This guest blog was originally published on Auxten's own blog. It has been updated with recent developments.
Introduction
Before officially starting the journey of chDB, I think it’s best to give a brief introduction to ClickHouse. In recent years, “vectorized engines” have been particularly popular in the OLAP database community. The main reason is the addition of more and more SIMD instructions in CPUs, which greatly accelerates Aggregation, Sort, and Join operations for large amounts of data in OLAP scenarios. ClickHouse has made very detailed optimizations in multiple areas such as “vectorization”, which can be seen from its optimizations for lz4 and memcpy.
If there is controversy about whether ClickHouse is the best-performing OLAP engine, at least it belongs to the top tier according to benchmarks. Apart from performance, ClickHouse also boasts powerful features that make it a Swiss Army Knife in the world of databases:
- Directly querying data stored on S3, GCS, and other object storages.
- Using ReplacingMergeTree to simplify handling changing data.
- Completing cross-database data queries and even table joins without relying on third-party tools.
- Even automatically performing Predicate Pushdown.
Developing and maintaining a production-ready and efficient SQL engine requires talent and time. As one of the leading OLAP engines, Alexey Milovidov and his team have dedicated 14 years to ClickHouse development. Since ClickHouse has done so much work on SQL engines already, why not consider extracting its engine into a Python module? It feels like installing a rocket engine onto a bicycle!
In February 2023, I started developing chDB with the main goal of making the powerful ClickHouse engine available as an “out-of-the-box” Python module. ClickHouse already has a standalone version called clickhouse-local that can be run from command line independently; this makes it even more feasible for chDB.
Hacking ClickHouse
There is a very simple and straightforward implementation to the problem of embedding ClickHouse in a Python module: directly include the clickhouse-local binary in the Python package, and then pass SQL to it through something like popen, retrieving the results through a pipe.
