and 7000 new blocks formed a day. However, we use the same approach for the other Ethereum datasets, referencing configuration files where required, including the largest table traces. This consists of over 7b rows, with around 5.5m added daily.
This data is ideal for ClickHouse, with the immutable blockchain producing append-only rows. Irrespective of the dataset, a single worker for the Pub/Sub connector and ClickHouse Kafka Connector is sufficient for this throughput.
Create a Pub/Sub subscription
Google Pub/Sub is an asynchronous and scalable messaging service that decouples services producing messages from services processing those messages. Like Kafka, publishers produce messages to a topic without concern about how they will be later processed and asynchronously consumed by subscribers via a subscription.
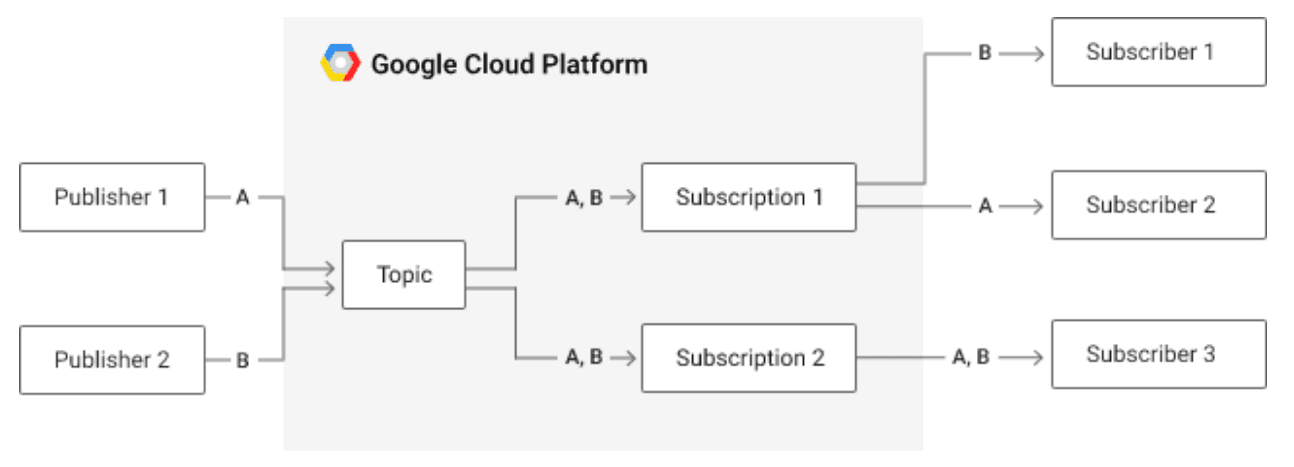
Credit: https://cloud.google.com/pubsub/architecture
Google makes each Ethereum dataset available as a public topic, to which we can register a subscription. Each message on this topic is equivalent to a row in ClickHouse.
The first 10GB of throughput data in Pub/Sub is free, after which Google charges ~$40/TB. With around 120GB of Ethereum traces per month, this is around ~$4/month. Importantly, we do not retain the acknowledged messages once they are delivered to Kafka and hold only seven days of unacknowledged messages in our subscription (also free).
The public topic names follow the following naming so you can easily locate them:
projects/crypto-public-data/topics/crypto_{chain}.{table_name}
where,
chain can be one of ethereum, bitcoin, zcash, litecoin, dogecoin, or dash. For our purposes, we use ethereum.
table_name can be one of blocks or transactions. Additionally, for Ethereum: logs, token_transfers, traces, contracts, and tokens are supported. We provide configuration for blocks, transactions, traces and contracts, focusing on blocks in the example elbow.
Assuming you have installed Google Cloud CLI, authenticated and selected a project for which you have the relevant permissions, a subscription with the id ethereum.blocks can be created with the following command:
gcloud pubsub subscriptions create ethereum.blocks --topic=crypto_ethereum.blocks --topic-project=crypto-public-data --ack-deadline 60
Created subscription [projects/pmm-project-377716/subscriptions/ethereum.blocks].
Users can confirm messages are being delivered using the following command:
gcloud pubsub subscriptions pull ethereum.traces --format=json
[
{
"ackId": "FixdRkhRNxkIaFEOT14jPzUgKEUSBAgUBXx9dUJfdV1acGhRDRlyfWB9YggQUABCUi8KURkLb1xWdRVgDQGo4vPhXHgzBgtEVHheUhwIa1lUdQBWBTG5nJjfycfSPxh5a6TAyY87SOnenLpiZiw9XxJLLD5-IC1FQV5AEkwrGERJUytDCypYEU4EISE-MD5FU0RQBg",
"message": {
"attributes": {
"item_id": "block_0x91af5d194d1f6450597cfe84895692cba1615487528f9aeea81bb6caecf24049",
"item_timestamp": "2023-06-13T16:19:11Z"
},
"data": "eyJ0eXBlIjoiYmxvY2siLCJudW1iZXIiOjE3NDcyMjE1LCJoYXNoIjoiMHg5MWFmNWQxOTRkMWY2NDUwNTk3Y2ZlODQ4OTU2OTJjYmExNjE1NDg3NTI4ZjlhZWVhODFiYjZjYWVjZjI0MDQ5IiwicGFyZW50X2hhc2giOiIweGI0MGQ3YWExNzJmNWZmNjZhNGE5YzY1ZGE0ODY4NGI1MWVlMjI2NTU4NmJkYzZlN2RiYThkMjMzNzMzYWEzNjUiLCJub25jZSI6IjB4MDAwMDAwMDAwMDAwMDAwMCIsInNoYTNfdW5jbGVzIjoiMHgxZGNjNGRlOGRlYzc1ZDdhYWI4NWI1NjdiNmNjZDQxYWQzMTI0NTFiOTQ4YTc0MTNmMGExNDJmZDQwZDQ5MzQ3IiwibG9nc19ibG9vbSI6IjB4MDhmZjFiMjZlMGEwYTVlYzUxMGM5NDhhZWEwYzBmNjMxMWVmMTkzZmVjMWEzMmE1MjMwZGMwNWJjNDdjNGVjMDE0NDcxYjgyYzQ3ODMxMzUwZjVmNTMzODc5MWM0NTg0M2FkMThjMGNjODAzYmVhNTQ1MjA3ZWEyOTBhOTczMTEwZDY3NzAwOTE5MGNjODJkNGQzMzU2ZWUwMDg1MmJhZDIwODkwODY1MTI1MzljNDgwYzcyZmMwNDhjZTUxNDIxNWFiYWM2Y2YwYjAzYWY0MjI0NDEzODA3MTIwYzQ5Y2EzZmM4NWFiMDBjOTk2YzI2OWFjMTE3ZmM2MDVjMmYzYzBiOGE0NDQxMzgyNmE5NDEyNGVkODg5ZTg5NjNhZjI2NTEyYTE0MzFiYmIxZTI1ZjhkMjkzNzRhMDliNDUyYmY4YWIyMjYzZTljY2QyMDc1MTYwMzRjY2RiNDAxMjVkMmE2NDNkODIxMGYyODA0MGYwMDcwNjYzMjRjY2MwMDVjYzJjZWNjNmE2NzhhNGFjYjIwNDE4YzUzZDYyNzEyZTIxY2NjMGI2YTE2MmIwYTE0MTNlNTkxNDI4OTMyMjEwZjY4M2JhMDZjZDlkODg2Mjg4MTA3NTA2YjBjMDliYmM2NGY2OTE2ODliNTJiMTZmNDk0MDllNjE1NDgyOTdjNDEiLCJ0cmFuc2FjdGlvbnNfcm9vdCI6IjB4YTUyOTA4YWFkYWRhNzkwZWFjYjYyNzFlZTZhMTRiMjE1ZTVkZGJmZDFhNTcwZmUzNDk2MWIyYTE4YTliMDg4NyIsInN0YXRlX3Jvb3QiOiIweGE5OGM0YTMzNWYzYzE1ZTQ4NGE3YjY0MmMxZTMyMzNlMGFlM2ExZjFhZWYwZTYxZWRmMTFmYWRhNjU3YjZjMWYiLCJyZWNlaXB0c19yb290IjoiMHg5MGJkYzkwMTY3OTM5Yzg3MjQ4ZDgzYzQ3Nzk0OTJkNWYyNmY0NTlmZWU3ZGM2ZmJhNDAxMmU4NDA3YjliOTk1IiwibWluZXIiOiIweDM4OGM4MThjYThiOTI1MWIzOTMxMzFjMDhhNzM2YTY3Y2NiMTkyOTciLCJkaWZmaWN1bHR5IjowLCJ0b3RhbF9kaWZmaWN1bHR5Ijo1ODc1MDAwMzcxNjU5ODM2MDAwMDAwMCwic2l6ZSI6NTIxMzUsImV4dHJhX2RhdGEiOiIweDYyNjU2MTc2NjU3MjYyNzU2OTZjNjQyZTZmNzI2NyIsImdhc19saW1pdCI6MzAwMDAwMDAsImdhc191c2VkIjoxMjg3Njk1NCwidGltZXN0YW1wIjoxNjg2NjczMTUxLCJ0cmFuc2FjdGlvbl9jb3VudCI6MTg3LCJiYXNlX2ZlZV9wZXJfZ2FzIjozODA2NTQ1NTgwMywid2l0aGRyYXdhbHNfcm9vdCI6IjB4YzYyMjVmYzYwMmFkMDZiNDk5ZmE5OTI0MjNkNjg3MmFlODJkZDM5YTZkZmY1MmQwMWQyZWIyMzQyYmMwMmRiZiIsIndpdGhkcmF3YWxzIjpbXSwiaXRlbV9pZCI6ImJsb2NrXzB4OTFhZjVkMTk0ZDFmNjQ1MDU5N2NmZTg0ODk1NjkyY2JhMTYxNTQ4NzUyOGY5YWVlYTgxYmI2Y2FlY2YyNDA0OSIsIml0ZW1fdGltZXN0YW1wIjoiMjAyMy0wNi0xM1QxNjoxOToxMVoifQo=",
"messageId": "7917619753580778",
"publishTime": "2023-06-13T16:22:52.230Z"
}
}
]
Note our main message payload here is base64 encoded. We can confirm the payload structure with a little bit of bash.
