Introduction
ClickHouse is the fastest and most resource-efficient open-source database for real-time applications and analytics. As one of its components, ClickHouse Keeper is a fast, more resource-efficient, and feature-rich alternative to ZooKeeper. This open-source component provides a highly reliable metadata store, as well as coordination and synchronization mechanisms. It was originally developed for use with ClickHouse when it is deployed as a distributed system in a self-managed setup or a hosted offering like CloudHouse Cloud. However, we believe that the broader community can benefit from this project in additional use cases.
In this post, we describe the motivation, advantages, and development of ClickHouse Keeper and preview our next planned improvements. Moreover, we introduce a reusable benchmark suite, which allows us to simulate and benchmark typical ClickHouse Keeper usage patterns easily. Based on this, we present benchmark results highlighting that ClickHouse Keeper uses up to 46 times less memory than ZooKeeper for the same volume of data while maintaining performance close to ZooKeeper.
Motivation
Modern distributed systems require a shared and reliable information repository and consensus system for coordinating and synchronizing distributed operations. For ClickHouse, ZooKeeper was initially chosen for this. It was reliable through its wide usage, provided a simple and powerful API, and offered reasonable performance.
However, not only performance but also resource efficiency and scalability have always been a top priority for ClickHouse. ZooKeeper, being a Java ecosystem project, did not fit into our primarily C++ codebase very elegantly, and as we used it at a higher and higher scale, we started running into resource usage and operational challenges. In order to overcome these shortcomings of ZooKeeper, we built ClickHouse Keeper from scratch, taking into account additional requirements and goals our project needed to address.
ClickHouse Keeper is a drop-in replacement for ZooKeeper, with a fully compatible client protocol and the same data model. Beyond that, it offers the following benefits:
- Easier setup and operation: ClickHouse Keeper is implemented in C++ instead of Java and, therefore, can run embedded in ClickHouse or standalone
- Snapshots and logs consume much less disk space due to better compression
- No limit on the default packet and node data size (it is 1 MB in ZooKeeper)
- No ZXID overflow issue (it forces a restart for every 2B transactions in ZooKeeper)
- Faster recovery after network partitions due to the use of a better-distributed consensus protocol
- Additional consistency guarantees: ClickHouse Keeper provides the same consistency guarantees as ZooKeeper - linearizable writes plus strict ordering of operations inside the same session. Additionally, and optionally (via a quorum_reads setting), ClickHouse Keeper provides linearizable reads.
- ClickHouse Keeper is more resource efficient and uses less memory for the same volume of data (we will demonstrate this later in this blog)
The development of ClickHouse Keeper started as an embedded service in the ClickHouse server in February 2021. In the same year, a standalone mode was introduced, and Jepsen tests were added - every 6 hours, we run automated tests with several different workflows and failure scenarios to validate the correctness of the consensus mechanism.
At the time of writing this blog, ClickHouse Keeper has been production-ready for more than one and a half years and has been deployed at scale in our own ClickHouse Cloud since its first private preview launch in May 2022.
In the rest of the blog, we sometimes refer to ClickHouse Keeper as simply “Keeper,” as we often call it internally.
Usage in ClickHouse
Generally, anything requiring consistency between multiple ClickHouse servers relies on Keeper:
- Keeper provides the coordination system for data replication in self-managed shared-nothing ClickHouse clusters
- Automatic insert deduplication for replicated tables of the mergetree engine family is based on block-hash-sums stored in Keeper
- Keeper provides consensus for part names (based on sequential block numbers) and for assigning part merges and mutations to specific cluster nodes
- Keeper is used under the hood of the KeeperMap table engine which allows you to use Keeper as consistent key-value store with linearizable writes and sequentially consistent reads
- read about an application utilizing this for implementing a task scheduling queue on top of ClickHouse
- Kafka Connect Sink uses this table engine as a reliable state store for implementing exactly-once delivery guarantees
- Keeper keeps track of consumed files in the S3Queue table engine
- Replicated Database engine stores all metadata in Keeper
- Keeper is used for coordinating Backups with the ON CLUSTER clause
- User defined functions can be stored in Keeper
- Access control information can be stored in Keeper
- Keeper is used as a shared central store for all metadata in ClickHouse Cloud
Observing Keeper
In the following sections, in order to observe (and later model in a benchmark) some of ClickHouse Cloud’s interaction with Keeper, we load a month of data from the WikiStat data set into a table in a ClickHouse Cloud service with 3 nodes. Each node has 30 CPU cores and 120 GB RAM. Each service uses its own dedicated ClickHouse Keeper service consisting of 3 servers, with 3 CPU cores and 2 GB RAM per Keeper server.
The following diagram illustrates this data-loading scenario:
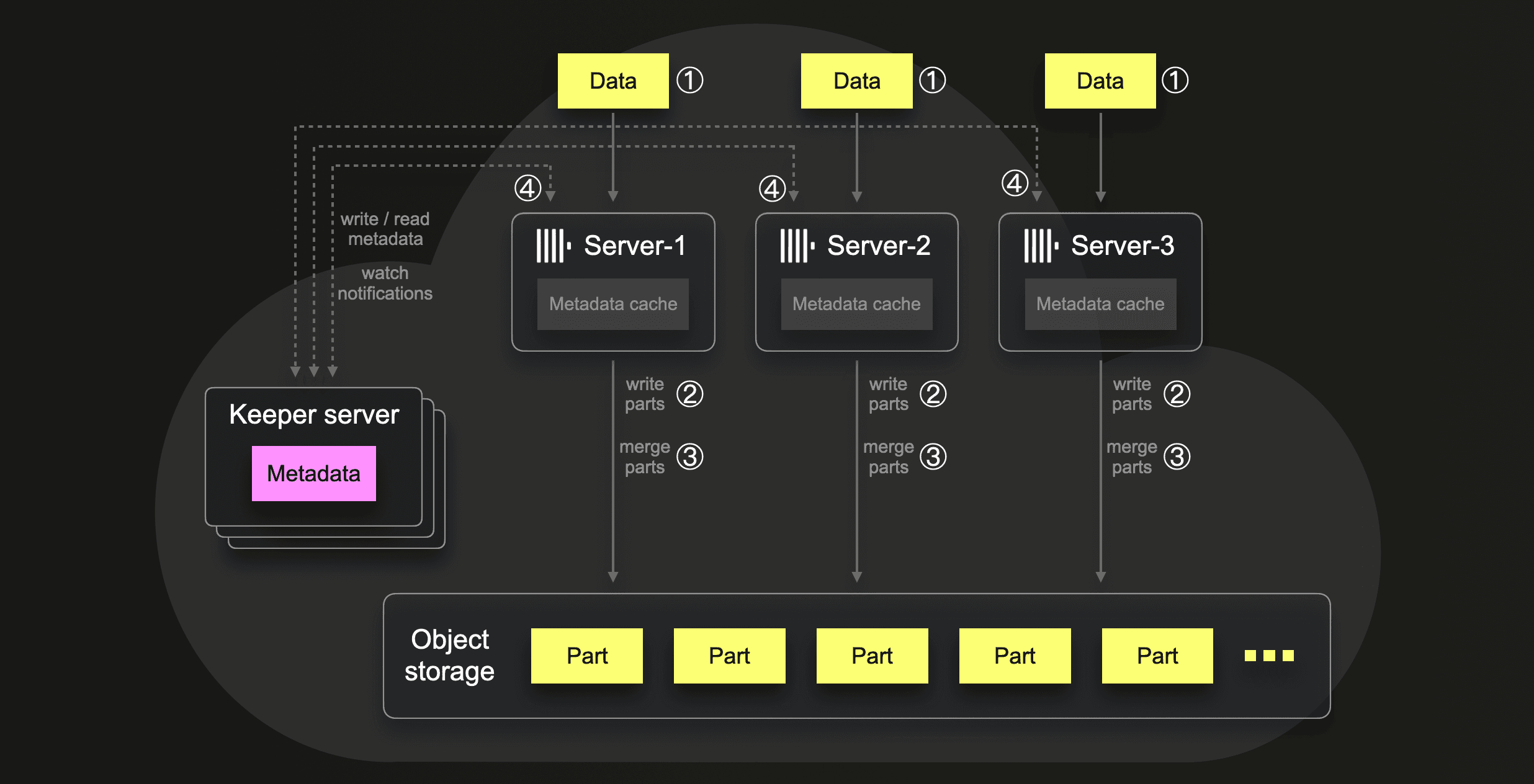
① Data loading
Via a data load query, we load ~4.64 billion rows from ~740 compressed files (one file represents one specific hour of one specific day) in parallel with all three ClickHouse servers in ~ 100 seconds. The peak main memory usage on a single ClickHouse server was ~107 GB:
0 rows in set. Elapsed: 101.208 sec. Processed 4.64 billion rows, 40.58 GB (45.86 million rows/s., 400.93 MB/s.)