However, this approach brings several problems:
- Starting an independent process for each query would greatly impact performance, especially when the
clickhouse-localbinary file is approximately 500MB in size. - Multiple copies of SQL query results would be inevitable, since we would need to read it from both the pipe and copy into a buffer in the Python process.
- Integration with Python is limited, making it difficult to implement Python UDFs and support SQL on Pandas DataFrame.
- Most importantly, it lacks elegance ????
Thanks to ClickHouse’s well-structured codebase, I was able to successfully create a prototype during the Lunar New Year while either eating or hacking into ClickHouse’s 900k lines of code.
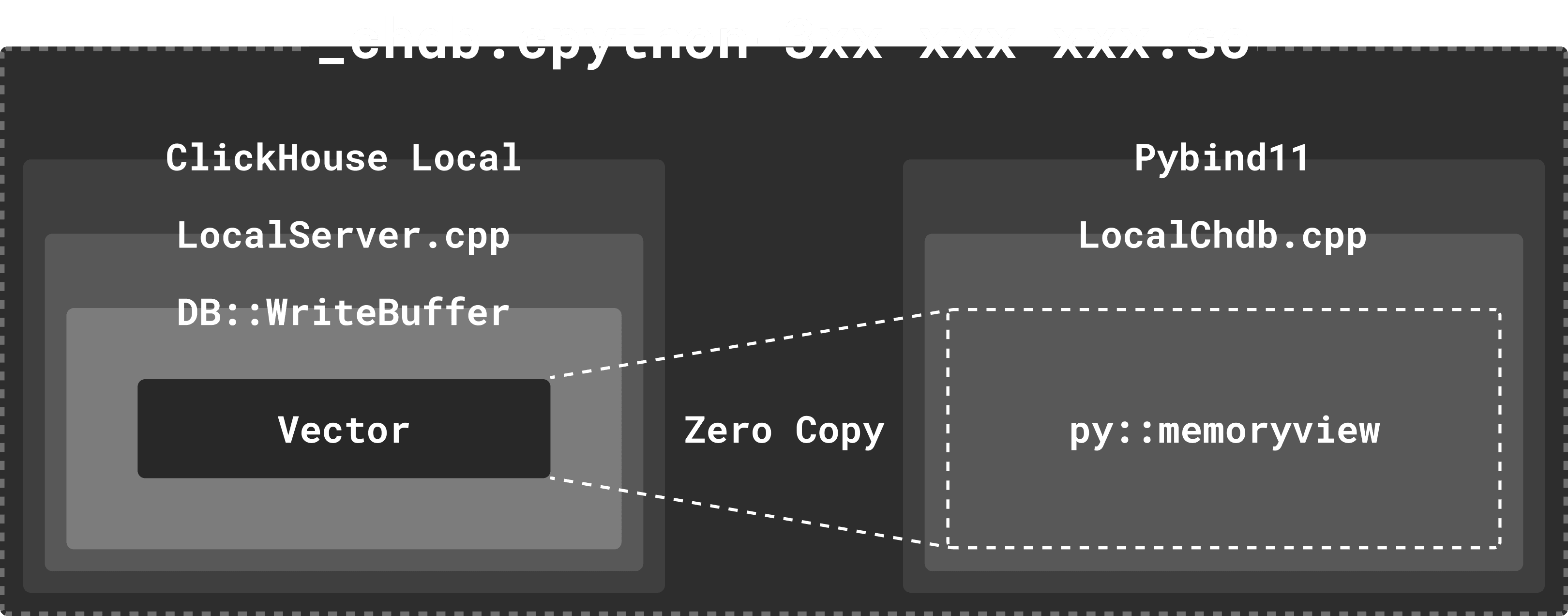
ClickHouse includes a series of implementations called BufferBase, including ReadBuffer and WriteBuffer, which correspond roughly to C++’s istream and ostream. In order to efficiently read from files and output results (e.g., reading CSV or JSONEachRow and outputting SQL execution results), ClickHouse’s Buffer also supports random access to underlying memory. It can even create new Buffers based on a vector without copying memory. ClickHouse internally uses derived classes of BufferBase for reading/writing compressed files as well as remote files (S3, HTTP).
To achieve zero-copy retrieval of SQL execution results at the ClickHouse level, I used the built-in WriteBufferFromVector instead of stdout for receiving data. This ensures that parallel output pipelines won’t be blocked while conveniently obtaining the original memory blocks of SQL execution outputs.
To avoid memory copying from C++ to Python objects, I utilized Python’s memoryview for direct memory mapping.
Due to the maturity of Pybind11, it is now easy to bind the construction and destruction of C++ classes with the lifecycle of Python objects. All this can be achieved with a simple class template definition:
class __attribute__((visibility("default"))) query_result {