gcloud pubsub subscriptions pull ethereum.blocks --format=json | jq -r '.[].message.data' | base64 -d | jq
{
"type": "block",
"number": 17472215,
"hash": "0x91af5d194d1f6450597cfe84895692cba1615487528f9aeea81bb6caecf24049",
"parent_hash": "0xb40d7aa172f5ff66a4a9c65da48684b51ee2265586bdc6e7dba8d233733aa365",
"nonce": "0x0000000000000000",
"sha3_uncles": "0x1dcc4de8dec75d7aab85b567b6ccd41ad312451b948a7413f0a142fd40d49347",
"logs_bloom": "0x08ff1b26e0a0a5ec510c948aea0c0f6311ef193fec1a32a5230dc05bc47c4ec014471b82c47831350f5f5338791c45843ad18c0cc803bea545207ea290a973110d677009190cc82d4d3356ee00852bad2089086512539c480c72fc048ce514215abac6cf0b03af4224413807120c49ca3fc85ab00c996c269ac117fc605c2f3c0b8a44413826a94124ed889e8963af26512a1431bbb1e25f8d29374a09b452bf8ab2263e9ccd207516034ccdb40125d2a643d8210f28040f007066324ccc005cc2cecc6a678a4acb20418c53d62712e21ccc0b6a162b0a1413e591428932210f683ba06cd9d886288107506b0c09bbc64f691689b52b16f49409e61548297c41",
"transactions_root": "0xa52908aadada790eacb6271ee6a14b215e5ddbfd1a570fe34961b2a18a9b0887",
"state_root": "0xa98c4a335f3c15e484a7b642c1e3233e0ae3a1f1aef0e61edf11fada657b6c1f",
"receipts_root": "0x90bdc90167939c87248d83c4779492d5f26f459fee7dc6fba4012e8407b9b995",
"miner": "0x388c818ca8b9251b393131c08a736a67ccb19297",
"difficulty": 0,
"total_difficulty": 58750003716598360000000,
"size": 52135,
"extra_data": "0x6265617665726275696c642e6f7267",
"gas_limit": 30000000,
"gas_used": 12876954,
"timestamp": 1686673151,
"transaction_count": 187,
"base_fee_per_gas": 38065455803,
"withdrawals_root": "0xc6225fc602ad06b499fa992423d6872ae82dd39a6dff52d01d2eb2342bc02dbf",
"withdrawals": [
],
"item_id": "block_0x91af5d194d1f6450597cfe84895692cba1615487528f9aeea81bb6caecf24049",
"item_timestamp": "2023-06-13T16:19:11Z"
}
Alternatively, users can create a subscription and confirm message delivery through the Google console, as shown below. Note how we use a pull strategy for the subscription (default in earlier command), compatible with the Confluent Pub/Sub connector. This is more efficient in comparison to a push strategy and minimizes latency while not requiring a Confluent endpoint to be exposed to the public internet.
We do not tweak the default retention period of 7 days for unacknowledged messages (messages acknowledged by the connector will be removed immediately) but do modify the acknowledgement deadline, setting it to be 60s (see below).
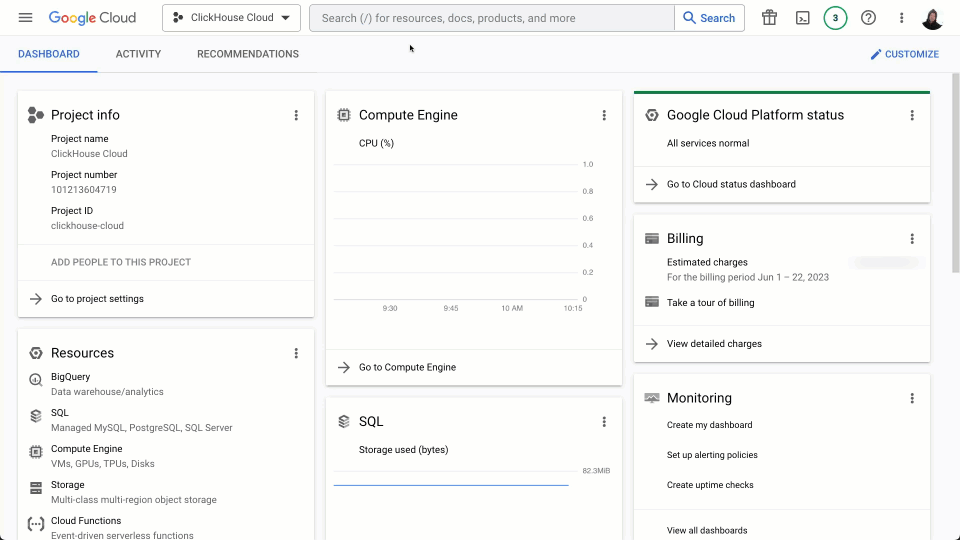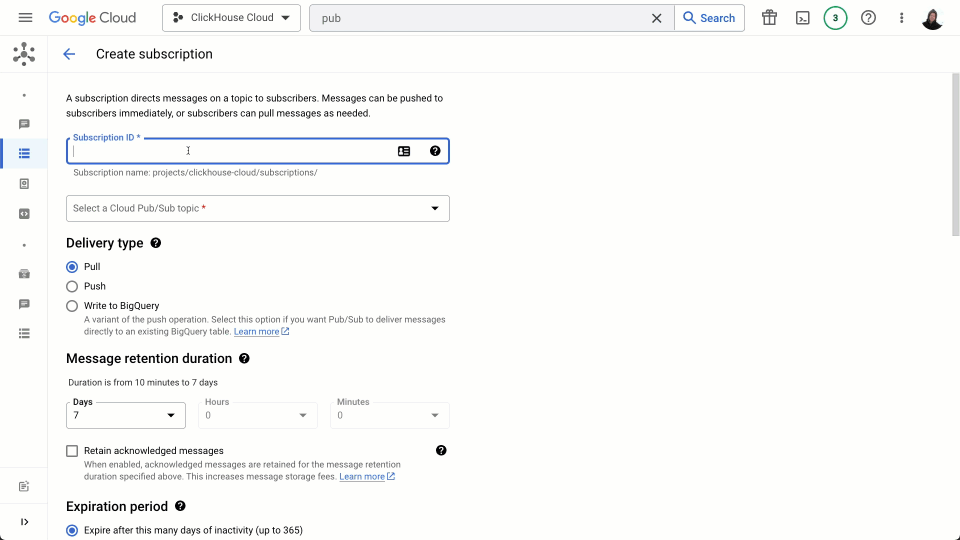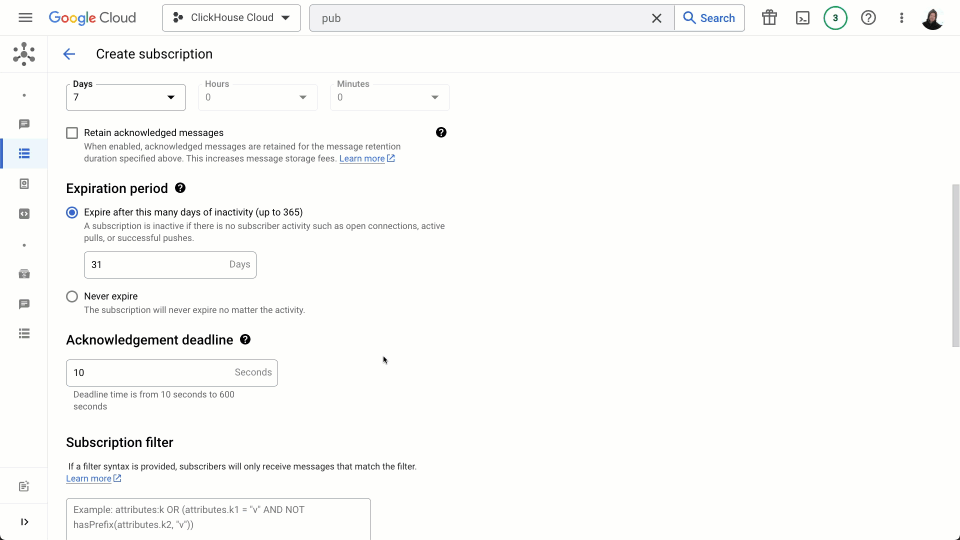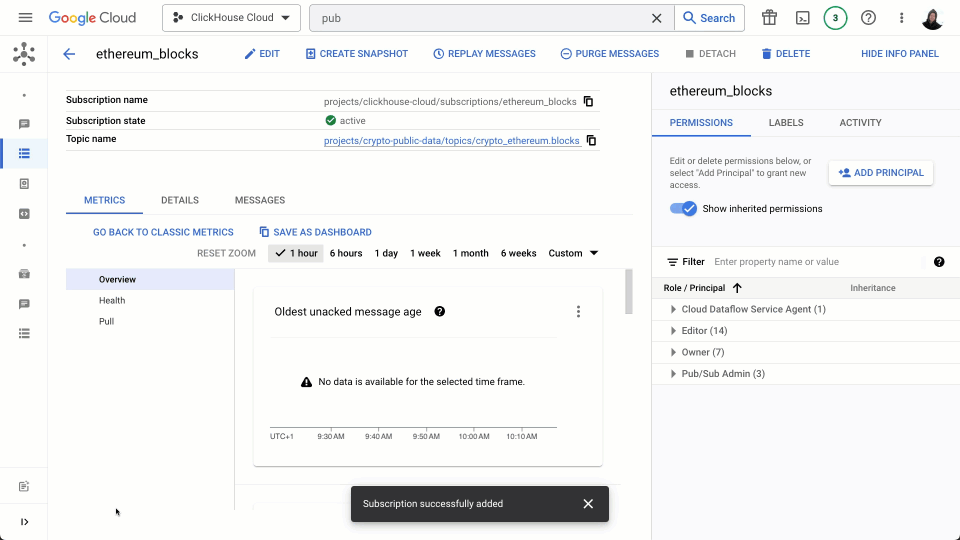
The above can be adapted to other Ethereum data types as required e.g. traces.
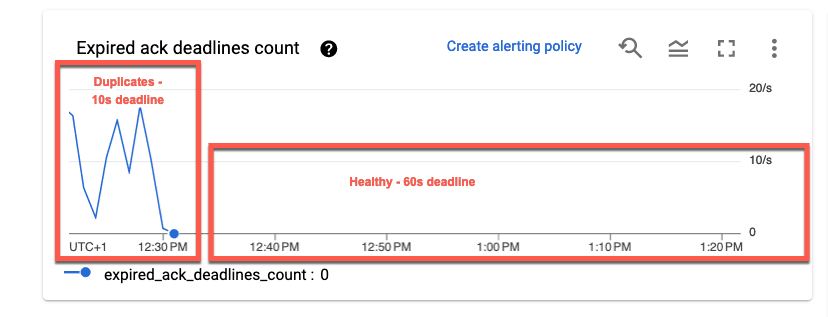
In the above examples we set the acknowledgement deadline to 60 seconds. Messages which are not acknowledged after this period will be resent. During testing of the Pub/Sub connector, we found the default value of 10s resulted in the delivery of duplicate messages, with the connector unable to acknowledge messages in sufficient time. Increasing this value aligns with Confluent’s recommendations. A higher value does potentially delay the delivery of failed messages, but this is unlikely to impact our use case. For users looking to tune this value, a high count of expired acknowledgements can indicate duplicates. This can be viewed from the Health panel of a subscription. As shown below, a value of 10s resulted in duplicates in our use case.
