Introduction
You’ve probably heard the lore that 80% of a machine learning practitioner's time is spent dealing with - or cleaning - data. Regardless of whether this myth holds, what certainly remains true is that data is at the heart of the machine learning problem, from start to finish. Whether you’re building RAG pipelines, fine-tuning, training your own model, or evaluating model performance, data is the root of each problem.
But managing data can be tricky - and as a byproduct, the space has experienced a proliferation of tools that are designed to boost productivity by solving a specific slice of a machine learning data problem. Oftentimes, this takes shape as a layer of abstraction around a more general-purpose solution with an opinionated interface that, on the surface, makes it easier to apply to the specific subproblem at hand. In effect, this reduces the flexibility that exists with a general-purpose solution in favor of ease-of-use and simplicity of a specific task.
That said, there are several drawbacks to this approach. A cascading suite of specialized tools, products, and services - in contrast with a general-purpose solution coupled with supporting application code - presents the risk of greater architectural complexity and data costs. It’s easy to accidentally find yourself with an endless list of tools and services, each used for just a single step.
 Sprawling machine learning landscape
Sprawling machine learning landscape
There are two common dimensions to these risks:
-
Learning, maintenance, and switching costs
Machine learning architectures can become so cluttered with various tools and components that it creates a fragmented and challenging environment to learn and manage, with increased points of failure and expense creep.
-
Data duplication and transfer costs
Using several discrete yet overlapping data systems in a machine learning pipeline may introduce an unnecessary, and often costly, overhead of shipping data around from one to another.
A great illustration of this tradeoff is the vector database. Vector databases are designed for the hyper-specific machine learning task of storing and searching across vectors. While this may be the right choice in some architectures, a vector database may be an unnecessary new addition to the tech stack in others, as it is yet another system to integrate with, manage, and ship data to and from. Most modern general-purpose databases come with vector support out-of-the-box (or through a plugin) and have more extensive and cross-cutting capabilities. In other words, there may be no need for a net new database to specifically handle vectors in those architectures at all. The importance boils down to whether the vector-specific convenience features (e.g. inbuilt embedding models) are mission-critical and worth the cost.
And so the question becomes: when is it better to use a single database or data warehouse versus several of these specialized tools? In the following article, we’ll describe how ClickHouse - a real-time data warehouse - is well suited to serve as the central datastore to power the machine learning data layer, having the potential to help simplify overall infrastructure and enhance long-term developer efficiency.
The machine learning data layer

Data exploration and preparation
Data exploration
After defining the machine learning problem, goals, and success criteria - a common next step is to explore the relevant data that will be used for model training and evaluation.
During this step, data is analyzed to understand its characteristics, distributions, and relationships. This process of evaluation and understanding becomes an iterative one, often resulting in a series of ad-hoc queries being executed across datasets, where query responsiveness is critical (along with other factors such as cost-efficiency and accuracy). As companies store increasing amounts of data to leverage for machine learning purposes, this problem - the problem of examining the data you have - becomes harder.
This is because analytics and evaluation queries often become tediously or prohibitively slow at scale with traditional data systems. Some of the big players impose significantly increased costs to bring down query times, and disincentivize ad-hoc evaluation by way of charging per query or by number of bytes scanned. Engineers may resort to pulling subsets of data down to their local machines as a compromise for these limitations.
ClickHouse, on the other hand, is a real-time data warehouse, so users benefit from industry-leading query speeds for analytical computations. Further, ClickHouse delivers high performance from the start, and doesn’t gate critical query-accelerating features behind higher pricing tiers. ClickHouse can also query data directly from object storage or data lakes, with support for common formats such as Iceberg, Delta Lake, and Hudi. This means that no matter where your data lives, ClickHouse can serve as a unifying access and computation layer for your machine learning workloads.
ClickHouse also has an extensive suite of pre-built statistical and aggregation functions that scale over petabytes of data, making it easy to write and maintain simple SQL that executes complex computations. With support for the most granular precision data types and codecs, you don't need to worry about reducing the granularity of your data.
“ClickHouse was perfect as Big Data Storage for our ML models” - Admixer
Data preparation and feature extraction
Data is then prepared - it’s cleaned, transformed, and used to extract the features by which the model will be trained and evaluated. This component is sometimes called a feature generation or extraction pipeline, and is another slice of the machine learning data layer where new tools could be introduced. MLOps players like Neptune and Hopsworks provide examples of the host of different data transformation products that are used to orchestrate pipelines like these. However, because they’re separate tools from the database they’re operating on, they can be brittle, and can cause disruptions that need to be manually rectified.