Peak memory usage: 107.75 GiB.
② Part creations
For storing the data, the 3 ClickHouse servers together created 240 initial parts in object storage. The average number of rows per initial part was ~19 million rows, respectively. The average size was ~100 MiB, and the total amount of inserted rows is 4.64 billion:
┌─parts──┬─rows_avg──────┬─size_avg───┬─rows_total───┐
│ 240.00 │ 19.34 million │ 108.89 MiB │ 4.64 billion │
└────────┴───────────────┴────────────┴──────────────┘
Because our data load query utilizes the s3Cluster table function, the creation of the initial parts is evenly distributed over the 3 ClickHouse servers of our ClickHouse Cloud services:
┌─n─┬─parts─┬─rows_total───┐
│ 1 │ 86.00 │ 1.61 billion │
│ 2 │ 76.00 │ 1.52 billion │
│ 3 │ 78.00 │ 1.51 billion │
└───┴───────┴──────────────┘
③ Part merges
During the data loading, in the background, ClickHouse executed 1706 part merges, respectively:
┌─merges─┐
│ 1706 │
└────────┘
④ Keeper interactions
ClickHouse Cloud completely separates the storage of data and metadata from the servers. All data parts are stored in shared object storage, and all metadata is stored in Keeper. When a ClickHouse server has written a new part to object storage (see ② above) or merged some parts to a new larger part (see ③ above), then this ClickHouse server is using a multi-write transaction request for updating the metadata about the new part in Keeper. This information includes the name of the part, which files belong to the part, and where the blobs corresponding to files reside in object storage. Each server has a local cache with subsets of the metadata and gets automatically informed about data changes by a Keeper instance through a watch-based subscription mechanism.
For our aforementioned initial part creations and background part merges, a total of ~18k Keeper requests were executed. This includes ~12k multi-write transaction requests (containing only write-subrequests). All other requests are a mix of read and write requests. Additionally, the ClickHouse servers received ~ 800 watch notifications from Keeper:
total_requests: 17705
multi_requests: 11642
watch_notifications: 822
We can see how these requests were sent and how the watch notifications got received quite evenly from all three ClickHouse nodes:
┌─n─┬─total_requests─┬─multi_requests─┬─watch_notifications─┐
│ 1 │ 5741 │ 3671 │ 278 │
│ 2 │ 5593 │ 3685 │ 269 │
│ 3 │ 6371 │ 4286 │ 275 │
└───┴────────────────┴────────────────┴─────────────────────┘
The following two charts visualize these Keeper requests during the data-loading process:
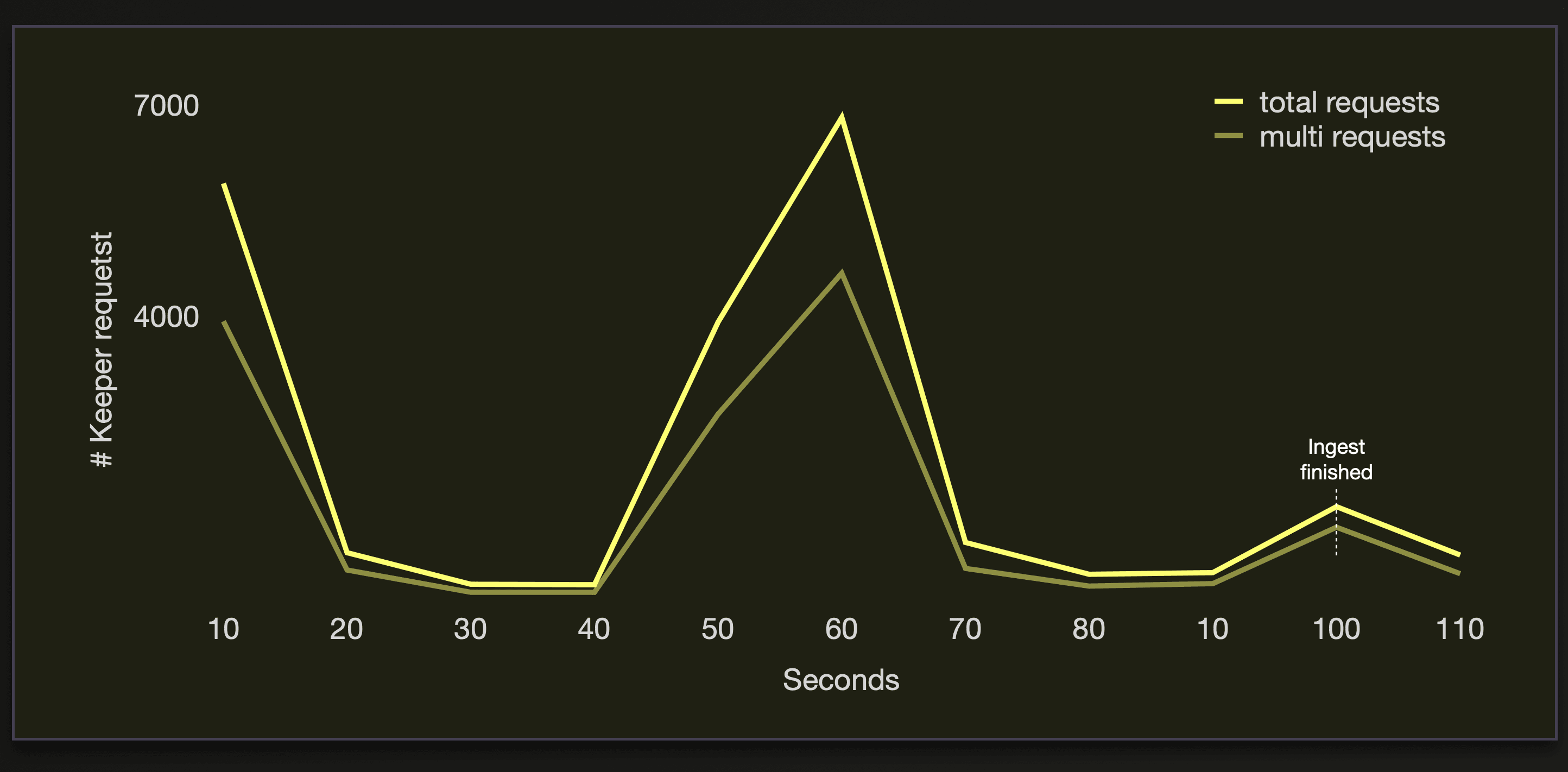 We can see that ~70% of the Keeper requests are multi-write transactions.
We can see that ~70% of the Keeper requests are multi-write transactions.