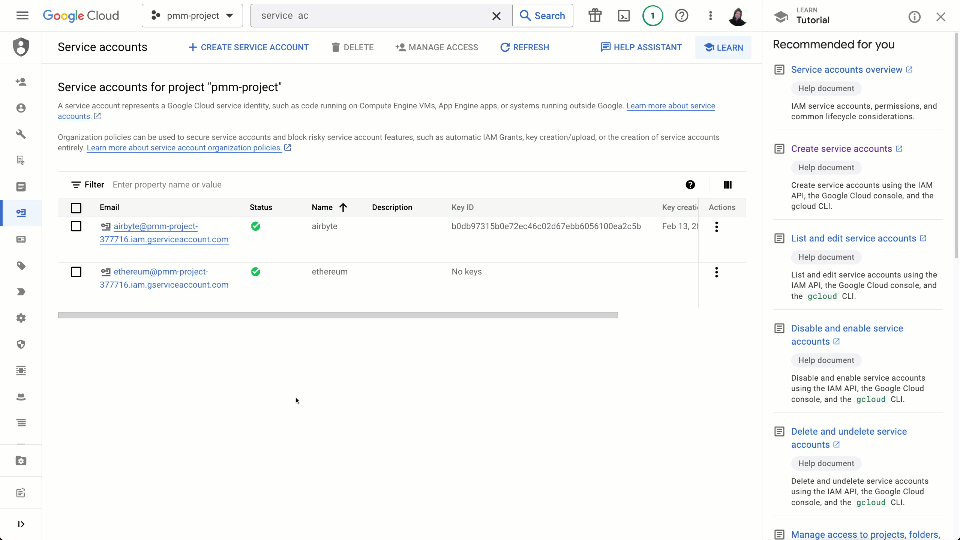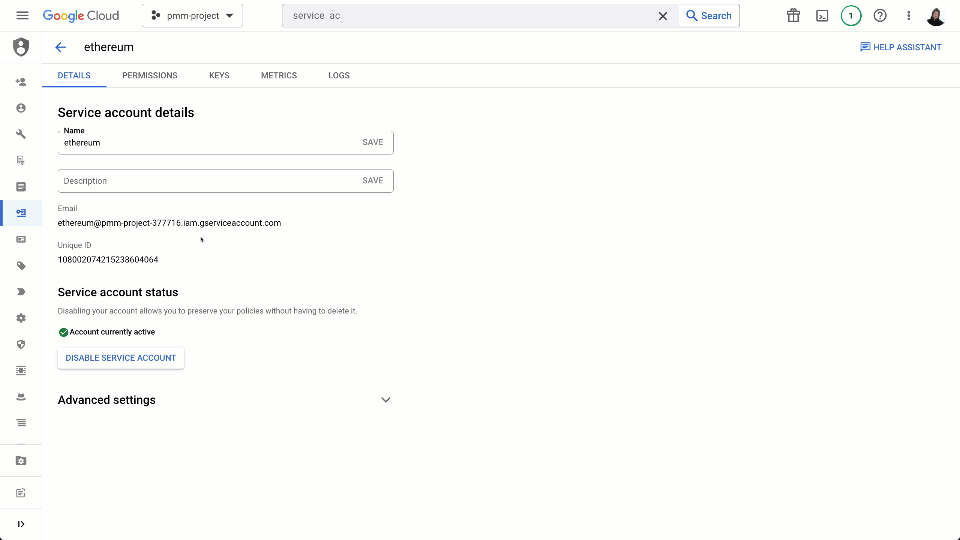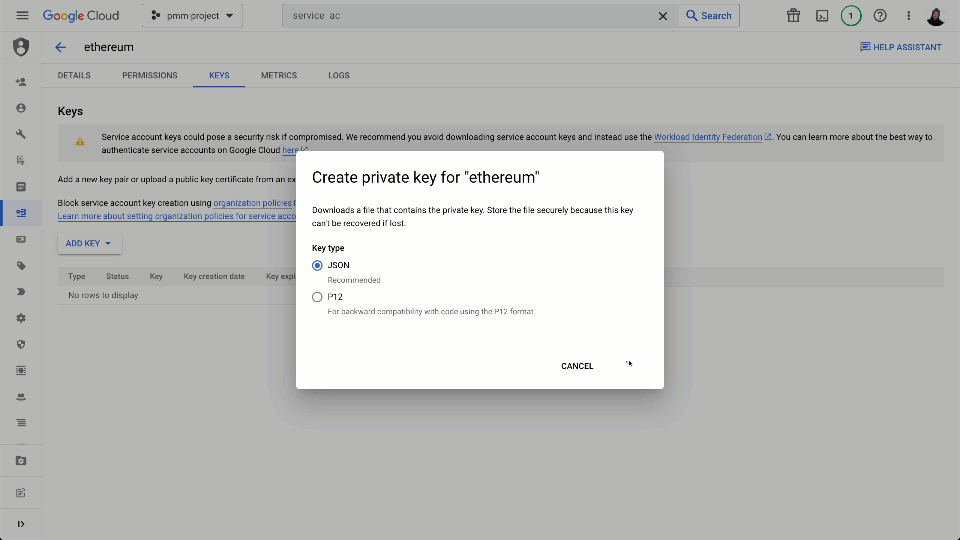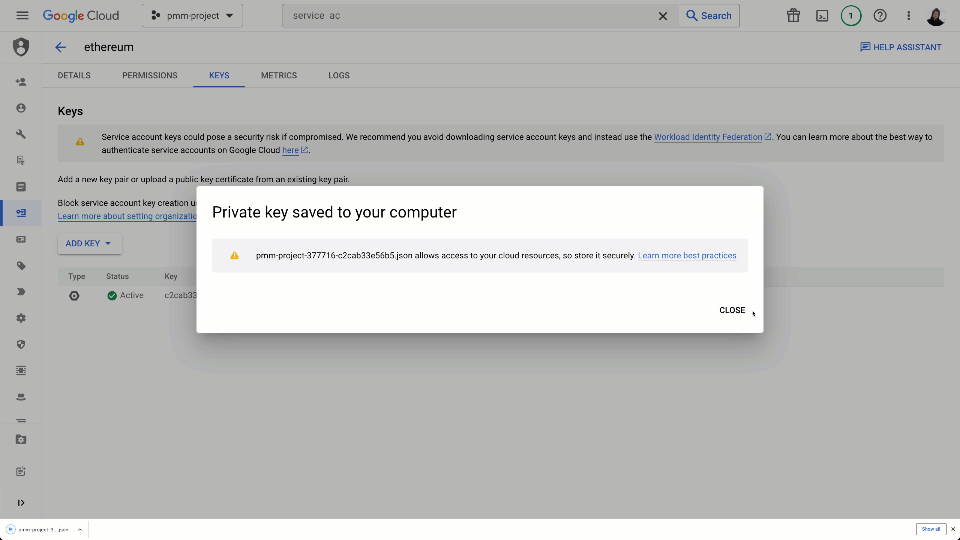
Create service credentials
In order for external services to read messages from our Pub/Sub subscription, we need to create a service account and grant this the required subscriber role. The steps for this are documented here and shown below:
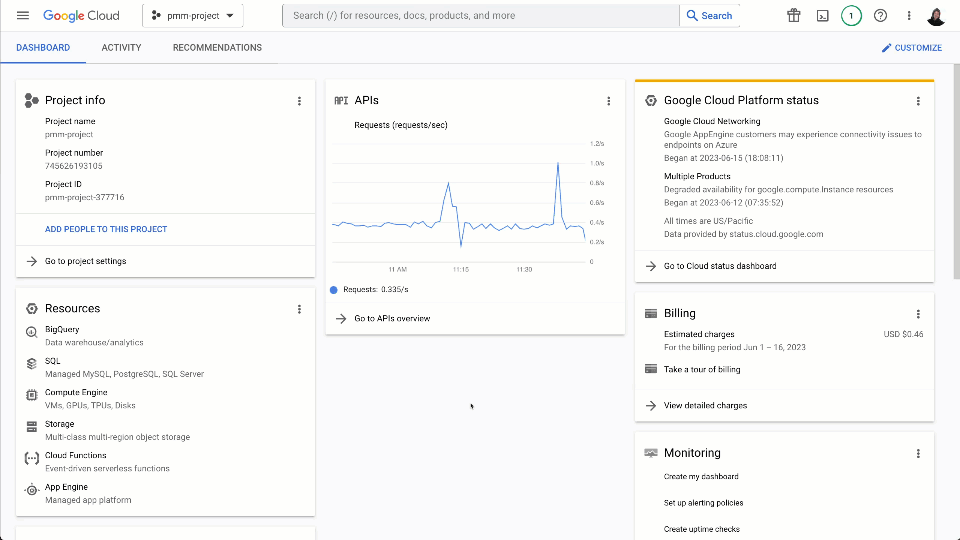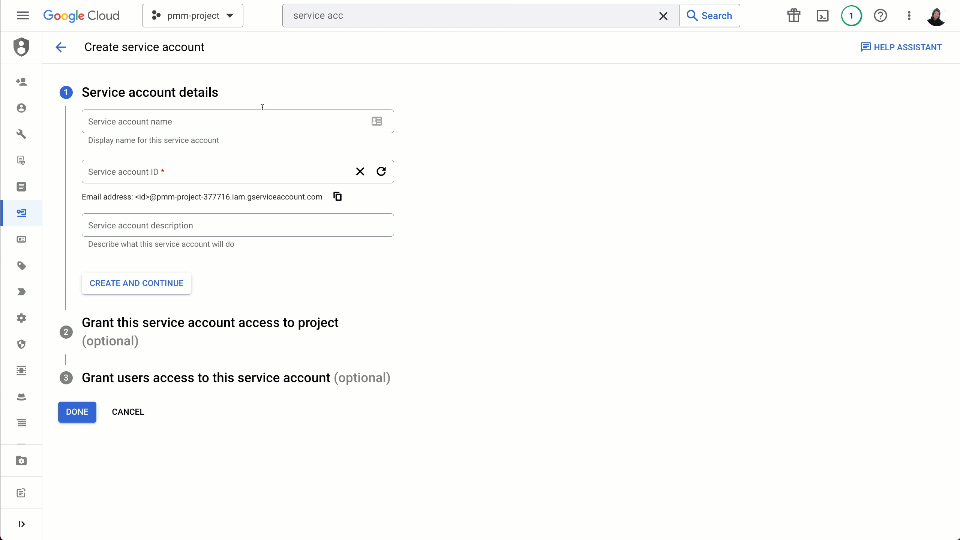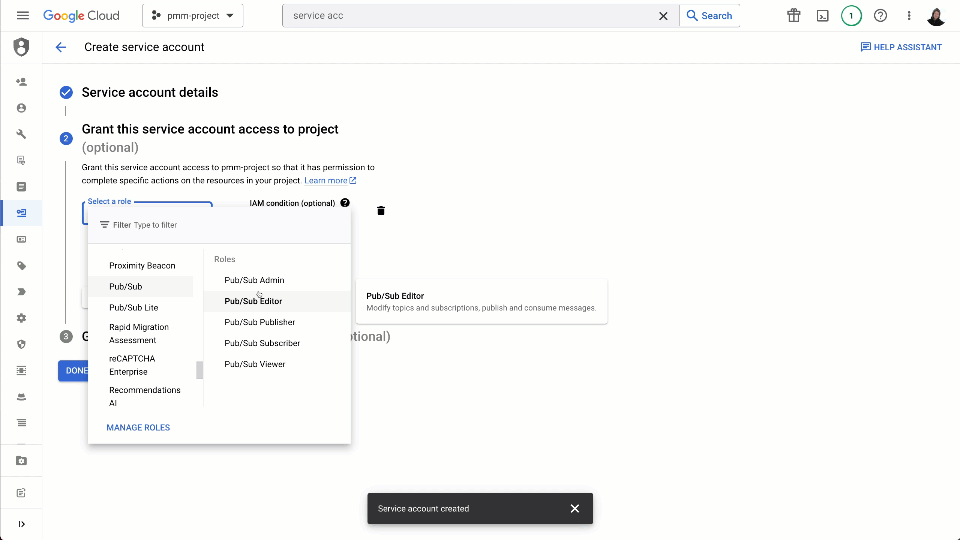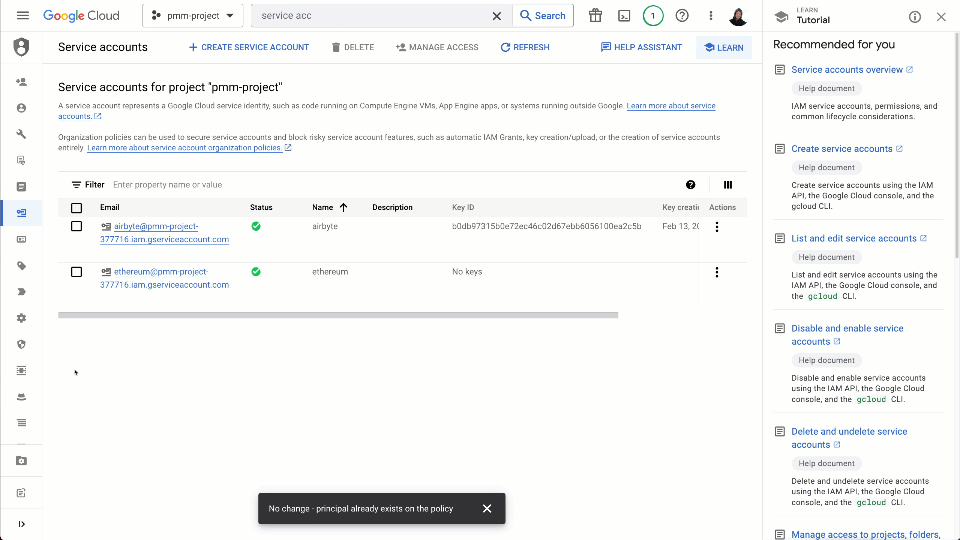
Alternatively, users can utilize the following gcloud commands:
# create service account
gcloud iam service-accounts create ethereum --display-name="ethereum"
#assign Pub/Sub Subscriber role
gcloud projects add-iam-policy-binding <project_id> --member="serviceAccount:ethereum@<project_id>.iam.gserviceaccount.com" --role="roles/pubsub.subscriber"
The subscription’s connection details, and the above credentials, can be exported as a single key for sharing with our Confluent Cloud Pub/Sub Connector as shown below.
Deploy a Pub/Sub Connector in Confluent Cloud
