The release train keeps on rolling.
We are super excited to share a bevy of amazing features in 23.7
And, we already have a date for the 23.8 release, please register now to join the community call on August 31st at 9:00 AM (PDT) / 6:00 PM (CEST).
Release Summary
31 new features.
16 performance optimisations.
47 bug fixes.
A small subset of highlighted features are below. But it is worth noting that several features are now production ready or have been enabled by default. You can find those at the end of this post.
New Contributors
A special welcome to all the new contributors to 23.7! ClickHouse's popularity is, in large part, due to the efforts of the community who contributes. Seeing that community grow is always humbling.
If you see your name here, please reach out to us...but we will be finding you on twitter, etc as well.
Alex Cheng, AlexBykovski, Chen768959, John Spurlock, Mikhail Koviazin, Rory Crispin, Samuel Colvin, Sanjam Panda, Song Liyong, StianBerger, Vitaliy Pashkov, Yarik Briukhovetskyi, Zach Naimon, chen768959, dheerajathrey, lcjh, pedro.riera, therealnick233, timfursov, velavokr, xiao, xiaolei565, xuelei, yariks5s
Parquet writing improvements (Michael Kolupaev)
Recent months have seen numerous read improvements for the Parquet file format in ClickHouse. As well as parallelizing reads across row groups and utilizing metadata for filtering, we’ve even taken the time to ensure queries on Hugging Face datasets are optimized. We understand that this file format is ubiquitous and often fundamental for tasks such as local analysis using clickhouse-local and data migrations. Our continued commitment to improving our Parquet support and obsession with speed, has paid dividends and been reflected in the recent improvements in our public benchmarks.
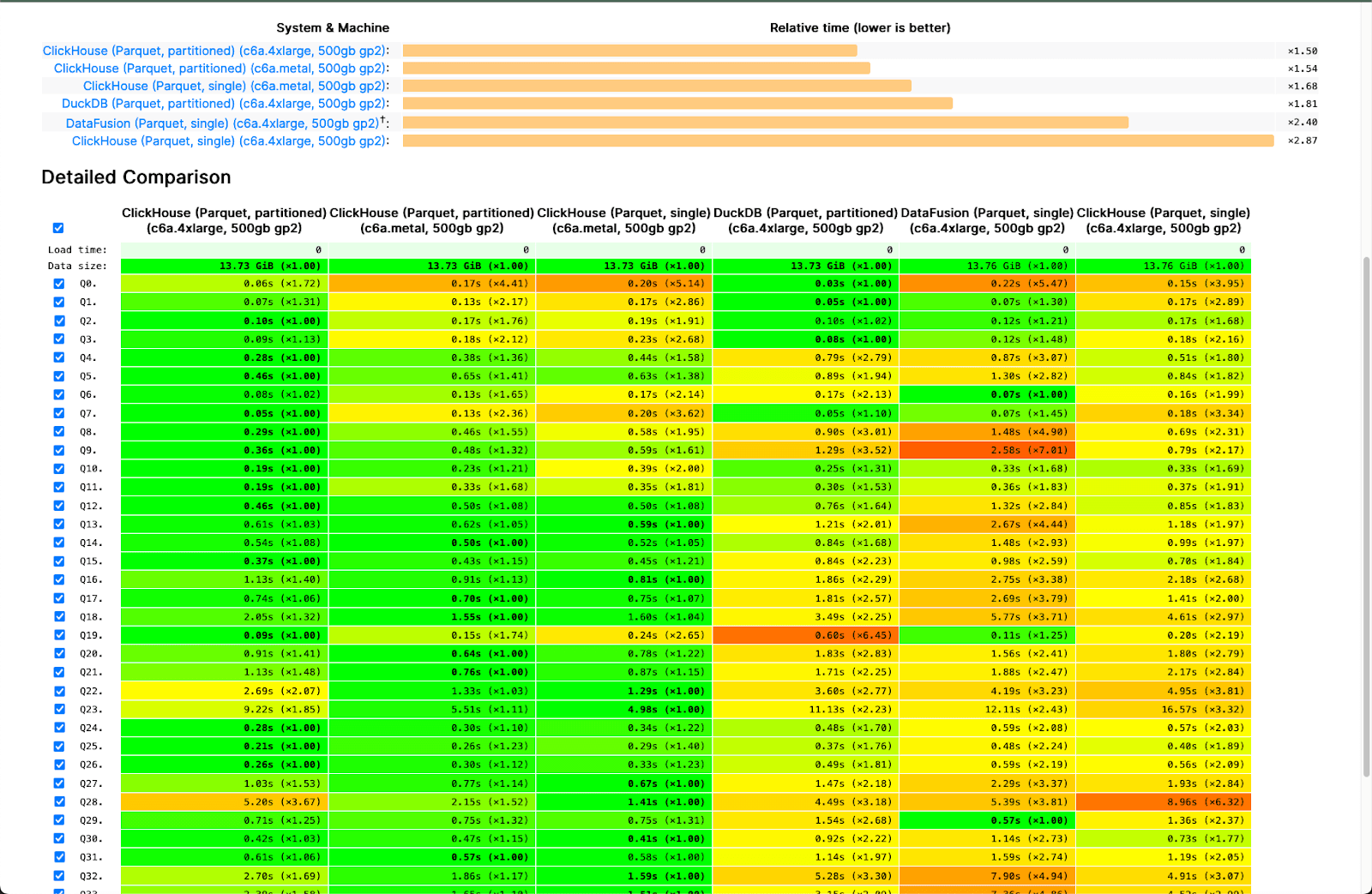