Note that the amount of Keeper requests can vary based on the ClickHouse cluster size, ingest settings, and data size. We briefly demonstrate how these three factors influence the number of generated Keeper requests.
ClickHouse cluster size
If we load the data with 10 instead of 3 servers in parallel, we ingest the data more than 3 times faster (with the SharedMergeTree):
0 rows in set. Elapsed: 33.634 sec. Processed 4.64 billion rows, 40.58 GB (138.01 million rows/s., 1.21 GB/s.)
Peak memory usage: 57.09 GiB.
The higher number of servers generates more than 3 times the amount of Keeper requests:
total_requests: 60925
multi_requests: 41767
watch_notifications: 3468
Ingest settings
For our original data load, run with 3 ClickHouse servers, we configured a max size of ~25 million rows per initial part to speed up ingest speed at the expense of higher memory usage. If, instead, we run the same data load with the default value of ~1 million rows per initial part, then the data load is slower but uses ~9 times less main memory per ClickHouse server:
0 rows in set. Elapsed: 121.421 sec. Processed 4.64 billion rows, 40.58 GB (38.23 million rows/s., 334.19 MB/s.)
Peak memory usage: 12.02 GiB.
And ~4 thousand instead of 240 initial parts are created:
┌─parts─────────┬─rows_avg─────┬─size_avg─┬─rows_total───┐
│ 4.24 thousand │ 1.09 million │ 9.20 MiB │ 4.64 billion │
└───────────────┴──────────────┴──────────┴──────────────┘
This causes a higher number of part merges:
┌─merges─┐
│ 9094 │
└────────┘
And we get a higher number of Keeper requests (~147k instead of ~17k):
total_requests: 147540
multi_requests: 105951
watch_notifications: 7439
Data size
Similarly, if we load more data (with the default value of ~1 million rows per initial part), e.g. six months from the WikiStat data set, then we get a higher amount of ~24 thousand initial parts for our service:
┌─parts──────────┬─rows_avg─────┬─size_avg─┬─rows_total────┐
│ 23.75 thousand │ 1.10 million │ 9.24 MiB │ 26.23 billion │
└────────────────┴──────────────┴──────────┴───────────────┘
Which causes more merges:
┌─merges─┐
│ 28959 │
└────────┘
Resulting in ~680k Keeper requests:
total_requests: 680996
multi_requests: 474093
watch_notifications: 32779
Benchmarking Keeper
We developed a benchmark suite coined keeper-bench-suite for benchmarking the typical ClickHouse interactions with Keeper explored above. For this, keeper-bench-suite allows simulating the parallel Keeper workload from a ClickHouse cluster consisting of N (e.g. 3) servers:
 We are piggybacking on keeper-bench, a tool for benchmarking Keeper or any ZooKeeper-compatible system. With that building block, we can simulate and benchmark the typical parallel Keeper traffic from
We are piggybacking on keeper-bench, a tool for benchmarking Keeper or any ZooKeeper-compatible system. With that building block, we can simulate and benchmark the typical parallel Keeper traffic from N ClickHouse servers. This diagram shows the complete architecture of the Keeper Bench Suite, which allows us to set up easily and benchmark arbitrary Keeper workload scenarios:
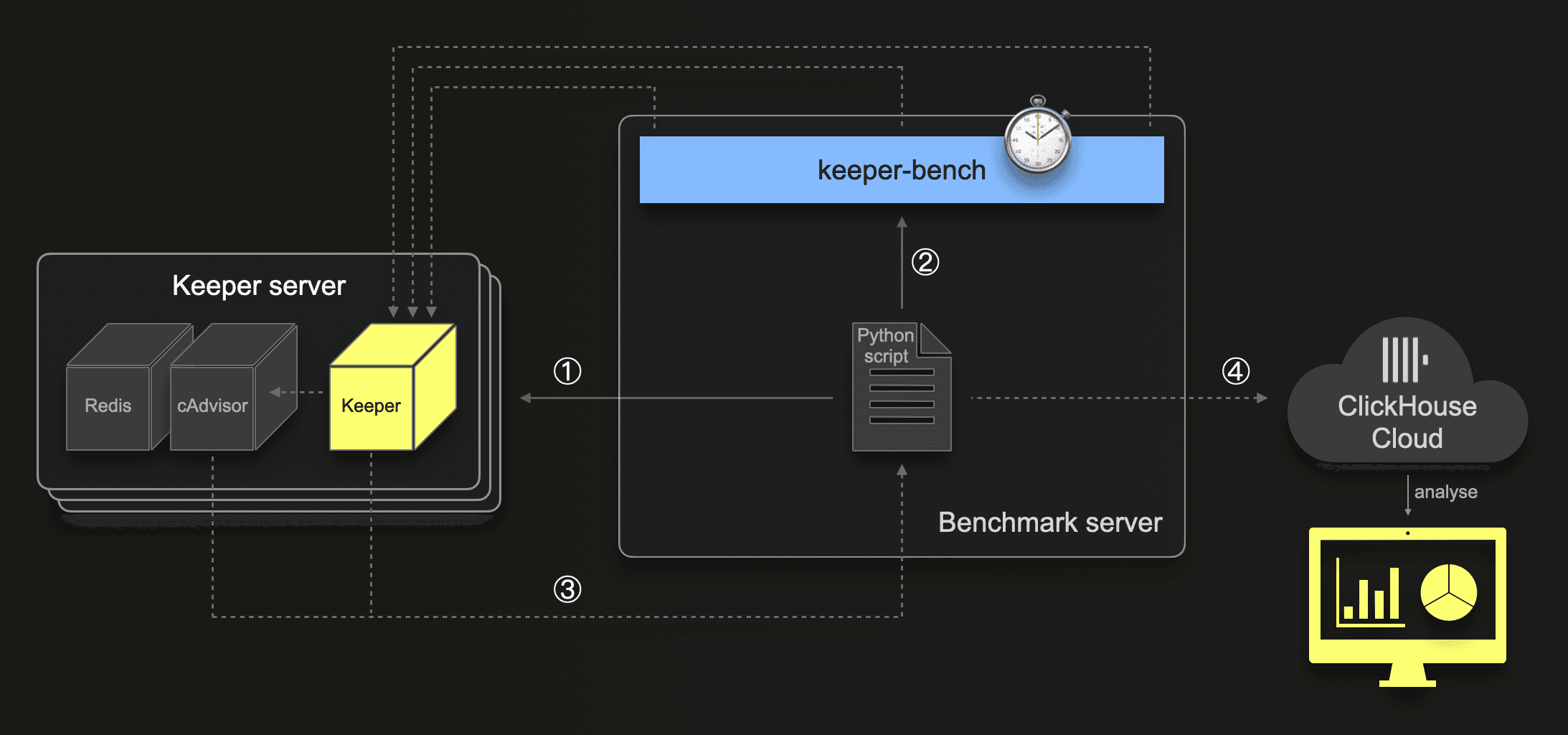 We are using an AWS EC2 instance as a benchmark server for executing a Python script which
We are using an AWS EC2 instance as a benchmark server for executing a Python script which
① sets up and starts a 3-node Keeper cluster by spinning up 3 appropriate (e.g., m6a.4xlarge) EC2 instances, each running one Keeper docker container and two containers with cAdvisor and Redis (required by cAdvisor) for monitoring the resource usage of the local Keeper container
② starts keeper-bench with a preconfigured workload configurations
③ scrapes the Prometheus endpoints of each cAdvisor and Keeper every 1 second
④ writes the scraped metrics including timestamps into two tables in a ClickHouse Cloud service which is the basis for conveniently analyzing the metrics via SQL queries, and Grafana dashboards
Note that both ClickHouse Keeper and ZooKeeper directly provide Prometheus endpoints. Currently, these endpoints only have a very small overlap and generally give quite different metrics, which makes it hard to compare them, especially in terms of memory and CPU usage. Therefore, we opted for additional cAdvisor-based basic container metrics. Plus, running Keeper in a docker container allows us to easily change the number of CPU cores and size of RAM provided to Keeper.