In contrast, data transformations are easily accomplished directly in ClickHouse through Materialized Views. These are automatically triggered when new data is inserted into ClickHouse source tables and are used to easily extract, transform, and modify data as it arrives - eliminating the need to build and monitor bespoke pipelines yourself.
And, when these transformations require aggregations over a complete dataset that may not fit into memory, leveraging ClickHouse ensures you don’t have to try and retrofit this step to work with dataframes on your local machine. For those datasets that are more convenient to evaluate locally, ClickHouse Local is a great alternative, along with chDB, that allows users the leverage ClickHouse with standard Python data libraries like Pandas.
"We collect tens of thousands of data points from customers’ phones and other more traditional sources. ClickHouse is used as a way to process all of these SMS messages and extract valuable information used for the scoring and fraud models." - QuickCheck
Training and evaluation
At this point, features will have been split into training, validation, and test sets. These data sets are versioned, and then utilized by their respective stages.
Here is where it is common to introduce yet another specialized tool - the feature store - to the machine learning data layer. A feature store is most commonly a layer of abstraction around a database that provides convenience features specific to managing data for model training, inference, and evaluation. Examples of these convenience features include versioning, access management, and automatically translating the definition of features to SQL statements.
Offline feature store
An offline feature store is used for model training. This generally means that the features themselves are produced through batch-process data transformation pipelines (as described in the above section), and there are typically no strict latency requirements on the availability of those features.
Online feature store
Online feature stores are used to store the latest version of features used for inference and are applied in real-time. This means that these features need to be calculated with minimal latency, as they’re used as part of a real-time machine learning service.
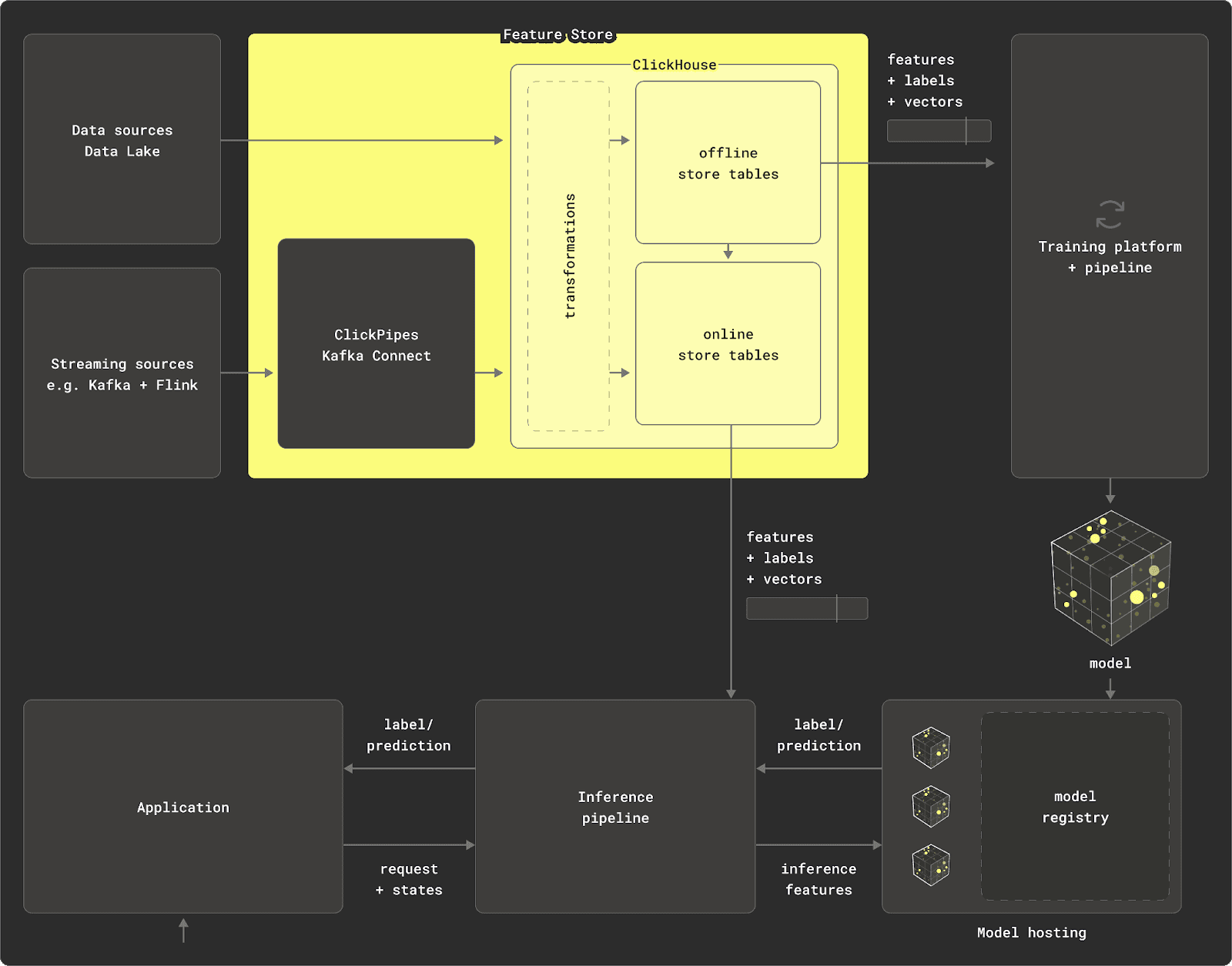 Powering feature stores with ClickHouse
Powering feature stores with ClickHouse
Many modern systems require both offline and online stores, and it is easy to jump to the conclusion that two specialized feature stores are required here. However, this introduces the additional complexity of keeping both of these stores in sync, which of course also includes the cost of replicating data between them.
