The release train keeps on rolling.
We are super excited to share a bevy of amazing features in 23.8
And, we already have a date for the 23.9 release, please register now to join the community call on September 28th at 9:00 AM (PDT) / 6:00 PM (CEST).
Release Summary
29 new features. 19 performance optimisations. 63 bug fixes.
A small subset of highlighted features are below…But the release covers arithmetic on vectors, concatenation of tuples, default arguments for cluster/clusterAllReplicas, counting from metadata (5x faster for Parquet), data skipping in files (huge impact on Parquet, again), streaming consumption from s3, and so…much…more.
New Contributors
A special welcome to all the new contributors to 23.6! ClickHouse's popularity is, in large part, due to the efforts of the community that contributes. Seeing that community grow is always humbling.
If you see your name here, please reach out to us...but we will be finding you on twitter, etc as well.
Al Korgun, Zamazan4ik (Alexander Zaitsev), Andy Fiddaman, Artur Malchanau, Ash Vardanian, Austin Kothig, Bhavna Jindal, Bin Xie, Dani Pozo, Daniel Pozo Escalona, Daniël van Eeden, Davit Vardanyan, Filipp Ozinov, Hendrik M, Jai Jhala, Jianfei Hu, Jiang Yuqing, Jiyoung Yoo, Joe Lynch, Kenji Noguchi, Krisztián Szűcs, Lucas Fernando Cardoso Nunes, Maximilian Roos, Nikita Keba, Pengyuan Bian, Ruslan Mardugalliamov, Selfuppen, Serge Klochkov, Sergey Katkovskiy, Tanay Tummalapalli, VanDarkholme7, Yury Bogomolov, cfanbo, copperybean, daviddhc20120601, ekrasikov, gyfis, hendrik-m, irenjj, jiyoungyoooo, jsc0218, justindeguzman, kothiga, nikitakeba, selfuppen, xbthink, xiebin, Илья Коргун, 王智博
Files, files, and more files
Reading files faster (Michael Kolupaev/Pavel Kruglov)
We’ve highlighted our efforts to improve Parquet performance in several recent releases [1][2]. While improving performance is a never-ending journey, changes in 23.8 are significant in that they bring us to a point where we are more satisfied with the current read performance for Parquet files. Even better, some of these improvements also apply to other file types, such as JSON and CSV.
In summary, ClickHouse now:
- Skips reading row groups by utilizing metadata in Parquet files, which captures the numeric range for a column. This long-awaited feature provides dramatic speedup, as we’ll show.
- Exploits metadata to provide fast counts on most file formats, including Parquet, by avoiding unnecessary reads.
- Allows the use of filename metadata in filter clauses to avoid reading files. When applied to large file lists on object stores such as S3, this can avoid significant I/O and reduce queries from seconds to ms. This improvement applies to all file types.
To illustrate the benefits these additions can bring, we’ll utilize a dataset for PyPI: The Python Package Index. Each row in this dataset represents the download of a Python package using a tool such as pip. We have provided Parquet files containing the downloads for all packages for one day. This consists of around 125.69GiB of Paquet over 1657 files with a total of 900 million rows.
All of the following tests were performed on a GCE e2-highmem-8 instance with 64GiB of RAM and 16 cores local to the GCS bucket in us-central-1.
Before 23.8, a count on these files could be expensive. An arbitrary column from each file would be downloaded in full, read, and the total computed. Running this on a local Macbook:
--23.7
SELECT count()
FROM s3('https://storage.googleapis.com/clickhouse_public_datasets/pypi/file_downloads/2023-07-31/*.parquet')
┌───count()─┐
│ 900786589 │
└───────────┘
1 row in set. Elapsed: 26.488 sec. Processed 900.79 million rows, 134.94 GB (34.01 million rows/s., 5.09 GB/s.)