Configuration parameters
Size of Keeper
We run benchmarks with different docker container sizes for both ClickHouse Keeper and ZooKeeper. E.g. 1 CPU core + 1 GB RAM, 3 CPU cores + 1 GB RAM, 6 CPU cores + 6 GB RAM.
Number of clients and requests
For each of the Keeper sizes, we simulate (with the concurrency setting of keeper-bench) different numbers of clients (e.g., ClickHouse servers) sending requests in parallel to Keeper: E.g. 3, 10, 100, 500, 1000.
From each of these simulated clients, to simulate both short and long-running Keeper sessions, we send (with the iterations setting of keeper-bench) a total number between 10 thousand and ~10 million requests to Keeper. This aims to test whether memory usage of either component changes over time.
Workload
We simulated a typical ClickHouse workload containing ~1/3 write and delete operations and ~2/3 reads. This reflects a scenario where some data is ingested, merged, and then queried. It is easily possible to define and benchmark other workloads.
Measured metrics
Prometheus endpoints
We use the Prometheus endpoint of cAdvisor for measuring
- Main memory usage (container_memory_working_set_bytes)
- CPU usage (container_cpu_usage_seconds_total)
We use the Prometheus endpoints of ClickHouse Keeper and ZooKeeper for measuring additional (all available) Keeper Prometheus endpoint metric values. E.g. for ZooKeeper, many JVM-specific metrics (heap size and usage, garbage collection, etc.).
Runtime
We also measure the runtime for Keeper processing all requests based on the minimum and maximum timestamps from each run.
Results
We used the keeper-bench-suite to compare the resource consumption and runtime of ClickHouse Keeper and ZooKeeper for our workload. We ran each benchmark configuration 10 times and stored the results in two tables in a ClickHouse Cloud service. We used a SQL query for generating three tabular result tables:
The columns of these results are described here.
We used ClickHouse Keeper 23.5 and ZooKeeper 3.8. (with bundled OpenJDK 11) for all runs.
Note that we don’t print the three tabular results here, as each table contains 216 rows. You can inspect the results by following the links above.
Example Results
Here, we present two charts, where we filtered the 99th percentile results for rows where both Keeper versions run with 3 CPU cores and 2 GB of RAM, processing the same request sizes sent from 3 simulated clients (ClickHouse servers) in parallel. The tabular result for these visualizations is here.
Memory usage
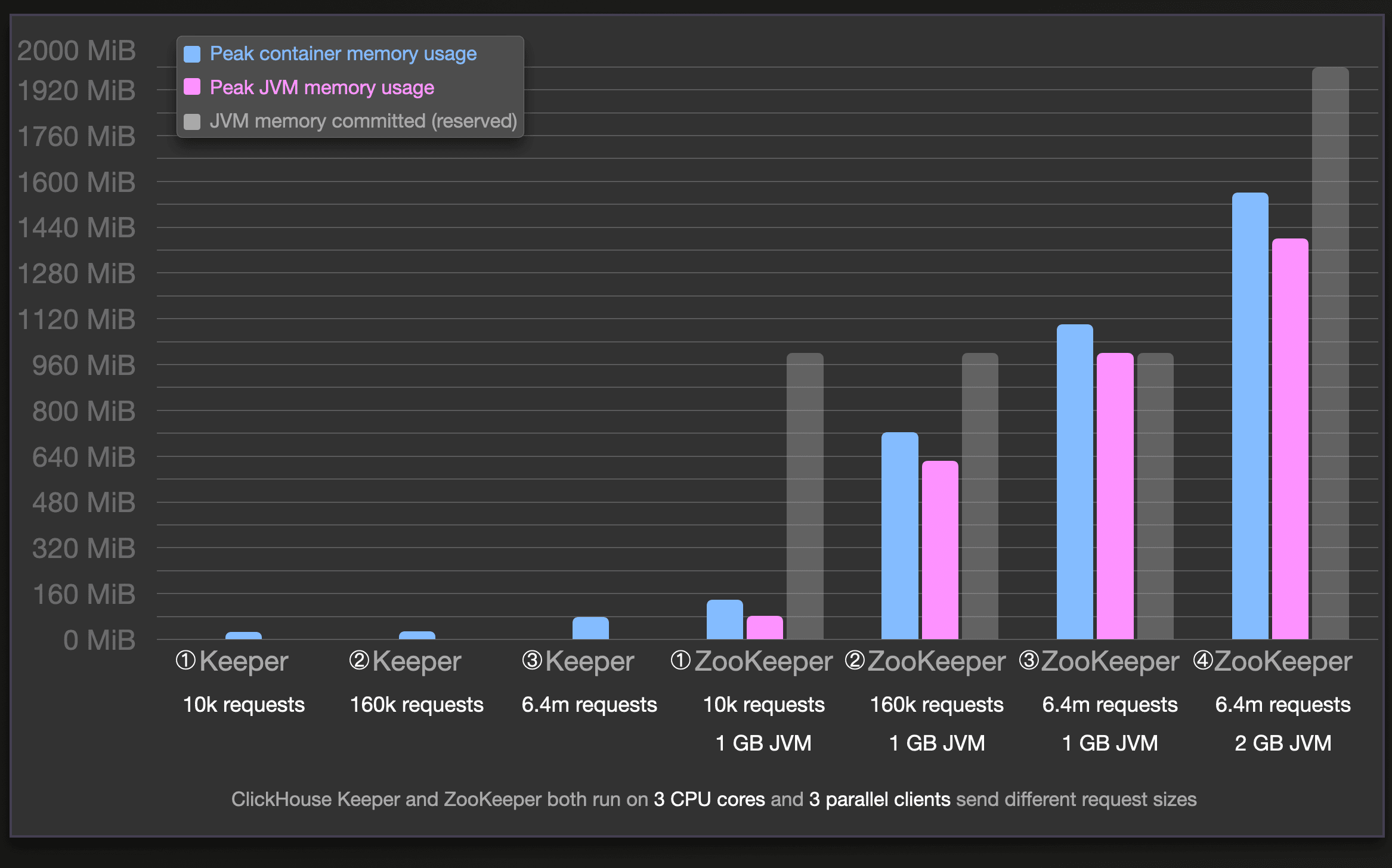 We can see that for our simulated workload, ClickHouse Keeper consistently uses a lot less main memory than ZooKeeper for the same number of processed requests. E.g. for the benchmark run ③ processing 6.4 million requests sent by 3 simulated ClickHouse servers in parallel, ClickHouse Keeper uses ~46 times less main memory than ZooKeeper in run ④.
We can see that for our simulated workload, ClickHouse Keeper consistently uses a lot less main memory than ZooKeeper for the same number of processed requests. E.g. for the benchmark run ③ processing 6.4 million requests sent by 3 simulated ClickHouse servers in parallel, ClickHouse Keeper uses ~46 times less main memory than ZooKeeper in run ④.
For ZooKeeper, we used a 1GiB JVM heap size configuration (JVMFLAGS: -Xmx1024m -Xms1024m) for all main runs (①, ②, ③), meaning that the committed JVM memory (reserved heap and non-heap memory is guaranteed to be available for use by the Java virtual machine) size is ~1GiB for these runs (see the transparent gray bars in the chart above for how much is used). In addition to the docker container memory usage (blue bars), we also measured the amount of (heap and non-heap) JVM memory actually used within the committed JVM memory (pink bars). There is some slight container memory overhead (difference of blue and pink bars) of running the JVM itself. However, the actual used JVM memory is still consistently significantly larger than the overall container memory usage of ClickHouse Keeper.