The Kafka Connect Google Cloud Pub/Sub Source Connector reads messages from a Pub/Sub topic, using a pull strategy, and writes them to a Kafka topic. This delivery of messages is asynchronous, i.e., their availability on the Pub/Sub subscription and delivery to the connector is independent. This connector provides at-least-once semantics and no ordering guarantees. These properties are sufficient for our use case - rows can occur out of order, and rare duplicates are unlikely to impact later data analysis.
Before deploying a Pub/Sub Connector in Confluent Cloud, ensure you have the following details:
- The project Id in which your Pub/Sub subscription exists
- The original topic id in Pub/Sub - crypto_ethereum.blocks
- The subscription id - **ethereum.blocks **if the above
- The exported services key is obtained in the last step.
These can be adapted to the target data type. In the example below, we use these details to create a Pub/Sub connector instance, assigning it one task and creating a Kafka topic block_messages.
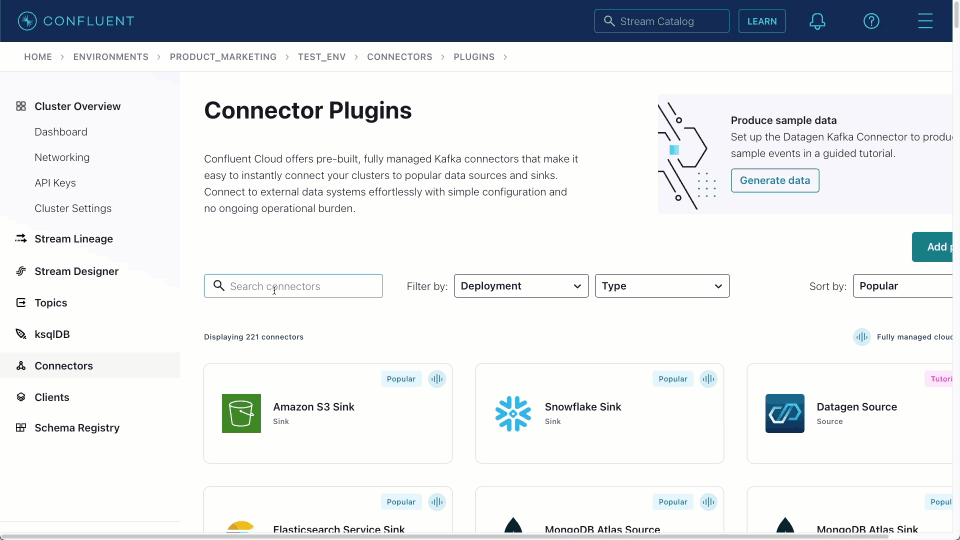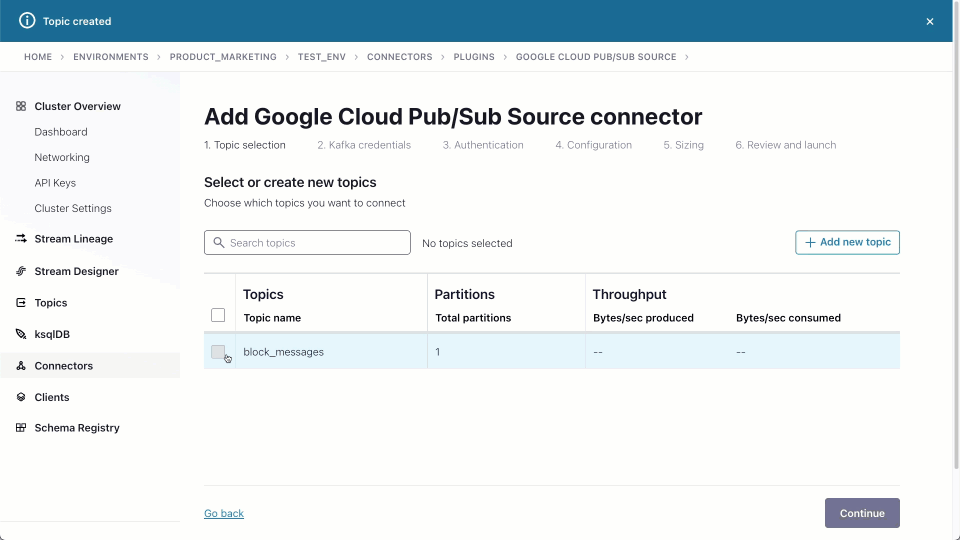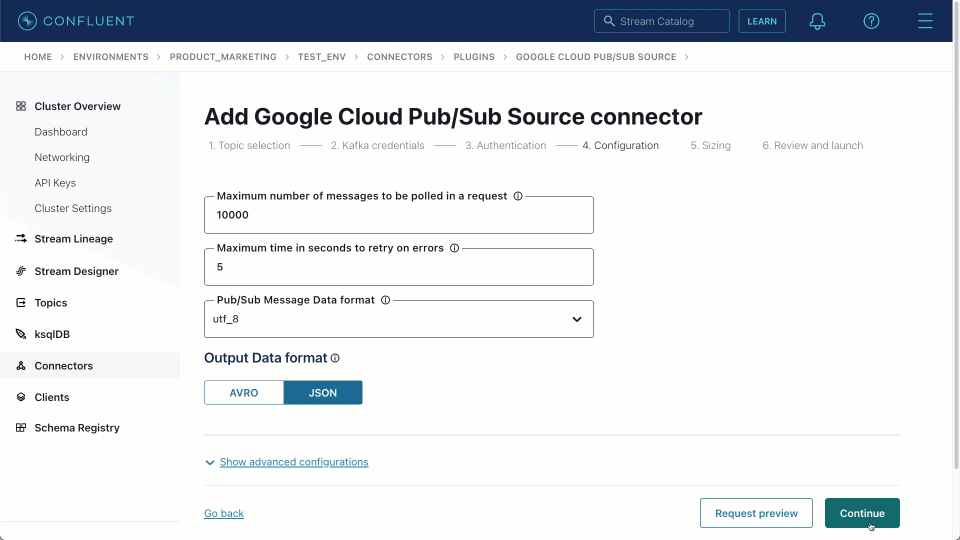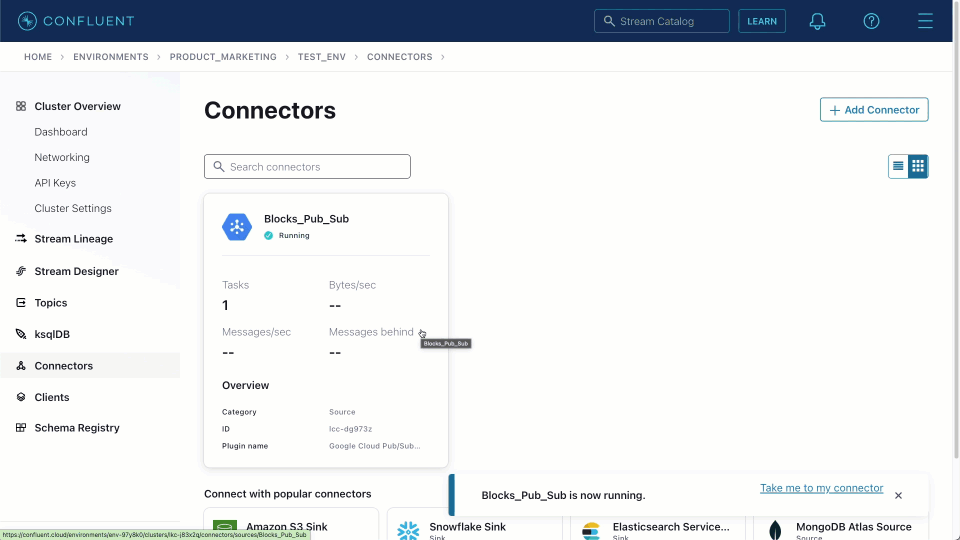
Once created, we can navigate to the target block_messages topic and sample messages, as shown below. This source connector produces messages in JSON format with no schema.