--23.8
SELECT count()
FROM s3('https://storage.googleapis.com/clickhouse_public_datasets/pypi/file_downloads/2023-07-31/*.parquet')
1 row in set. Elapsed: 11.431 sec. Processed 900.79 million rows, 56.22 KB (78.80 million rows/s., 4.92 KB/s.)
Peak memory usage: 44.43 MiB.
Nice, more than a doubling of performance! This optimization will also work for other file types, so the benefits should go beyond your Parquet files.
These same files have a timestamp column denoting the time at which a download occurred. Using the ParquetMetadata format, we can see this column has metadata describing the minimum and maximum values.
SELECT tupleElement(row_groups[1], 'columns')[1] AS timestamp
FROM s3('https://storage.googleapis.com/clickhouse_public_datasets/pypi/file_downloads/2023-07-31/000000000000.parquet', ParquetMetadata)
FORMAT PrettyJSONEachRow
{
"timestamp": {
"name": "timestamp",
"path": "timestamp",
"total_compressed_size": "681",
"total_uncompressed_size": "681",
"have_statistics": 1,
"statistics": {
"num_values": "406198",
"null_count": "0",
"distinct_count": null,
"min": "1690761600000000",
"max": "1690761650000000"
}
}
}
From 23.8, we can exploit this metadata at query time to speed up queries. Suppose we wish to identify the number of downloads between the 30 minutes on our selected day.
--23.7
SELECT
project,
count() AS c
FROM s3('https://storage.googleapis.com/clickhouse_public_datasets/pypi/file_downloads/2023-07-31/*.parquet')
WHERE (timestamp >= '2023-07-31 15:30:00') AND (timestamp <= '2023-08-31 16:00:00')
GROUP BY project
ORDER BY c DESC
LIMIT 5
┌─project────────────┬───────c─┐
│ boto3 │ 9378319 │
│ urllib3 │ 5343716 │
│ requests │ 4749436 │
│ botocore │ 4618614 │
│ setuptools │ 4128870 │
└────────────────────┴─────────┘
5 rows in set. Elapsed: 83.644 sec. Processed 900.79 million rows, 134.94 GB (10.77 million rows/s., 1.61 GB/s.)