Furthermore, we can see that ZooKeeper uses the complete 1 GiB JVM heap size for run ③. We did an additional run ④ with an increased JVM heap size of 2 GiB for ZooKeeper, resulting in ZooKeeper using 1.56 GiB of its 2 GiB JVM heap, with an improved runtime matching the runtime of ClickHouse Keeper’s run ③. We present runtimes for all runs above in the next chart.
We can see in the tabular result that (major) garbage collection takes place a few times during the ZooKeeper runs.
Runtime and CPU usage
The following chart visualizes runtimes and CPU usages for the runs discussed in the previous chart (the circled numbers are aligned in both charts):
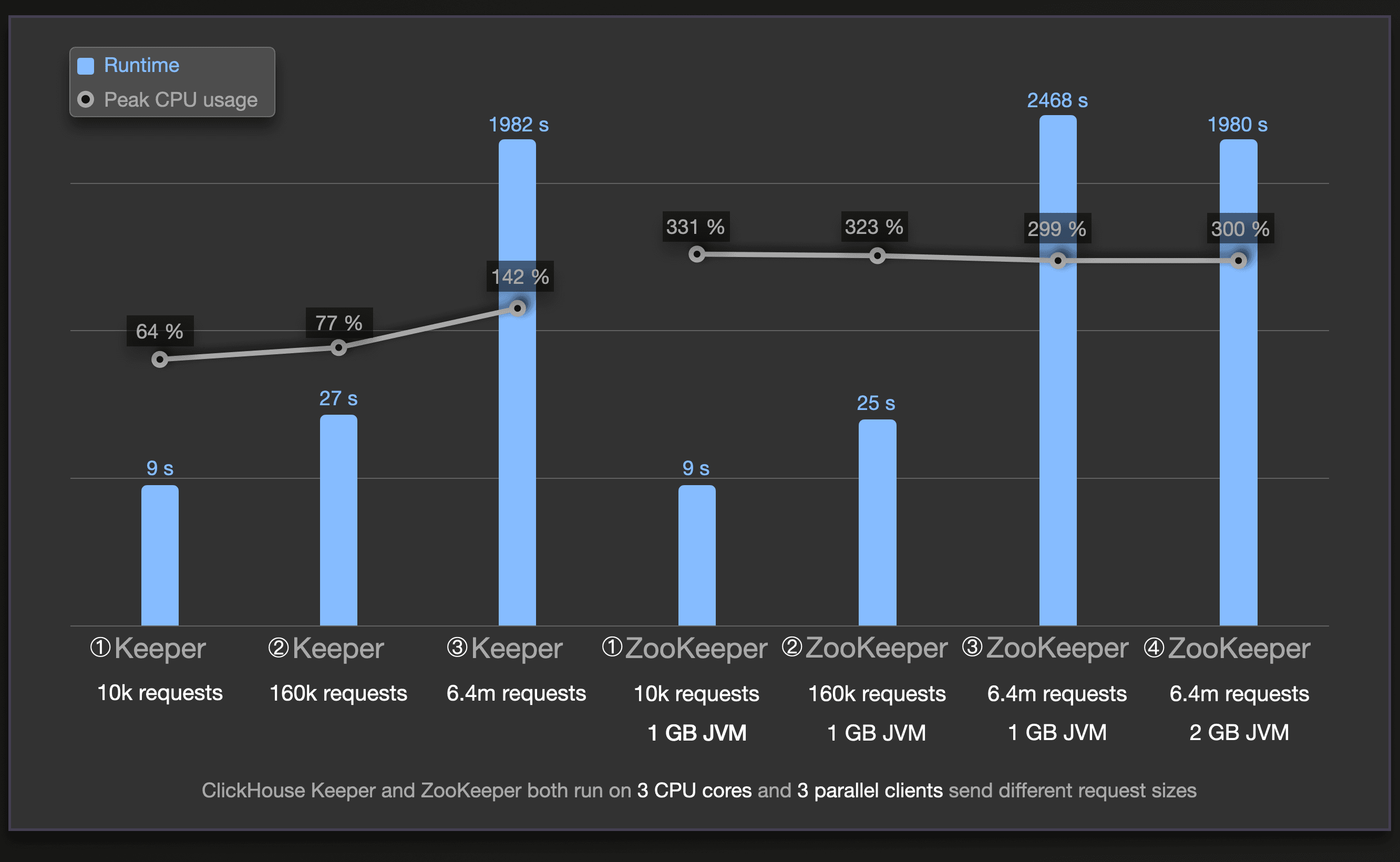 ClickHouse Keeper’s runtimes closely match ZooKeeper’s runtimes. Despite using significantly less main memory (see the previous chart) and CPU.
ClickHouse Keeper’s runtimes closely match ZooKeeper’s runtimes. Despite using significantly less main memory (see the previous chart) and CPU.
Scaling Keeper
We observed that ClickHouse Cloud often uses multi-write transactions in interactions with Keeper. We zoom in a bit deeper into ClickHouse Cloud’s interactions with Keeper to sketch two main scenarios for such Keeper transactions used by ClickHouse servers.
Automatic insert deduplication
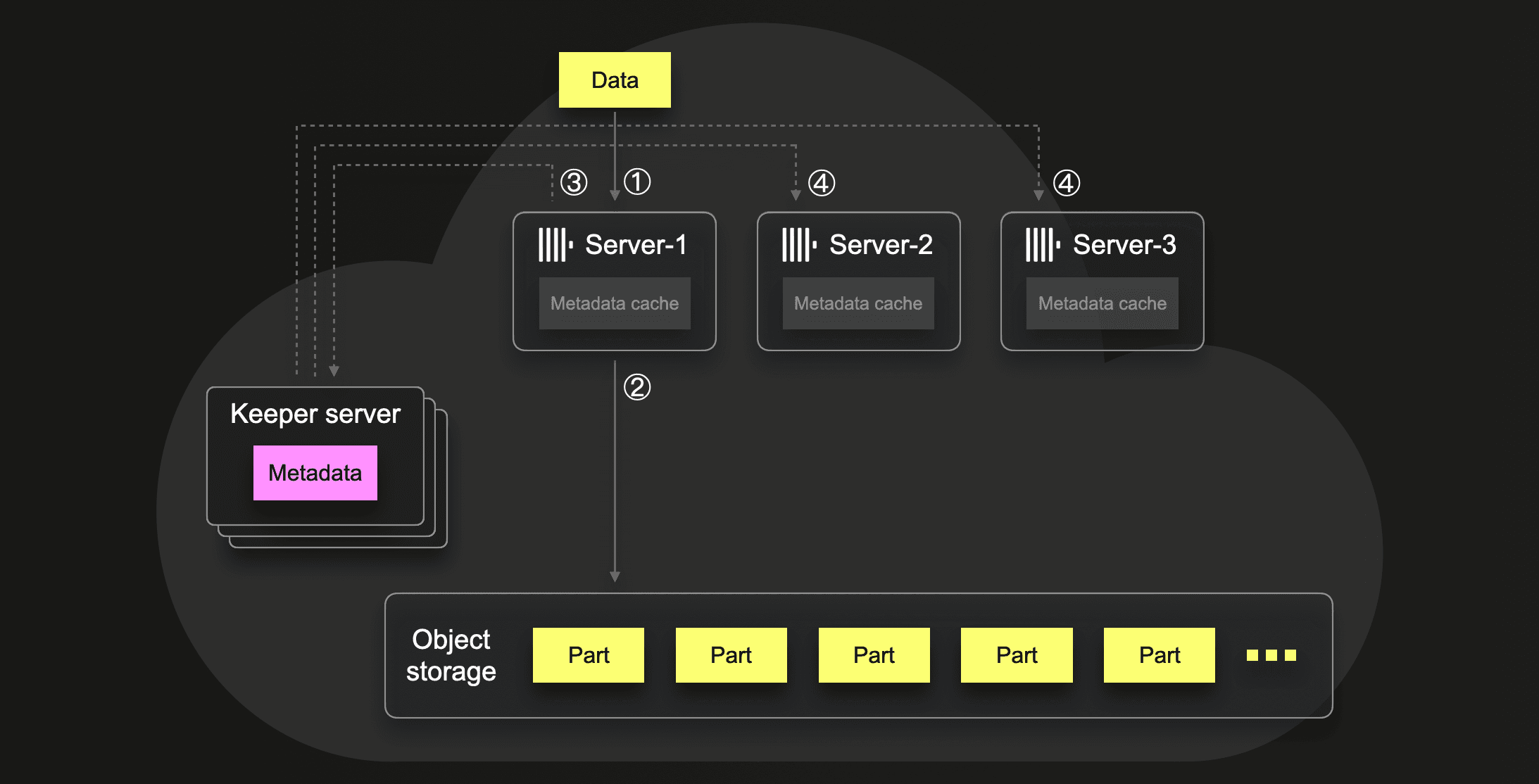 In the scenario sketched above, server-2 ① processes data inserted into a table block-wise. For the current block, server-2 ② writes the data into a new data part in object storage, and ③ uses a Keeper multi-write transaction for storing metadata about the new part in Keeper, e.g., where the blobs corresponding to part files reside in object storage. Before storing this metadata, the transaction first tries to store the hash sum of the block processed in step ① in a
In the scenario sketched above, server-2 ① processes data inserted into a table block-wise. For the current block, server-2 ② writes the data into a new data part in object storage, and ③ uses a Keeper multi-write transaction for storing metadata about the new part in Keeper, e.g., where the blobs corresponding to part files reside in object storage. Before storing this metadata, the transaction first tries to store