Of course reading Parquet is only half the story. Users invariably need to write ClickHouse data to Parquet, often as part of a reverse ETL workflow or need to share the results of a data analysis. We’re therefore delighted to announce Parquet writing is now up to 6x faster as of 23.7.
Let's consider an example using the UK house price data to illustrate. Below we use clickhouse-local and import the data from an existing publically S3 hosted Parquet file.
CREATE TABLE uk_house_price
ENGINE = MergeTree
ORDER BY (postcode1, postcode2, addr1, addr2)
SETTINGS allow_nullable_key = 1 AS
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices.parquet')
0 rows in set. Elapsed: 40.550 sec. Processed 28.28 million rows, 4.67 GB (697.33 thousand rows/s., 115.15 MB/s.)
Exporting this dataset with 23.6 is still impressively fast at almost 1.5million row/sec.
SELECT *
FROM uk_house_price
INTO OUTFILE 'london-prices.parquet'
28276228 rows in set. Elapsed: 19.901 sec. Processed 28.20 million rows, 4.66 GB (1.42 million rows/s., 233.98 MB/s.)
Exporting the same dataset using 23.7 shows a dramatic improvement, almost halving the total time! Your mileage will vary here, with improvements seen up to 6x.
SELECT *
FROM uk_house_price
INTO OUTFILE 'london-prices.parquet'
28276228 rows in set. Elapsed: 11.649 sec. Processed 28.24 million rows, 4.66 GB (2.42 million rows/s., 400.39 MB/s.)
Sparse columns enabled by default (Anton Popov)
Sparse columns have been a feature of ClickHouse for some time, but prior to 23.7 needed to be explicitly enabled. This optimization aims to reduce the total data written for a column, by dynamically changing the encoded format when a high number of default values are detected. As well as improving compression, this has the advantage of improving query performance and memory efficiency.
With 23.7 this feature is enabled by default. Users should see immediate improvements in compression and performance where this encoding can be applied.