--23.8
SELECT
project,
count() AS c
FROM s3('https://storage.googleapis.com/clickhouse_public_datasets/pypi/file_downloads/2023-07-31/*.parquet')
WHERE (timestamp >= '2023-07-31 15:30:00') AND (timestamp <= '2023-08-31 16:00:00')
GROUP BY project
ORDER BY c DESC
LIMIT 5
5 rows in set. Elapsed: 34.993 sec. Processed 338.86 million rows, 51.17 GB (9.68 million rows/s., 1.46 GB/s.)
Peak memory usage: 95.61 MiB.
Another doubling of performance!
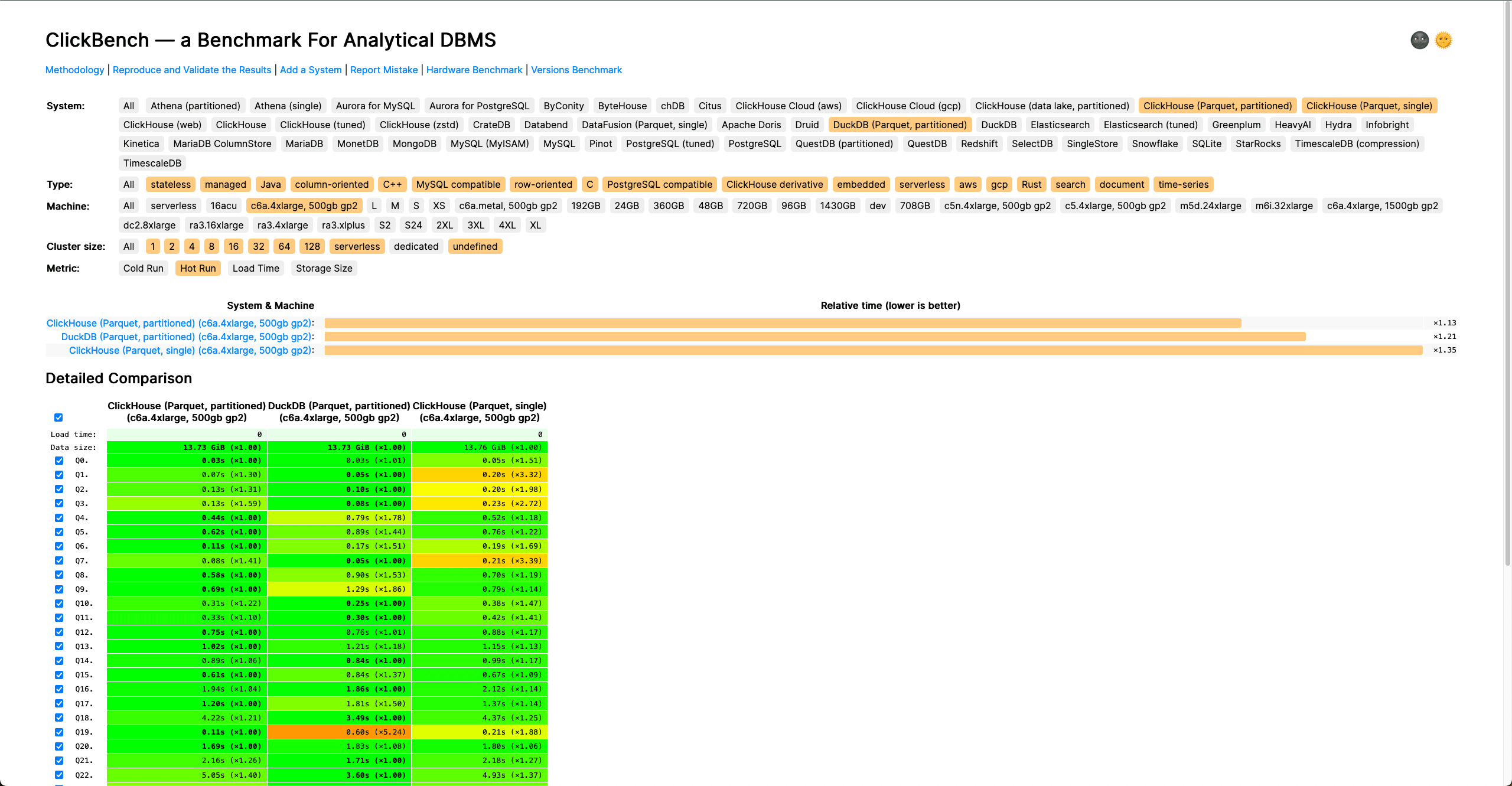
This specific improvement also immediately impacted our ClickBench results as shown below:
Finally, Clickhouse has long supported glob patterns in file paths. While this is perfect for targeting subsets of files, it limits users to the expressiveness of a glob. ClickHouse thus exposes a _file virtual column. This hidden metadata column contains the filename from which a row originates and is exposed to the user. This can be utilized anywhere in a SQL query, e.g. to count the number of uniq filenames or limit the files read to a subset. However, in 23.7 and earlier, this column required the entire file to be read if used in the SELECT part of a query. If users were simply trying to identify a subset, this could mean reading all files.
The potential for performance improvement here is potentially huge and will depend on the size of the subset relative to the total number of files. Consider the following example, where we compute the number of unique files for a 10% sample.
--23.7
SELECT uniq(_file)
FROM s3('https://storage.googleapis.com/clickhouse_public_datasets/pypi/file_downloads/2023-07-31/*.parquet')
WHERE (toUInt32(splitByChar('.', _file)[1]) % 10) = 0
┌─uniq(_file)─┐
│ 166 │
└─────────────┘
1 row in set. Elapsed: 4.572 sec. Processed 89.46 million rows, 13.41 GB (19.57 million rows/s., 2.93 GB/s.)