A real-time data warehouse like ClickHouse is a single system that can power both offline and online feature management. ClickHouse efficiently processes streaming and historical data, and has the unlimited scale, performance, and concurrency needed to be relied upon when serving features for real-time inference and offline training.
In considering the tradeoffs between using a feature store product in this stage versus leveraging a real-time data warehouse directly, it’s worth emphasizing that convenience features such as versioning can be achieved through age-old database paradigms such as table or schema design. Other functionality, such as converting feature definitions to SQL statements, may provide greater flexibility as part of the application or business logic, rather than existing in an opinionated layer of abstraction.
"We aggregate the user’s history in ClickHouse and use it as a data store for training and inference. Even when reading 10s of millions of rows, the performance was very nice and not the bottleneck when training new models." - DeepL
Inference
Model inference is the process of running a trained model to receive an output. When inference is triggered by database actions - for instance, inserting a new record, or querying records - the inference step could be managed via bespoke jobs or application code.
On the other hand, it could be managed in the data layer itself. ClickHouse UDFs, or User Defined Functions, give users the ability to invoke a model directly from ClickHouse at insert or query time. This provides the ability to pass incoming data to a model, receive the output, and store these results along with the ingested data automatically - all without having to spin up other processes or jobs. This also provides a single interface, SQL, by which to manage this step.
"After Testing Hadoop and Spark, We Chose ClickHouse" - DENIC
Vector store
A vector store is a specific type of database that is optimized for storing and retrieving vectors, typically embeddings of a piece of data (such as text or images) that numerically capture their underlying meaning. Vectors are at the core of today’s generative AI wave and are used in countless applications.
The primary operation in a vector database is a “similarity search” to find the vectors that are “closest” to one another according to a mathematical measure. Vector databases have become popular because they employ specific tactics intended to make this examination - vector comparisons - as fast as possible. These techniques generally mean that they approximate the vector comparisons, instead of comparing the input vector to every vector stored.
The issue with this new class of tools is that many general-purpose databases, including ClickHouse, provide vector support out-of-the-box, and also often have implementations of those approximate approaches built-in. ClickHouse, in particular, is designed for high-performance large-scale analytics - allowing you to perform non-approximate vector comparisons very effectively. This means that you can achieve precise results, rather than having to rely on approximations, all without sacrificing speed.
Observability
Once your machine learning application is live, it will generate data, including logs and tracing data, that offer valuable insights into model behavior, performance, and potential areas for improvement.
SQL-based observability is another key use case for ClickHouse, where ClickHouse has been found to be 10-100x more cost effective than alternatives. In fact, many observability products are themselves built with ClickHouse under-the-hood. With best-in-class ingestion rates and compression ratios, ClickHouse provides cost-efficiency and blazing speed to power machine learning observability at any scale.
“ClickHouse helps us efficiently and reliably analyze logs across trillions of Internet requests to identify malicious traffic and provide customers with rich analytics.” - Cloudflare
Conclusion
With system architectures, it’s all about the tradeoffs. While the proliferation of tools, products, and services in the machine learning data layer may offer specific ease-of-use advantages for certain tasks, they also introduce risks, such as increased maintenance costs, architectural complexity, and data duplication expenses.
ClickHouse, a real-time data warehouse, provides the capacity to collapse many of these tools into a single data system. Rather than having a collection of products and services to help you accomplish each step, ClickHouse provides a central data store that efficiently manages all stages of the machine learning data workflow - from data exploration and preparation, to feature and vector storage, and finally, observability.
Interested in learning more? Contact us today or start your free trial and receive $300 in credits. Visit our pricing page for more details.