When writing a data part (at either insert or merge time), ClickHouse computes the ratio of default values for each column. If this exceeds the configured threshold, only the non-default values for the column are written. To preserve which rows have a default value, a separate stream is written containing an encoding of the offsets. This information is combined at query time, ensuring the optimization is completely transparent to the user. The following diagram shows an example of this:
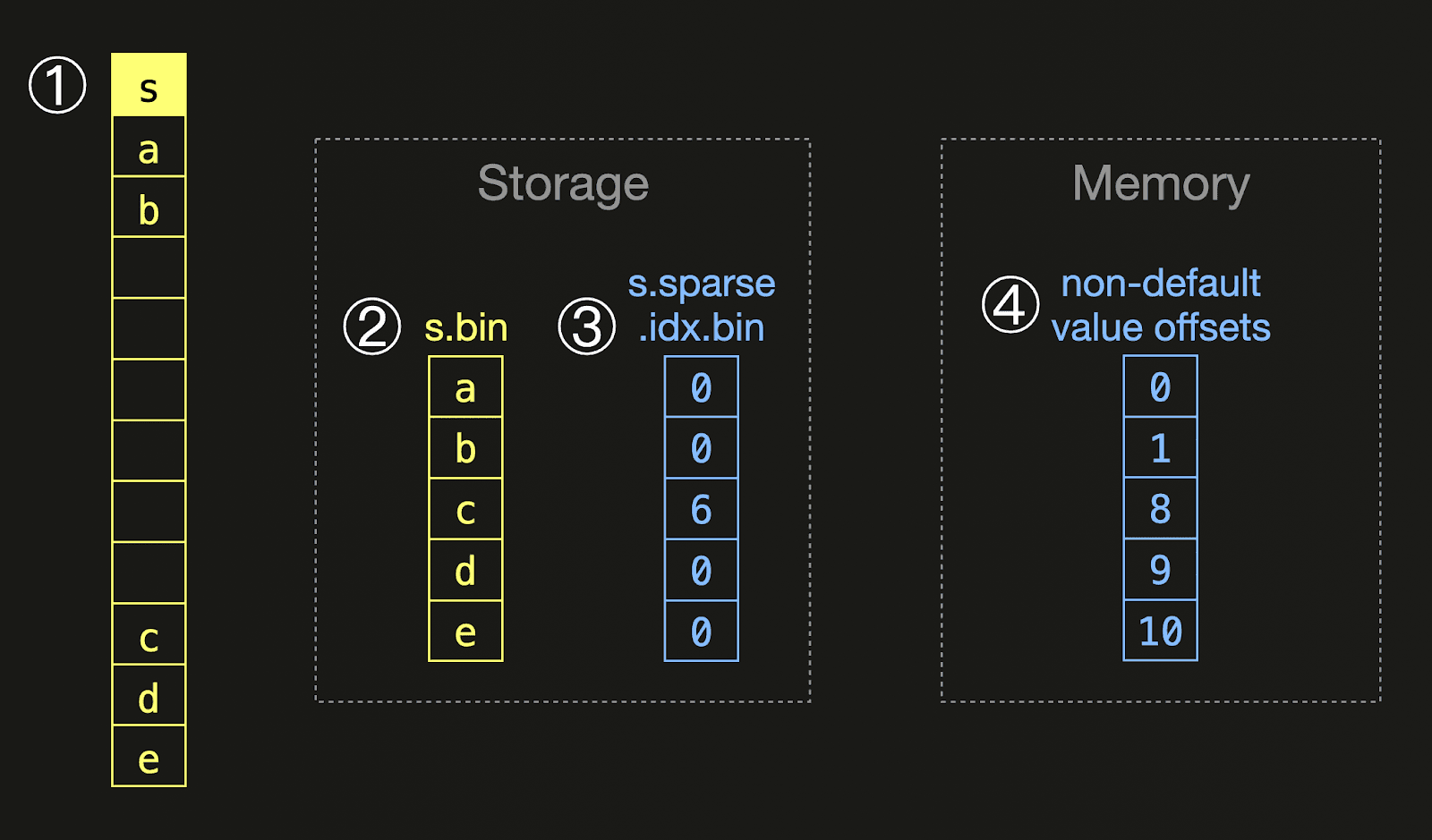 For a ① column
For a ① column s containing sparse values, ClickHouse only writes the non-default values into ② a column file on disk, together with ③ an additional file containing a sparse encoding of the non-default value offsets: For each non-default value, we store how many default values are present directly before the non-default value. At query time, we create an ④ in-memory representation with direct offsets from this encoding. The sparse encoded on-storage variant contains data with repeated values.
Prior to 23.7, users were required to explicitly enable Sparse columns by modifying the setting that controls the required threshold for the Sparse column encoding to be used - ratio_of_defaults_for_sparse_serialization. This defaulted to a value of 1.0, which effectively disabled the feature. In 23.7, this value defaults to 0.9375.
While we expect sparse columns to benefit even highly structured data, we expect larger improvements for use cases where users insert data with less strict schemas e.g. JSON with highly variable keys. In these cases, users will pay almost no overhead for having a column which only has values for a few rows - potentially allowing significant space savings.