--23.8
SELECT uniq(_file)
FROM s3('https://storage.googleapis.com/clickhouse_public_datasets/pypi/file_downloads/2023-07-31/*.parquet')
WHERE (toUInt32(splitByChar('.', _file)[1]) % 10) = 0
┌─uniq(_file)─┐
│ 166 │
└─────────────┘
1 row in set. Elapsed: 0.632 sec. Processed 89.46 million rows, 0.00 B (141.65 million rows/s., 0.00 B/s.)
Peak memory usage: 1.71 MiB.
A 7x improvement in speed! Remember this specific optimization works for all file types and not just Parquet.
ClickHouse also exposes a _path virtual column if the full location is required.
Streaming Consumption From S3 (Sergei Katkovskiy, Kseniia Sumarokova)
The ability to read data from S3 is an essential ClickHouse feature used for performing both ad hoc data analysis and possibly the most popular means of migrating data into a MergeTree table. Historically, the orchestration of the latter relied on the user. While an initial data load could be performed using an INSERT INTO SELECT with the s3 function, subsequent incremental loads typically relied on the user building additional processes. These could be either a data pipeline, using a technology such as Kafka, or more simply, the scheduling of an INSERT SELECT e.g. using a cron job. The latter is surprisingly common and can be subtly difficult to ensure it is robust.
In 23.8, we begin to drastically simplify incremental loads from S3 with the S3Queue table engine. This new table engine allows the streaming consumption of data from S3. As files are added to a bucket, ClickHouse will automatically process these files and insert them into a designated table. With this capability, users can set up simple incremental pipelines with no additional code.
Consider the following simple example. Below, we have a GCS bucket that contains Parquet files for the PyPI dataset, where each hour is represented by one file.
CREATE TABLE pypi_queue
ENGINE = S3Queue('https://storage.googleapis.com/clickhouse_public_datasets/pypi/file_downloads/2023/*.parquet')
SETTINGS mode = 'unordered'
CREATE TABLE pypi
ENGINE = MergeTree
ORDER BY (project, timestamp)
SETTINGS allow_nullable_key = 1 EMPTY AS
SELECT *
FROM pypi_queue
CREATE MATERIALIZED VIEW pypi_mv TO pypi AS
SELECT *
FROM pypi_queue
SELECT count()
FROM pypi
┌──count()─┐
│ 39082124 │
└──────────┘
1 row in set. Elapsed: 0.003 sec.
Users familiar with the Kafka table engine will recognize the below-mentioned constructs. We use a materialized view here to subscribe to the S3Queue and insert the transformed results into the target pypi table.
If we add a new file to the bucket, the table is updated:
We’ve used a GCS bucket below, which is an S3-compatible service. This feature will work on all S3-compatible services.
The above S3Queue engine works by periodically polling the bucket and tracking the files present, storing the state in a ClickHouse Keeper node. By default, the list of files retrieved on each poll is compared against the stored list to identify new files. The diagram below shows how a new file is processed (and added to Keeper) and inserted into the queue table. While this doesn’t store the data itself, materialized views can subscribe and transform rows before inserting them into a table for querying.