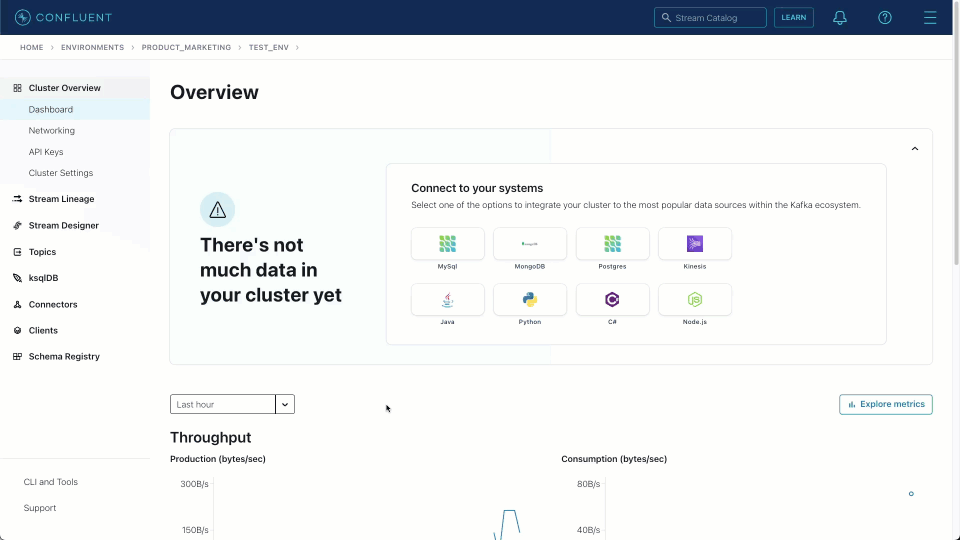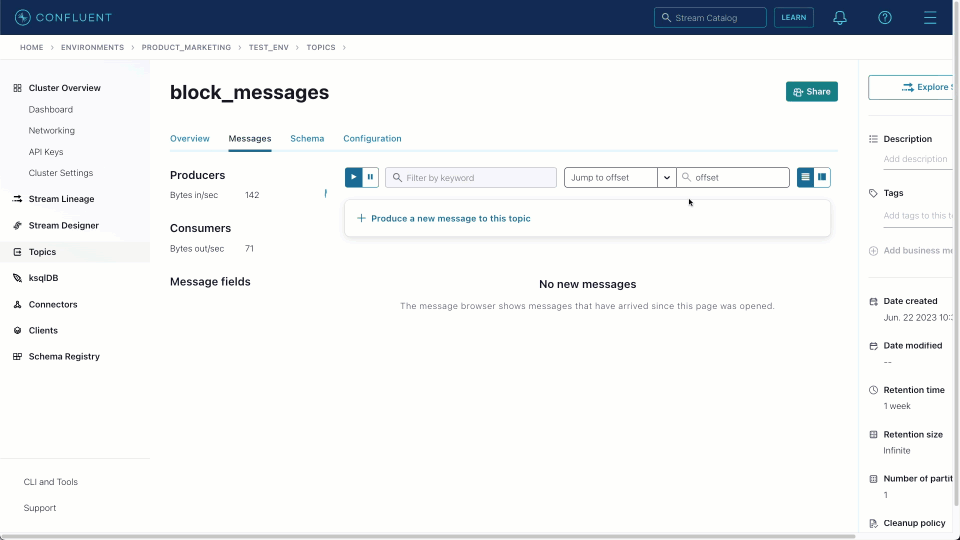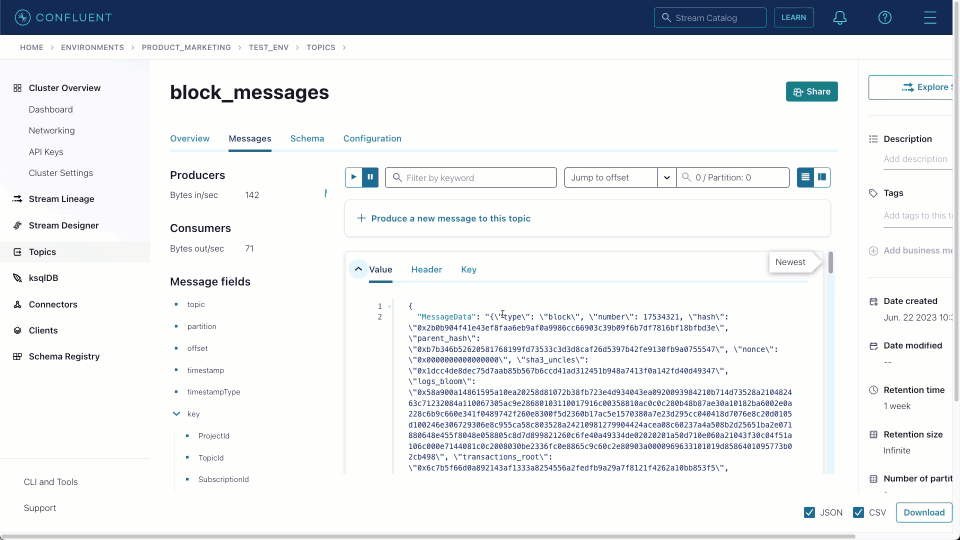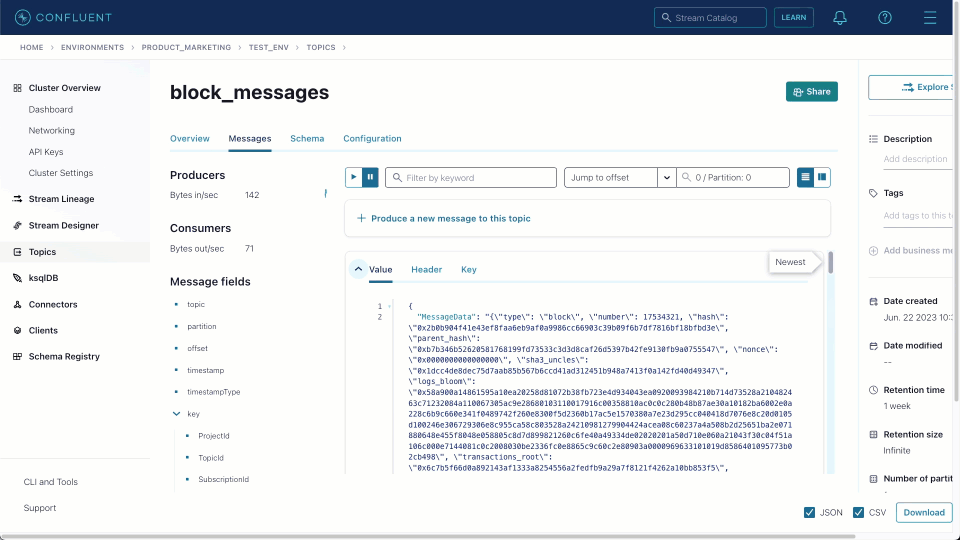
Prior to sending this data to ClickHouse, we need to ensure this data is correctly formatted and our target table exists.
Prepare ClickHouse
Create table
The schema proposed for our blocks table is shown below.
SET flatten_nested=0
CREATE TABLE ethereum.blocks
(
`number` UInt32 CODEC(Delta(4), ZSTD(1)),
`hash` String,
`parent_hash` String,
`nonce` String,
`sha3_uncles` String,
`logs_bloom` String,
`transactions_root` String,
`state_root` String,
`receipts_root` String,
`miner` String,
`difficulty` Decimal(38, 0),
`total_difficulty` Decimal(38, 0),
`size` UInt32 CODEC(Delta(4), ZSTD(1)),
`extra_data` String,
`gas_limit` UInt32 CODEC(Delta(4), ZSTD(1)),
`gas_used` UInt32 CODEC(Delta(4), ZSTD(1)),
`timestamp` DateTime CODEC(Delta(4), ZSTD(1)),
`transaction_count` UInt16,
`base_fee_per_gas` UInt64,
`withdrawals_root` String,
`withdrawals` Nested(index Int64, validator_index Int64, address String, amount String)
)
ENGINE = MergeTree
ORDER BY timestamp
Equivalent schemas for the other data types can be found here
This above schema is alittle different than the schema proposed in our earlier blog post, with the columns withdrawals_root and withdrawals recently added to the specification[1][2]. We also set the setting flatten_nested to 0 to preserve the Nested structure of the withdrawals column. This allows us to insert this column as a nested JSON structure.
Below we show a message as held on the Kafka topic block_messages.