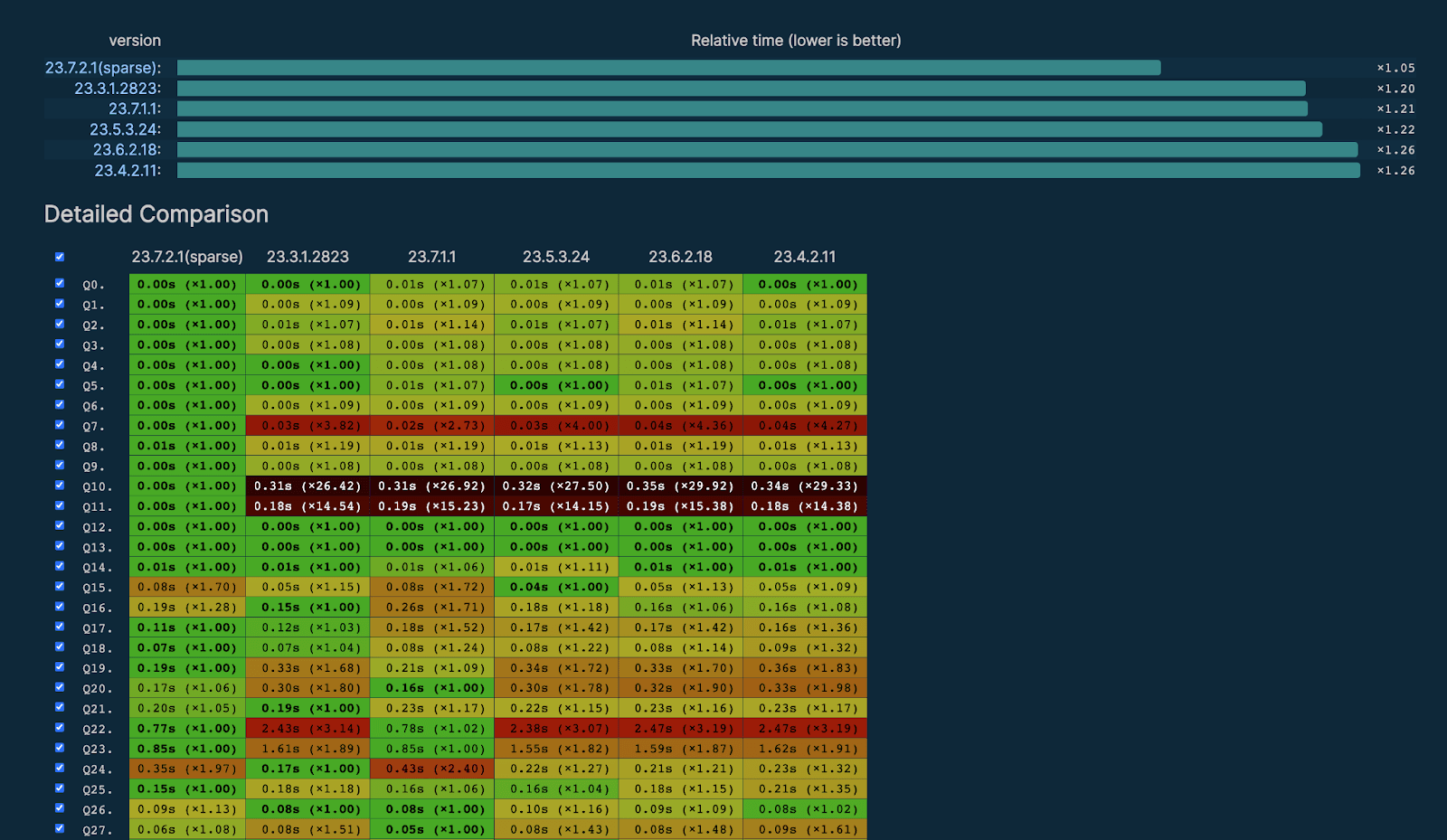
While we expected improvements in our public ClickBench benchmarks, the scale of the benefits from enabling this optimization by default was a pleasant surprise.