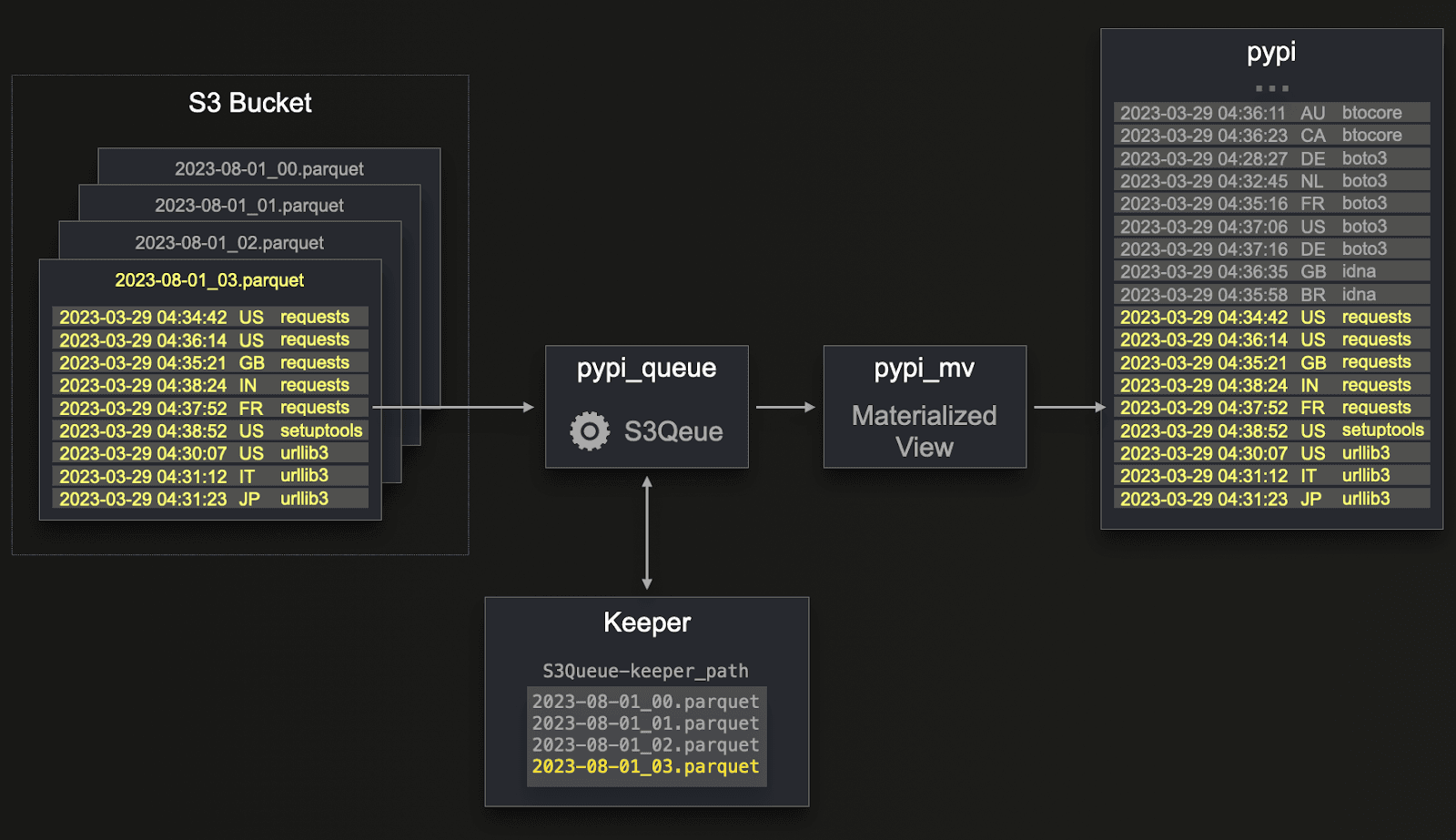
This represents a simplification of the default unordered behavior, which can be tuned. For example, users can configure the engine to delete files once they are imported. This has the advantage of removing the state from ClickHouse Keeper, which can help ensure the tracked state does not grow unbounded. To prevent an unbounded storage of state, the engine also (by default) only tracks a limited number of files while also imposing a TTL. After either a file TTL expires or the number of files exceeds the current limit, files will be re-imported. Users can tune these limits but are encouraged to either utilize the delete feature or manually expire files in the bucket using S3 features.
Alternatively, the engine can be configured to use the naming of files with an ordered mode. In this mode, only the max name of the successfully consumed files is stored in Keeper. On each poll, only files with a higher name are imported. This requires an ordering to be imposed in your filenames but avoids many of the above complexities.