{
"MessageData": "{\"type\": \"block\", \"number\": 17477635, \"hash\": \"0x6c0e971090f48adfc04303b302e5f14895c104e9a60ec6126b96579194a2c14b\", \"parent_hash\": \"0xdf90825e84c50550be12143d998090883bb92deecbdb5bd84235023f8fcad9c5\", \"nonce\": \"0x0000000000000000\", \"sha3_uncles\": \"0x1dcc4de8dec75d7aab85b567b6ccd41ad312451b948a7413f0a142fd40d49347\", \"logs_bloom\": \"0xc0210585c002844400c000f0a011e324186195244041200041031242148ec051808106400d3030600c384180050003c20a41078488403c3022880000147ea8a348110c0ad50001086800430b83d120e89010000024445881003000848023a010562881021302a60118003c19400c099206904e7008b104301214001042fc007608271140460524a0904e3142174c250174070921a90006686244236043b080468f90b161e00364a20a8b48b15cb205a50c44082cc100040b02812017008c016501800162115c06022539a2401c0ef20020680a00002c201c0010c8920210a0000895a11c0a1844860a00208045810604a0301013015ea86219aa98831e027440\", \"transactions_root\": \"0xefaf112480278167af853214fc55a7fcaff4a879c1e97357be77d95fd114c046\", \"state_root\": \"0x2b5fa13bcecb133578e5e6c328944a551ccb497275ba4263d5b52d9f88bab2e1\", \"receipts_root\": \"0x2ef3cb89ab21d6d861777087ee1791c5a6197d5b6e9f8e0228717b064ad60efe\", \"miner\": \"0xbaf6dc2e647aeb6f510f9e318856a1bcd66c5e19\", \"difficulty\": 0, \"total_difficulty\": 58750003716598352816469, \"size\": 38091, \"extra_data\": \"0x4d616465206f6e20746865206d6f6f6e20627920426c6f636b6e6174697665\", \"gas_limit\": 30000000, \"gas_used\": 6452970, \"timestamp\": 1686739043, \"transaction_count\": 83, \"base_fee_per_gas\": 14420785730, \"withdrawals_root\": \"0x71fbe84200d685e619f28a7f3aedfcacadf5f8bde9be2c20f9d146110f66e558\", \"withdrawals\": [{\"index\": 7083728, \"validator_index\": 649036, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 13657565}, {\"index\": 7083729, \"validator_index\": 649037, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 13749238}, {\"index\": 7083730, \"validator_index\": 649038, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 13636849}, {\"index\": 7083731, \"validator_index\": 649039, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 13700532}, {\"index\": 7083732, \"validator_index\": 649040, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 13647987}, {\"index\": 7083733, \"validator_index\": 649041, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 13712208}, {\"index\": 7083734, \"validator_index\": 649042, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 13748808}, {\"index\": 7083735, \"validator_index\": 649043, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 13720541}, {\"index\": 7083736, \"validator_index\": 649044, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 49166908}, {\"index\": 7083737, \"validator_index\": 649045, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 13747911}, {\"index\": 7083738, \"validator_index\": 649046, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 13701501}, {\"index\": 7083739, \"validator_index\": 649047, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 13695932}, {\"index\": 7083740, \"validator_index\": 649048, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 13708868}, {\"index\": 7083741, \"validator_index\": 649049, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 13676192}, {\"index\": 7083742, \"validator_index\": 649050, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 13594476}, {\"index\": 7083743, \"validator_index\": 649051, \"address\": \"0x07fac54a901409fe10e56c899be3dcf2471ae321\", \"amount\": 13716126}], \"item_id\": \"block_0x6c0e971090f48adfc04303b302e5f14895c104e9a60ec6126b96579194a2c14b\", \"item_timestamp\": \"2023-06-14T10:37:23Z\"}",
"AttributesMap": {
"item_id": "block_0x6c0e971090f48adfc04303b302e5f14895c104e9a60ec6126b96579194a2c14b",
"item_timestamp": "2023-06-13T18:44:47Z"
}
}
The main body is held in the MessageData field as an escaped JSON string. This format is incompatible with the above schema and requires transformation before insertion. For this, we use a materialized view.
Transforming messages with materialized views
Materialized views in ClickHouse can be used to transform rows at insert time. The view triggers at insert time for a table receiving blocks of rows, performing a SELECT operation over the block with the results sent to a target table.

This approach relies on a table with a compatible schema to receive our insert messages. This table block_messages is shown below.
CREATE TABLE ethereum.block_messages
(
`MessageData` String,
`AttributesMap` Tuple(item_id String, item_timestamp String)
)
ENGINE = Null
As shown, this table uses the Null table engine. This ensures the original raw inserted rows are not retained as they are not required beyond initial debugging. The materialized view will still trigger on inserts to this table, forwarding transforming messages to our desired target table blocks.
The materialized view blocks_mv, which triggers when rows are inserted into the table block_messages, is shown below. The SELECT query of the above view transforms these rows into the format expected by the table ethereum.blocks and the schema presented earlier. This target table is specified via the TO syntax.
CREATE MATERIALIZED VIEW ethereum.blocks_mv TO ethereum.blocks
(
`number` UInt32,
`hash` String,
`parent_hash` String,
`nonce` String,
`sha3_uncles` String,
`logs_bloom` String,
`transactions_root` String,
`state_root` String,
`receipts_root` String,
`miner` String,
`difficulty` Decimal(38, 0),
`total_difficulty` Decimal(38, 0),
`size` UInt32,
`extra_data` String,
`gas_limit` UInt32,
`gas_used` UInt32,
`timestamp` DateTime,
`transaction_count` UInt16,
`base_fee_per_gas` UInt64,
`withdrawals_root` String,
`withdrawals` Nested(index UInt64, validator_index Int64, address String, amount UInt64)
) AS
SELECT
JSONExtract(MessageData, 'number', 'UInt32') AS number,
JSONExtractString(MessageData, 'hash') AS hash,
JSONExtractString(MessageData, 'parent_hash') AS parent_hash,
JSONExtractString(MessageData, 'nonce') AS nonce,
JSONExtractString(MessageData, 'sha3_uncles') AS sha3_uncles,
JSONExtractString(MessageData, 'logs_bloom') AS logs_bloom,
JSONExtractString(MessageData, 'transactions_root') AS transactions_root,
JSONExtractString(MessageData, 'state_root') AS state_root,
JSONExtractString(MessageData, 'receipts_root') AS receipts_root,
JSONExtractString(MessageData, 'miner') AS miner,
JSONExtract(MessageData, 'difficulty', 'Decimal(38, 0)') AS difficulty,
JSONExtract(MessageData, 'total_difficulty', 'Decimal(38, 0)') AS total_difficulty,
JSONExtract(MessageData, 'size', 'UInt32') AS size,
JSONExtractString(MessageData, 'extra_data') AS extra_data,
JSONExtract(MessageData, 'gas_limit', 'UInt32') AS gas_limit,
JSONExtract(MessageData, 'gas_used', 'UInt32') AS gas_used,
JSONExtract(MessageData, 'timestamp', 'UInt64') AS timestamp,
JSONExtract(MessageData, 'transaction_count', 'UInt16') AS transaction_count,
JSONExtract(MessageData, 'base_fee_per_gas', 'UInt64') AS base_fee_per_gas,
JSONExtract(MessageData, 'withdrawals_root', 'String') AS withdrawals_root,
JSONExtract(MessageData, 'withdrawals', 'Nested(index UInt64, validator_index Int64, address String, amount UInt64)') AS withdrawals
FROM ethereum.block_messages
SETTINGS allow_simdjson = 0
Here, we rely on the JSONExtract family of functions to extract fields from the JSON string column MessageData. We appropriate variants to ensure the values are correctly cast, e.g., JSONExtract(MessageData, 'difficulty', 'Decimal(38, 0)') AS difficulty extracts the field difficulty from the MessageData column as a `Decimal(38, 0)" and alias' the result as "difficulty". The result of this SELECT is a set of results compatible with our earlier table schema.
In the above, we use the setting
allow_simdjson=0. This is necessary as the default simdjson implementation for parsing JSON cannot parse integers larger than UInt64. Setting this value to 0 enables RapidJSON parsing, which whilst not as performant, is sufficient for our needs. The alternativevisitParamfunctions require more complex expressions and are less lenient with respect to the spacing present in our JSON string.
To test this workflow, we can insert a message into the table block_messages as JSONEachRow and confirm it is received by the target table blocks. In the example below, the file eth.json contains our earlier Kafka message in ndJSON format.
clickhouse-client --query "INSERT INTO ethereum.block_messages FORMAT JSONEachRow" < eth.json
SELECT *
FROM ethereum.block
FORMAT Vertical
Row 1:
──────
number: 17477635
hash: 0x6c0e971090f48adfc04303b302e5f14895c104e9a60ec6126b96579194a2c14b
parent_hash: 0xdf90825e84c50550be12143d998090883bb92deecbdb5bd84235023f8fcad9c5
nonce: 0x0000000000000000
sha3_uncles: 0x1dcc4de8dec75d7aab85b567b6ccd41ad312451b948a7413f0a142fd40d49347
logs_bloom: 0xc0210585c002844400c000f0a011e324186195244041200041031242148ec051808106400d3030600c384180050003c20a41078488403c3022880000147ea8a348110c0ad50001086800430b83d120e89010000024445881003000848023a010562881021302a60118003c19400c099206904e7008b104301214001042fc007608271140460524a0904e3142174c250174070921a90006686244236043b080468f90b161e00364a20a8b48b15cb205a50c44082cc100040b02812017008c016501800162115c06022539a2401c0ef20020680a00002c201c0010c8920210a0000895a11c0a1844860a00208045810604a0301013015ea86219aa98831e027440
transactions_root: 0xefaf112480278167af853214fc55a7fcaff4a879c1e97357be77d95fd114c046
state_root: 0x2b5fa13bcecb133578e5e6c328944a551ccb497275ba4263d5b52d9f88bab2e1
receipts_root: 0x2ef3cb89ab21d6d861777087ee1791c5a6197d5b6e9f8e0228717b064ad60efe
miner: 0xbaf6dc2e647aeb6f510f9e318856a1bcd66c5e19
difficulty: 0
total_difficulty: 58750003716598355985296
size: 38091
extra_data: 0x4d616465206f6e20746865206d6f6f6e20627920426c6f636b6e6174697665
gas_limit: 30000000
gas_used: 6452970
timestamp: 2023-06-14 10:37:23
transaction_count: 83
base_fee_per_gas: 14420785730
withdrawals_root: 0x71fbe84200d685e619f28a7f3aedfcacadf5f8bde9be2c20f9d146110f66e558
withdrawals: [(7083728,649036,'0x07fac54a901409fe10e56c899be3dcf2471ae321',13657565),(7083729,649037,'0x07fac54a901409fe10e56c899be3dcf2471ae321',13749238),(7083730,649038,'0x07fac54a901409fe10e56c899be3dcf2471ae321',13636849),(7083731,649039,'0x07fac54a901409fe10e56c899be3dcf2471ae321',13700532),(7083732,649040,'0x07fac54a901409fe10e56c899be3dcf2471ae321',13647987),(7083733,649041,'0x07fac54a901409fe10e56c899be3dcf2471ae321',13712208),(7083734,649042,'0x07fac54a901409fe10e56c899be3dcf2471ae321',13748808),(7083735,649043,'0x07fac54a901409fe10e56c899be3dcf2471ae321',13720541),(7083736,649044,'0x07fac54a901409fe10e56c899be3dcf2471ae321',49166908),(7083737,649045,'0x07fac54a901409fe10e56c899be3dcf2471ae321',13747911),(7083738,649046,'0x07fac54a901409fe10e56c899be3dcf2471ae321',13701501),(7083739,649047,'0x07fac54a901409fe10e56c899be3dcf2471ae321',13695932),(7083740,649048,'0x07fac54a901409fe10e56c899be3dcf2471ae321',13708868),(7083741,649049,'0x07fac54a901409fe10e56c899be3dcf2471ae321',13676192),(7083742,649050,'0x07fac54a901409fe10e56c899be3dcf2471ae321',13594476),(7083743,649051,'0x07fac54a901409fe10e56c899be3dcf2471ae321',13716126)]
1 row in set. Elapsed: 0.025 sec.