Experimental support for PRQL (János Benjamin Antal)
At ClickHouse, we hold the conviction that SQL stands as the godfather among all query languages, with the power to tackle virtually any data problem. Throughout time, numerous languages have vied to rival or supplant SQL, yielding varied degrees of success. Fresh query languages emerge rapidly, but often fade away just as quickly. The endurance of SQL and its incorporation into many data storage systems across successive versions stands as a testament to its lasting significance. Nevertheless, we also acknowledge the importance of engaging users on familiar ground and recognize that some languages are better suited to use cases than others. If we see sufficient adoption and demand for a query language we can consider adding support and always welcome community PRs! Thanks to such a community contribution, PRQL is now supported in ClickHouse as an experimental feature.
PRQL (Pipelined Relational Query Language) pronounced “Prequel”, positions itself as “a simple, powerful, pipelined SQL replacement”. The pipeline nature of the syntax has proved popular, with a growing community of contributors. By chaining transformations to form pipelines, otherwise complex SQL queries can be elegantly composed. At ClickHouse we can see how this style of query construction has some potentially interesting applications, especially in use cases where users conduct search and discovery exercises - Observability maybe?
As well as being well documented, users can experiment with a public playground. Let's consider a few simple examples using the UK house price dataset. Suppose wish to highest districts in in London
from uk_house_price
filter town == 'LONDON'
group district (
aggregate {
avg_price = average price
}
)
sort {-avg_price}
take 1..10
SELECT
district,
AVG(price) AS avg_price
FROM uk_house_price
WHERE town = 'LONDON'
GROUP BY district
ORDER BY avg_price DESC
LIMIT 10
┌─district───────────────┬──────────avg_price─┐
│ CITY OF LONDON │ 2016389.321229964 │
│ CITY OF WESTMINSTER │ 1107261.809839673 │
│ KENSINGTON AND CHELSEA │ 1105730.3371717487 │
│ CAMDEN │ 752077.7613715645 │
│ RICHMOND UPON THAMES │ 644835.3877018511 │
│ HAMMERSMITH AND FULHAM │ 590308.6679440506 │
│ HOUNSLOW │ 574833.3599378078 │
│ ISLINGTON │ 531522.146523729 │
│ HARLOW │ 500000 │
│ WANDSWORTH │ 464798.7692006684 │
└────────────────────────┴────────────────────┘
10 rows in set. Elapsed: 0.079 sec.
As shown, ClickHouse provides us with the equivalent SQL statement that the PRQL query has been compiled to.
A query which might be more challenging for less experienced SQL users is to find the highest row, for a specific column, per group. For example, below we find the most expensive house per postcode in the UK sorted by price.
from uk_house_price
filter town == 'LONDON'
filter postcode1 != ''
select {
postcode1, street, price
}
group postcode1 (
sort {-price}
take 1
)
sort {-price}
take 1..10
WITH table_0 AS
(
SELECT
postcode1,
street,
price
FROM uk_house_price
WHERE (town = 'LONDON') AND (postcode1 != '')
ORDER BY
postcode1 ASC,
price DESC
LIMIT 1 BY postcode1
)
SELECT
postcode1,
street,
price
FROM table_0
ORDER BY price DESC
LIMIT 10
┌─postcode1─┬─street──────────┬─────price─┐
│ W1U │ BAKER STREET │ 594300000 │
│ W1J │ STANHOPE ROW │ 569200000 │
│ SE1 │ SUMNER STREET │ 448500000 │
│ E1 │ BRAHAM STREET │ 421364142 │
│ EC2V │ GRESHAM STREET │ 411500000 │
│ SE10 │ WATERVIEW DRIVE │ 400000000 │
│ EC1Y │ MALLOW STREET │ 372600000 │
│ SW1H │ BROADWAY │ 370000000 │
│ W1S │ NEW BOND STREET │ 366180000 │
│ EC4V │ CARTER LANE │ 337000000 │
└───────────┴─────────────────┴───────────┘
10 rows in set. Elapsed: 0.498 sec. Processed 25.32 million rows, 574.02 MB (50.83 million rows/s., 1.15 GB/s.)
Peak memory usage: 60.70 MiB.
The brevity of the above query vs the equivalent SQL is quite compelling.
As a language which compiles to SQL, we’re excited to see how PRQL develops and the use cases it's applied to with ClickHouse. Let us know if you’ve found the PRQL useful and the problems it has allowed you to solve!