the hash sum of the block processed in step ① in a deduplication log znode in Keeper. If the same hash sum value already exists in the deduplication log, then the whole transaction fails (is rolled back). Additionally, the data part from step ② is deleted because the data contained in that part was already inserted in the past. This automatic insert deduplication makes ClickHouse inserts idempotent and, therefore, failure-tolerant, allowing clients to retry inserts without risking data duplication. On success, the transaction triggers child watches, and ④ all Clickhouse servers subscribed to events for the part-metadata znodes are automatically notified by Keeper about new entries. This causes them to fetch metadata updates from Keeper into their local metadata caches.
Assigning part merges to servers
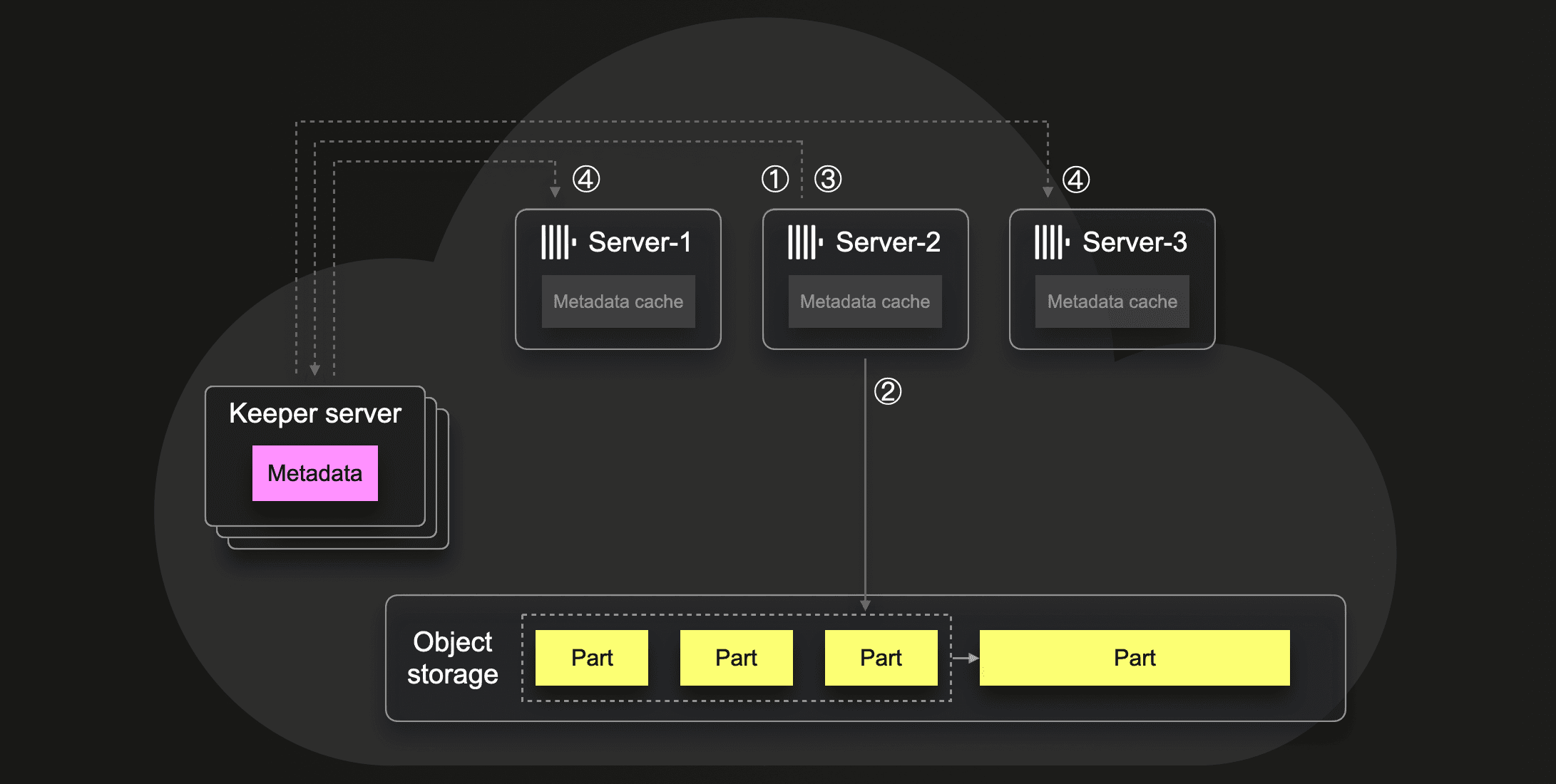 When server-2 decides to merge some parts into a larger part, then the server ① uses a Keeper transaction for marking the to-be-merged parts as locked (to prevent other servers from merging them). Next, server-2 ② merges the parts into a new larger part, and ③ uses another Keeper transaction for storing metadata about the new part, which triggers watches ④ notifying all other servers about the new metadata entries.
When server-2 decides to merge some parts into a larger part, then the server ① uses a Keeper transaction for marking the to-be-merged parts as locked (to prevent other servers from merging them). Next, server-2 ② merges the parts into a new larger part, and ③ uses another Keeper transaction for storing metadata about the new part, which triggers watches ④ notifying all other servers about the new metadata entries.
Note that the above scenarios can only work correctly if such Keeper transactions are executed by Keeper atomically and sequentially. Otherwise, two ClickHouse servers sending the same data in parallel at the same time could potentially both not find the data’s hash sum in the deduplication log resulting in data duplication in object storage. Or multiple servers would merge the same parts. To prevent this, the ClickHouse servers rely on Keeper’s all-or-nothing multi-write transactions plus its linearizable writes guarantee.