We look forward to improving this feature over the coming months and hope we’ve simplified your architecture just a little.
Direct Import From Archives (Nikita Keba, Antonio Andelic, Pavel Kruglov)
For our final feature highlight and staying on the theme of files, we are pleased to announce the support for archives. ClickHouse already supported compressed files with formats such as zstd, lz4, snappy, gz, xz and bz2. Up to 23.8, these compressed files could only contain a single file. With 23.8, we add support for zip, tar, and 7zip - all of which can contain potentially multiple files.
For example purposes, we have provided a 1.5GB zip archive containing 24 CSV files (45GB uncompressed), representing one day's worth of PyPI data at 900m rows. Each of these files contains sample columns from the PyPI dataset: project, version, and timestamp, and represents one hour of data. The query below counts the number of rows per file in the zip using the virtual column _file. Notice how we query all files in the archive using the :: * syntax.
Currently archives are only supported through the file function. The following is therefore executed with clickhouse-local. For support with functions such as S3, stay tuned!
SELECT count(), _file
FROM file('2023-08-01.zip :: *.csv')
GROUP BY _file
┌──count()─┬─_file────────────────┐
│ 47251829 │ file_download_15.csv │
│ 43946206 │ file_download_17.csv │
│ 39082124 │ file_download_0.csv │
│ 38928391 │ file_download_21.csv │
│ 34467371 │ file_download_1.csv │
│ 44163805 │ file_download_12.csv │
│ 43229010 │ file_download_18.csv │
│ 41974421 │ file_download_10.csv │
│ 33003822 │ file_download_4.csv │
│ 33331289 │ file_download_23.csv │
│ 34430684 │ file_download_5.csv │
│ 40843622 │ file_download_11.csv │
│ 41122874 │ file_download_19.csv │
│ 37279028 │ file_download_6.csv │
│ 36118825 │ file_download_22.csv │
│ 40800076 │ file_download_7.csv │
│ 31962590 │ file_download_2.csv │
│ 42055283 │ file_download_20.csv │
│ 30887864 │ file_download_3.csv │
│ 45910953 │ file_download_13.csv │
│ 43467095 │ file_download_9.csv │
│ 46705311 │ file_download_16.csv │
│ 42704388 │ file_download_8.csv │
│ 48248862 │ file_download_14.csv │
└──────────┴──────────────────────┘
24 rows in set. Elapsed: 97.703 sec. Processed 961.10 million rows, 48.57 GB (9.84 million rows/s., 497.11 MB/s.)
Peak memory usage: 4.04 MiB.
We can use the same :: notation to target a specific file.
SELECT toStartOfMinute(timestamp) AS minute, count() AS c
FROM file('2023-08-01.zip :: file_download_9.csv')
WHERE project = 'requests'
GROUP BY project, minute
ORDER BY minute ASC
┌──────────────minute─┬─────c─┐
│ 2023-08-01 09:00:00 │ 10944 │
│ 2023-08-01 09:01:00 │ 11076 │
│ 2023-08-01 09:02:00 │ 13705 │
│ 2023-08-01 09:03:00 │ 12460 │
│ 2023-08-01 09:04:00 │ 11379 │
│ 2023-08-01 09:05:00 │ 13363 │
│ 2023-08-01 09:06:00 │ 11438 │
…
│ 2023-08-01 09:54:00 │ 7972 │
│ 2023-08-01 09:55:00 │ 8641 │
│ 2023-08-01 09:56:00 │ 9696 │
│ 2023-08-01 09:57:00 │ 8710 │
│ 2023-08-01 09:58:00 │ 7495 │
│ 2023-08-01 09:59:00 │ 7692 │
└─────────────────────┴───────┘
60 rows in set. Elapsed: 7.374 sec. Processed 42.97 million rows, 2.20 GB (5.83 million rows/s., 298.59 MB/s.)
Peak memory usage: 66.99 MiB.