Equivalent materialized views for the other data types can be found here.
Deploy a ClickHouse Connector in Confluent Cloud
With our messages published to a Kafka topic and ClickHouse configured to receive and transform inserts, we can deploy the ClickHouse connector. The Confluent Cloud Custom Connector offering requires us to upload the connector package in a zip format. The latest package distribution can be downloaded from here.
We demonstrate this process below and note the important settings. A full list of steps is available in the Confluent documentation.
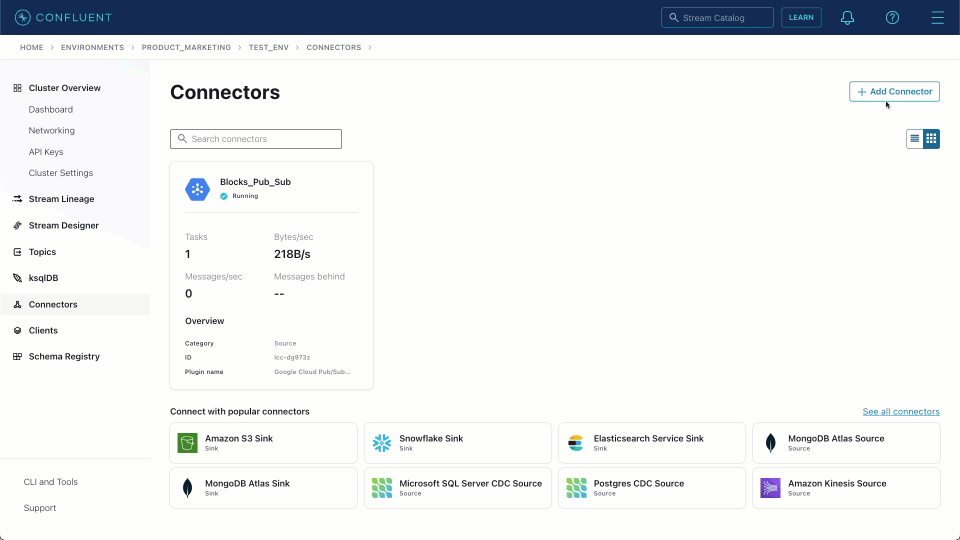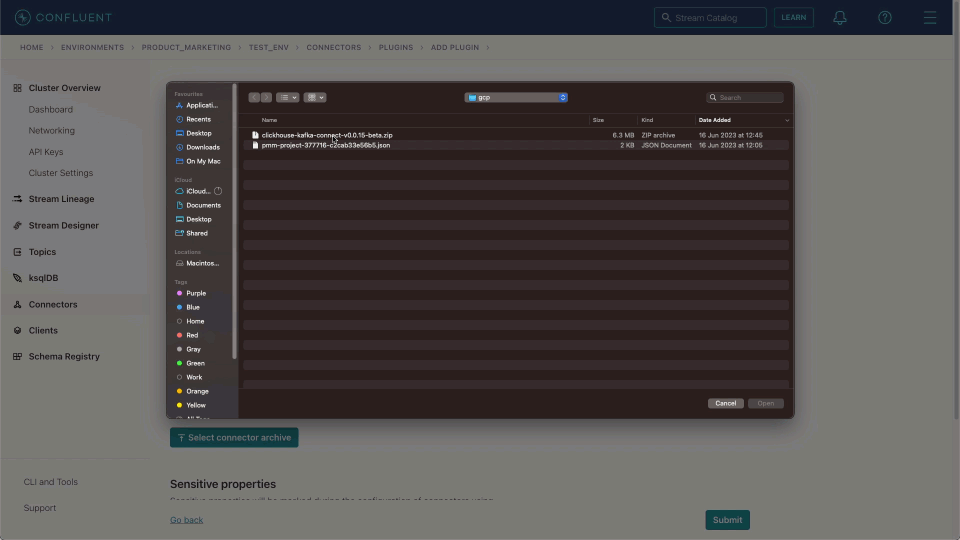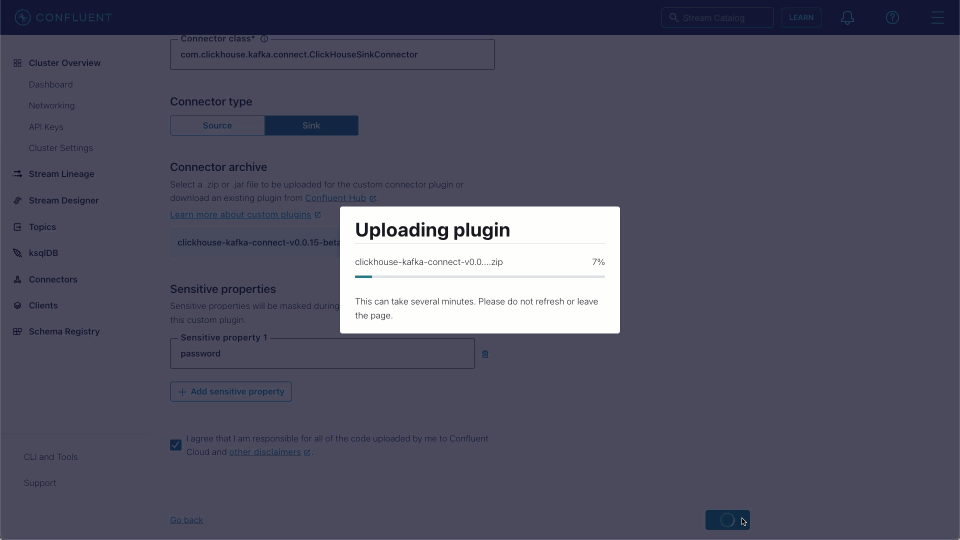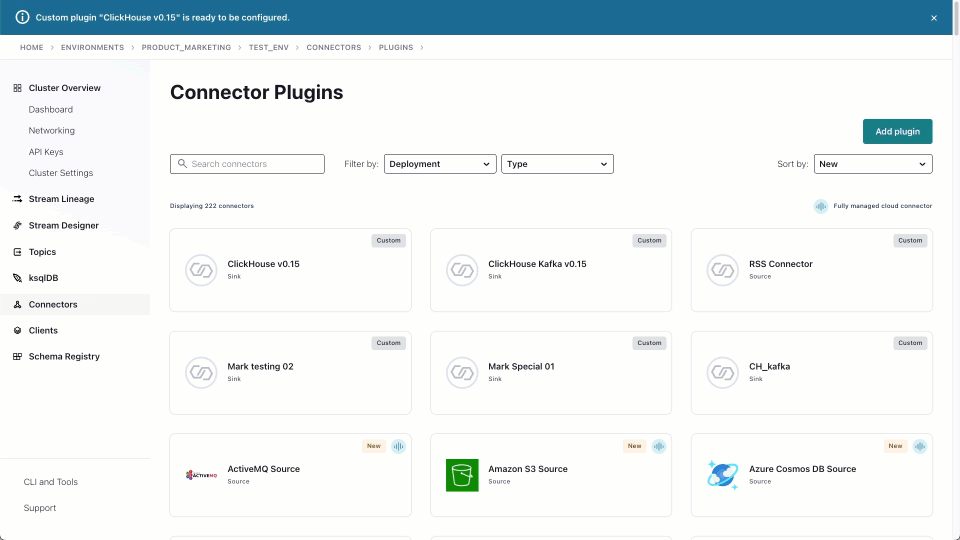
Connector Class-com.clickhouse.kafka.connect.ClickHouseSinkConnectorConnector type- SinkSensitive properties-password. This will ensure entries of the ClickHouse password are masked during configuration and in logs.
Once uploaded, instances of the connector can be created. We demonstrate this below and note the JSON configuration used for this specific task.