Linearizability vs multi-core processing
The consensus algorithms in ZooKeeper and ClickHouse Keeper, ZAB, and Raft, respectively, both ensure that multiple distributed servers can reliably agree on the same information. e.g. which parts are allowed to be merged in the example above.
ZAB is a dedicated consensus mechanism for ZooKeeper and has been in development since at least 2008.
We chose Raft as our consensus mechanism because of its simple and easy-to-understand algorithm and the availability of a lightweight and easy-to-integrate C++ library when we started the Keeper project in 2021.
However, all consensus algorithms are isomorphic to each other. For linearizable writes, (dependent) transitions and the write operations within the transaction must be processed in strict order, one at a time, regardless of which consensus algorithm is used. Suppose ClickHouse servers are sending transactions in parallel to Keeper, and these transactions are dependent because they write to the same znodes (e.g., the deduplication log in our example scenario at the beginning of this section). In that case, Keeper can guarantee and implement linearizability only by executing such transactions and their operations strictly sequentially:
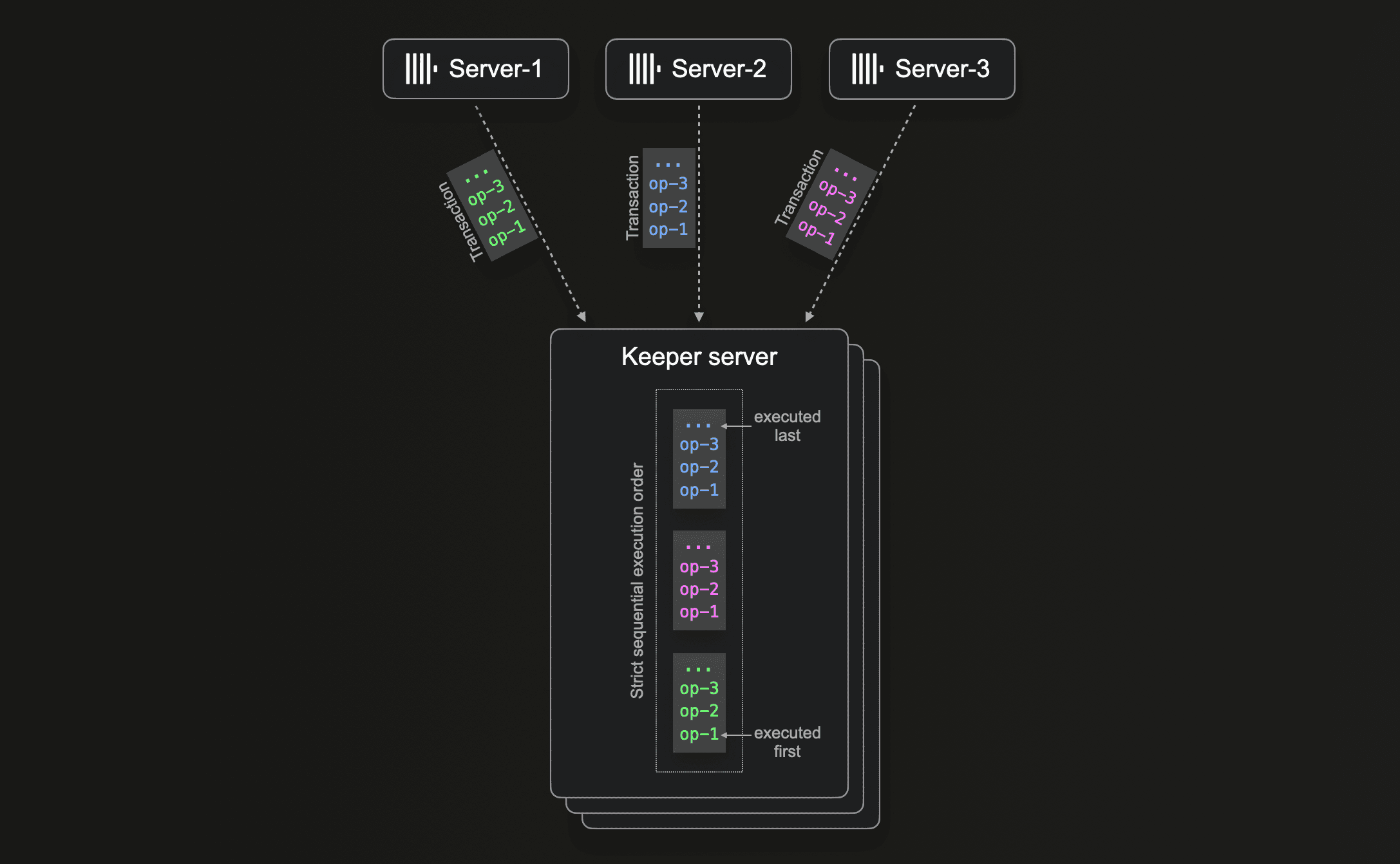 For this, ZooKeeper implements write request processing using a single-threaded request processor, whereas Keeper’s NuRaft implementation uses a single-threaded global queue.
For this, ZooKeeper implements write request processing using a single-threaded request processor, whereas Keeper’s NuRaft implementation uses a single-threaded global queue.
Generally, linearizability makes it hard to scale write processing speed vertically (more CPU cores) or horizontally (more servers). It would be possible to analyze and identify independent transactions and run them in parallel, but currently, neither ZooKeeper nor ClickHouse Keeper implements this. This chart (where we filtered the 99th percentile results) highlights this:
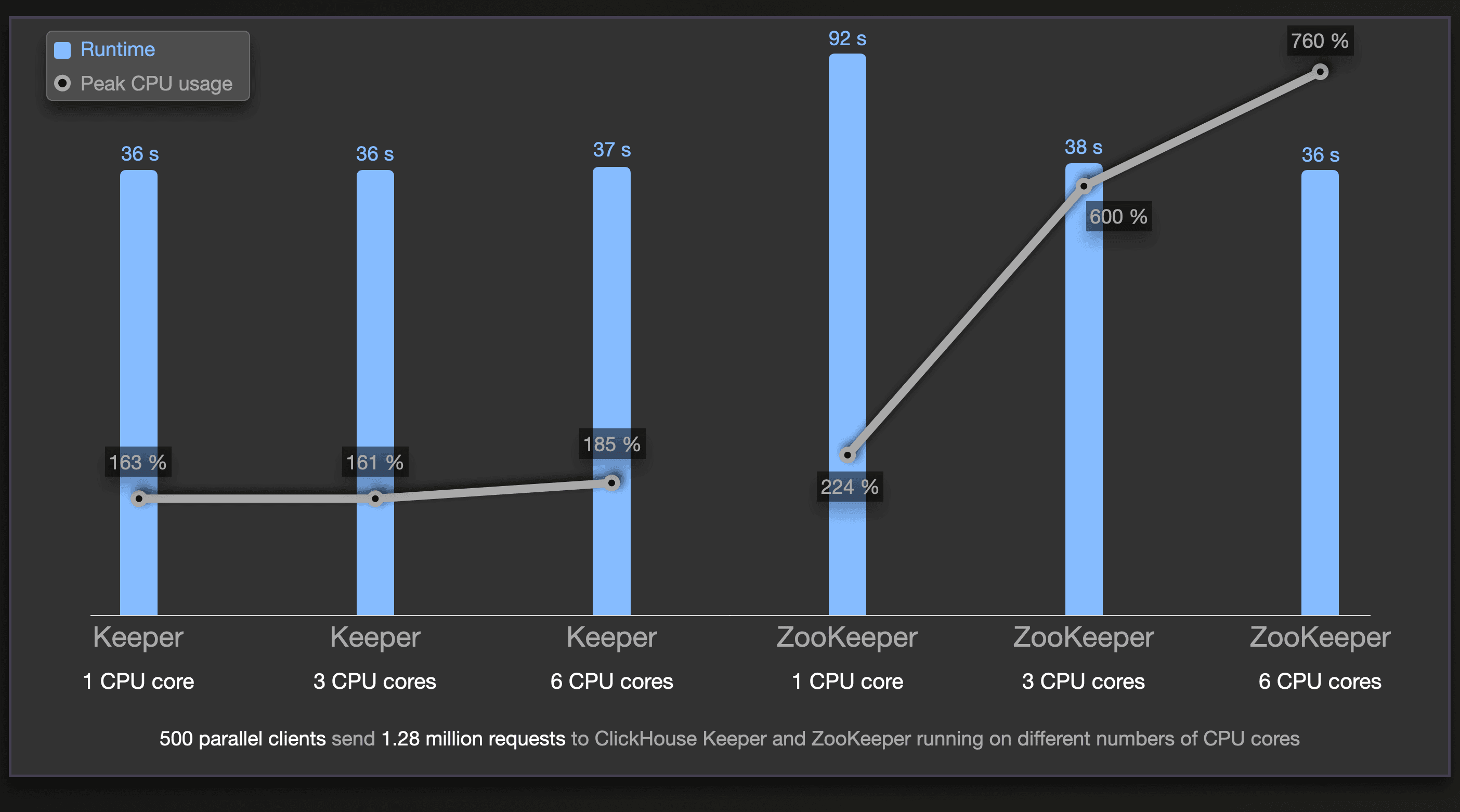 Both ZooKeeper and ClickHouse Keeper are running with 1, 3, and 6 CPU cores and processing 1.28 million total requests sent in parallel from 500 clients.
Both ZooKeeper and ClickHouse Keeper are running with 1, 3, and 6 CPU cores and processing 1.28 million total requests sent in parallel from 500 clients.
The performance of (non-linearizable) read requests and auxiliary tasks (managing network requests, batching data, etc.) can be scaled theoretically with the number of CPU cores with both ZAB and Raft. Our benchmark results generally show that ZooKeeper is currently doing this better than Clickhouse Keeper, although we are consistently improving our performance (three recent examples).
Next for Keeper: Multi-group Raft for Keeper, and more
Looking forward, we see the need to extend Keeper to better support the scenarios we described above. So, we are taking a big step with this project – introducing a multi-group Raft protocol for Keeper.
Because, as explained above, scaling non-partitioned (non-sharded) linearizability is impossible, we will focus on Multi-group Raft where we partition the data stored in Keeper. This allows more transactions to be independent (working over separate partitions) from each other. By using a separate Raft instance inside the same server for each partition, Keeper automatically executes independent transactions in parallel:
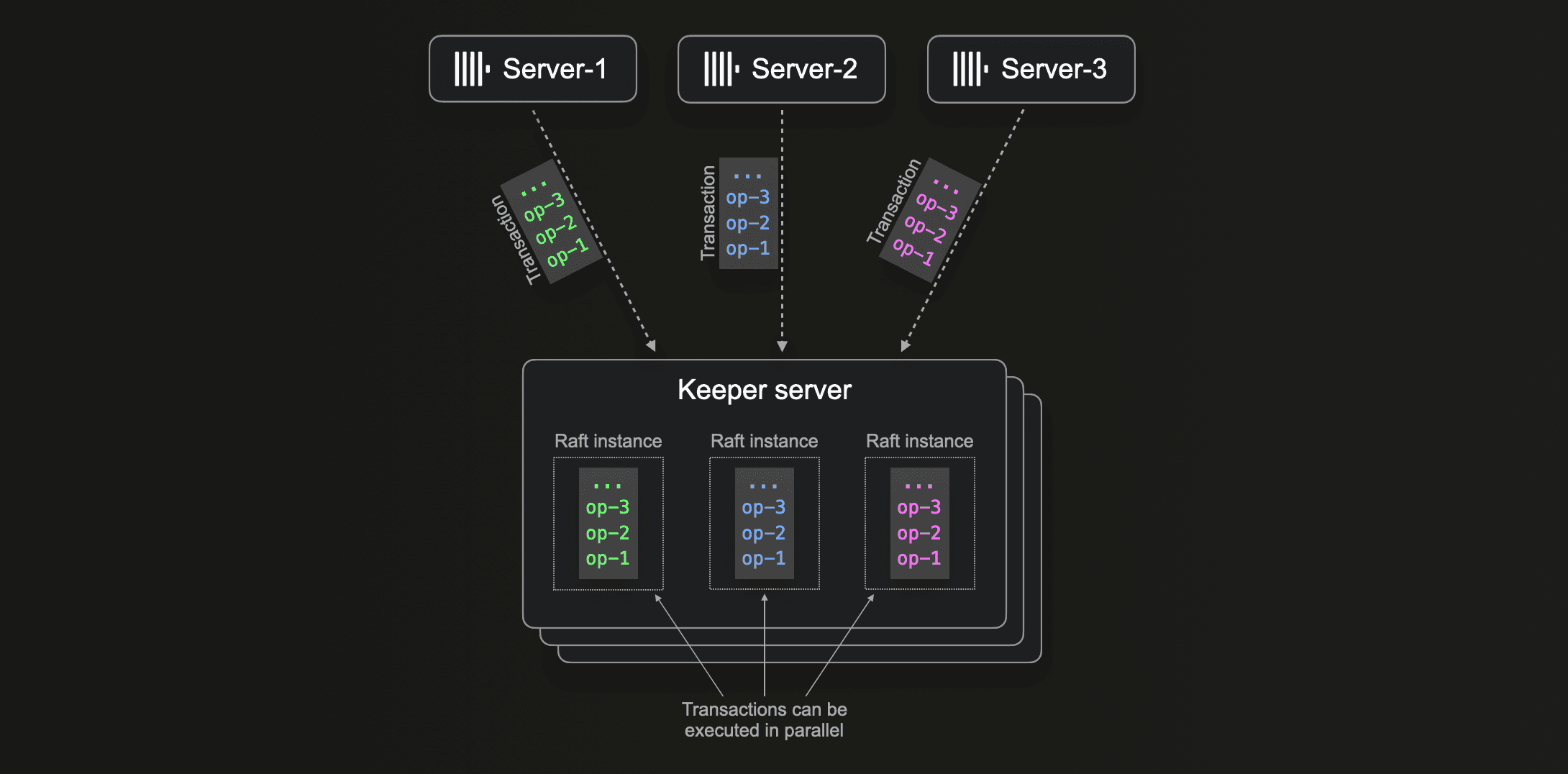 With multi-Raft, Keeper will be able to enable workloads with much higher parallel read/write requirements, such as for instance, very large ClickHouse clusters with 100s of nodes.
With multi-Raft, Keeper will be able to enable workloads with much higher parallel read/write requirements, such as for instance, very large ClickHouse clusters with 100s of nodes.
Join the Keeper community!
Sounds exciting? Then, we invite you to join the Keeper community.
- This is how you use Keeper with ClickHouse
- To become a user of Keeper outside of ClickHouse - check out this page when to use it or not
- This is where you post questions; you can follow us on X and join our meetups and events.
We welcome contributions to the Keeper codebase. See our roadmap here, and see our contributor guidelines here.
Summary
In this blog post, we described the features and advantages of ClickHouse Keeper - a resource-efficient open-source drop-in replacement for ZooKeeper. We explored our own usage of it in ClickHouse Cloud and, based on this, presented a benchmark suite and results highlighting that ClickHouse Keeper consistently uses significantly fewer hardware resources than ZooKeeper with comparable performance numbers. We also shared our roadmap and ways you can get involved. We invite you to collaborate!