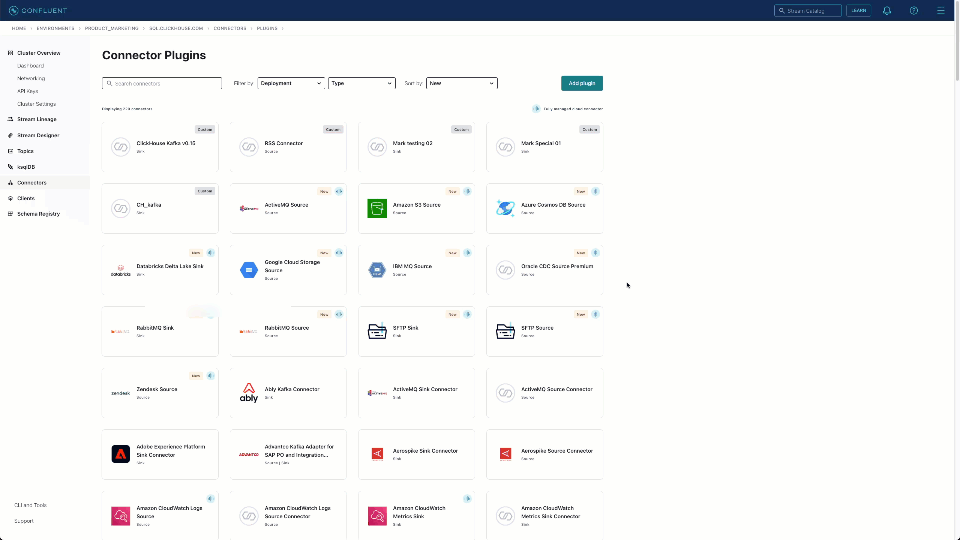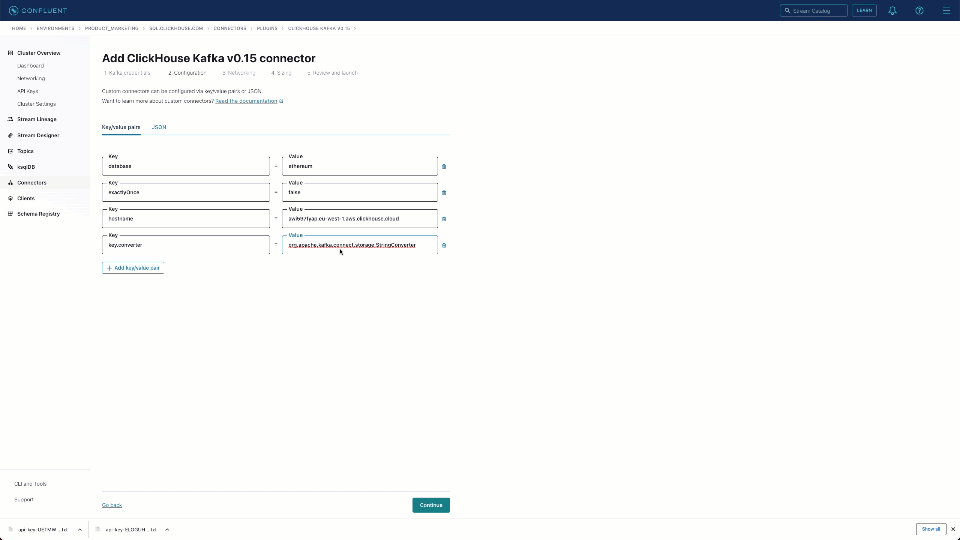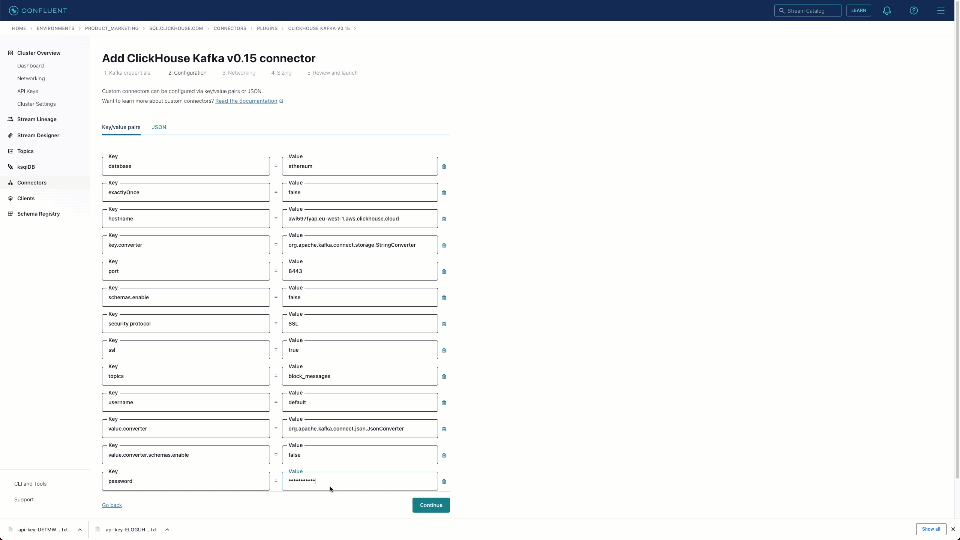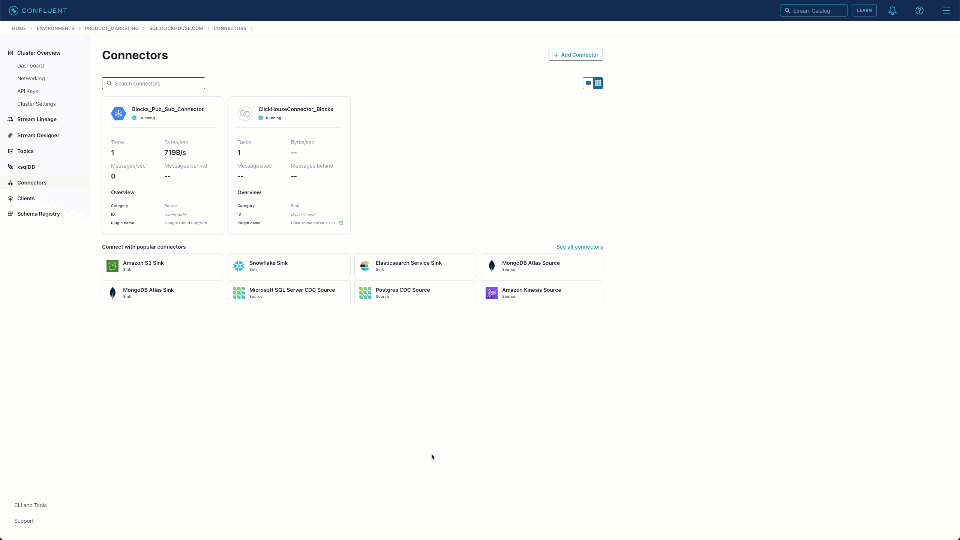
{
"database": "ethereum",
"exactlyOnce": "false",
"hostname": "<hostname>",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"password": "<password>",
"port": "8443",
"schemas.enable": "false",
"security.protocol": "SSL",
"ssl": "true",
"topics": "block_messages",
"username": "default",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false"
}
As of the time of writing, the connector requires the topic and target table to be of the same name. In our earlier example, our receiving table was therefore created as block_messages - adapt this to the data type. In the above example, we specify the ethereum database to be consistent with the previous configuration and disable exactly-once semantics. While supported, this incurs additional overhead and is unnecessary in our case, given the Pub/Sub connector offers, at best, at-least-once delivery. Finally, note the use of the JSON converter for our main payload. A full list of configuration options can be found here.
Testing
New blocks are formed on the Ethereum blockchain at around 4 to 5 per minute, with one row representing each block. After running the above workflow for several minutes, users should be able to confirm data is flowing:
SELECT
count(),
toStartOfMinute(timestamp) AS min
FROM ethereum.blocks_test
GROUP BY min
ORDER BY min DESC
LIMIT 10
┌─count()─┬─────────────────min─┐
│ 2 │ 2023-06-14 16:45:00 │
│ 2 │ 2023-06-14 16:44:00 │
│ 2 │ 2023-06-14 16:40:00 │
│ 4 │ 2023-06-14 16:39:00 │
│ 4 │ 2023-06-14 16:38:00 │
│ 5 │ 2023-06-14 16:37:00 │
│ 5 │ 2023-06-14 16:36:00 │
│ 5 │ 2023-06-14 16:35:00 │
│ 5 │ 2023-06-14 16:34:00 │
│ 3 │ 2023-06-14 16:33:00 │
└─────────┴─────────────────────┘
10 rows in set. Elapsed: 0.029 sec.
While these volumes are small, this same deployment architecture maintains the trace, contract, and transaction datasets in our public sql.clickhouse.com environment. For example, we recommend our earlier blog post and documented examples for queries and inspiration.
Hints and tricks
-
The connector exploits Kafka Connect’s task-based model for scaling throughput. Each task is single-threaded and consumes messages from one or more partitions. No two tasks can consume from the same partition. For optimal throughput, users should configure as many tasks as partitions. Exceeding the number of partitions will bring no further benefit and will just result in idle tasks. Further throughput scaling in this scenario requires the number of partitions to be increased in the source topic. Our largest topic for traces, requires 3 partitions.
-
If deploying the connector in Confluent Cloud using the custom connector offering, settings that control the batch size delivered to each task cannot, as of the time of writing, be modified by the user. These settings are specific to the Kafka Connect framework and not the connector itself. By default, each connector task receives batches of up to 500 rows from the framework. No batching occurs in the connector prior to insertion to ClickHouse. This can mean that insert batches to ClickHouse are potentially small compared to the recommended size. More importantly, this default can result in an insert rate greater than 1 per second. When scaling the number of tasks for throughput, the above can result in issues such as “too many parts”.
To address this, the user should enable Asynchronous Inserts in ClickHouse. This will cause ClickHouse to batch inserts using a disk-based buffer prior to insertion into the underlying table. This ensures large blocks of data are inserted, preventing issues such as “too many parts”. However, this approach is not currently compatible with the exactly-once semantics of the connector, which relies on the deduplication properties of normal inserts (i.e., inserts of identical data are deduplicated within a window period). While recent releases of ClickHouse support deduplication for asynchronous inserts, this feature is experimental and has not been tested with the exactly-once mode of the connector.
We are working with Confluent to expose relevant Kafka Connect settings to deliver larger batches.
- As of the time of writing, the Confluent custom connector interface provides only summary logs. These are often insufficient to diagnose issues. Fortunately, all connectors will create a topic containing logs. The log messages in this topic can be downloaded and examined for debugging purposes. We plan to improve this workload by ensuring relevant debug information is surfaced in the summary logs, minimizing the effort needed to diagnose issues.
Conclusion
In this blog post, we have explored how Confluent Cloud’s new Custom Connector offering can be used to build a zero-code Kafka pipeline for moving data from Google Pub/Sub to ClickHouse Cloud. For our example dataset, we used the events made available by Google for the Ethereum blockchain and the pipeline to maintain the public dataset in sql.clickhouse.com in near real-time.
The clickHouse-kafka-connect sink is in active development at the moment, thanks to the great feedback users are reporting in the repository or via our community Slack. Our plan is to continue improving the production readiness of this connector over the next few months, targeting a GA version of the connector in Q3 this year. If you want to join this effort, don’t hesitate to reach out to us! As always with ClickHouse, any contribution is welcome!
Get started with ClickHouse Cloud today and receive $300 in credits. At the end of your 30-day trial, continue with a pay-as-you-go plan, or contact us to learn more about our volume-based discounts. Visit our pricing page for details.
Share this post
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!
Loading form...



Follow us
Comparisons
Stay informed on feature releases, product roadmap, support, and cloud offerings!
Loading form...
© 2024 ClickHouse, Inc. HQ in the Bay Area, CA and Amsterdam, NL.