public:
query_result(local_result * result) : result(result);
~query_result();
}
py::class_<query_result>(m, "query_result")
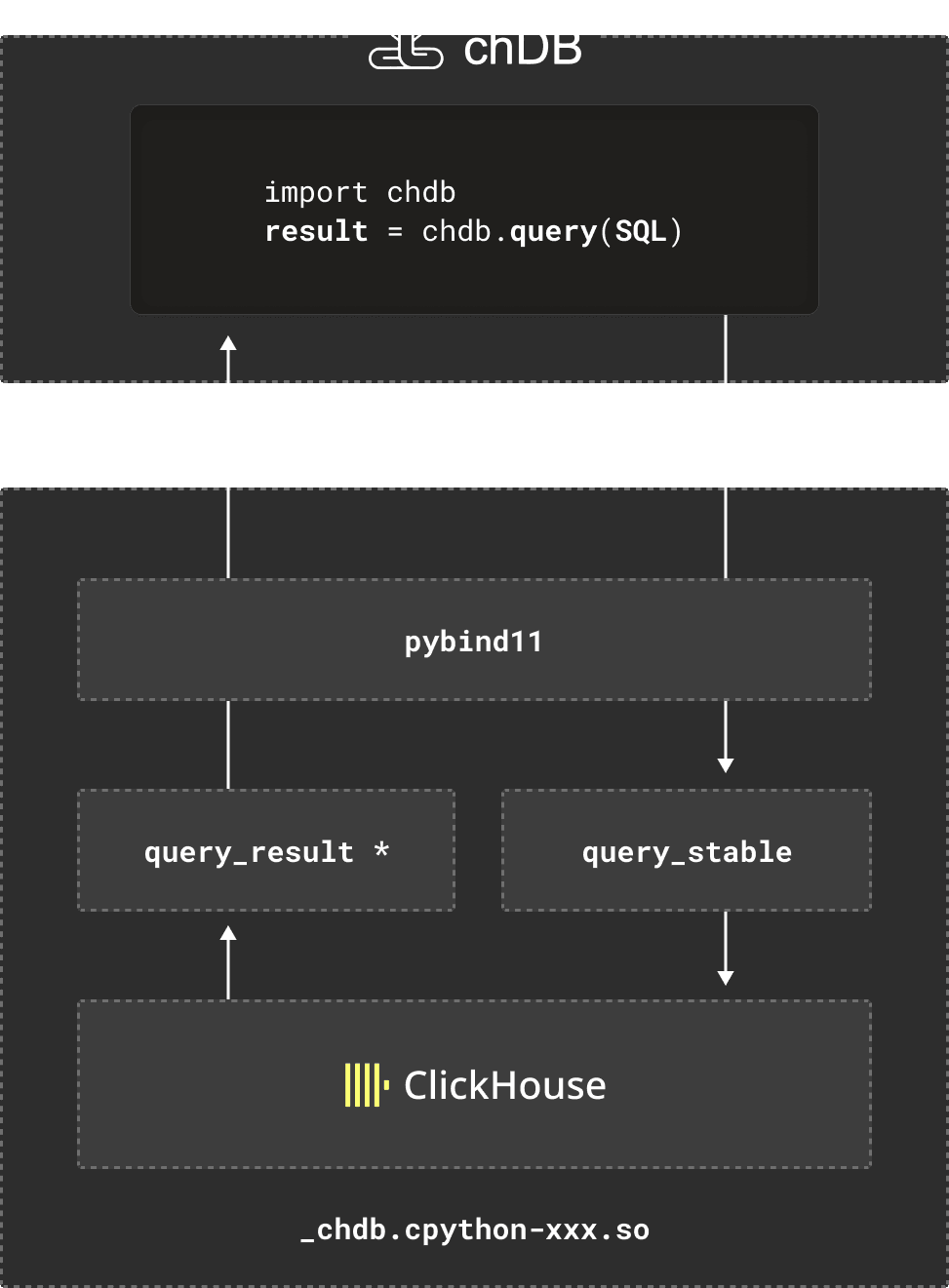
In this way, chDB was quickly up and running and I was very excited to release it. The architecture of chDB is roughly depicted in the following diagram:
Team up
Initially, I developed chDB with the sole purpose of creating a ClickHouse engine that could run independently in Jupyter Notebook. This would allow me to easily access large amounts of annotation information without having to rely on slow Hive clusters when training CV models using Python. Surprisingly, the standalone version of chDB actually outperformed the Hive cluster consisting of hundreds of servers in most scenarios.
After the release of chDB, Lorenzo from QXIP quickly contacted me. He raised an issue, suggesting that removing the dependency on AVX2 instruction set could make chDB more convenient to run on Lambda services. I promptly implemented this feature, and afterwards Lorenzo created a demo for chDB on fly.io. To be honest, I had never imagined such usage before.
Subsequently, Lorenzo and his team developed bindings for chDB in Golang, NodeJS andRust. To bring all these projects together, I created the chdb.io organization on GitHub.
Yes!, we also an experimental chDB FFI bindings for Bun on Linux.
Later on, @laodouya contributed an implementation of the Python DB API 2.0 interface for chDB. @nmreadelf added support for Dataframe output format in chDB. Friends such as @dchimeno, @Berry, @Dan Goodman, @Sebastian Gale, @Mimoune, @schaal, and @alanpaulkwan have also raised many valuable issues for chDB.
Jemalloc in so
chDB has alot of performance optimizations, including the extremely difficult task of porting jemalloc to chdb’s shared library.
After carefully analyzing chDB’s performance in Clickbench, it was found that there is a significant performance gap between chDB and clickhouse-local in Q23. It was believed that this difference was due to the fact that when implementing Q23, chDB simplified the process by removing jemalloc. So how did we fix it?
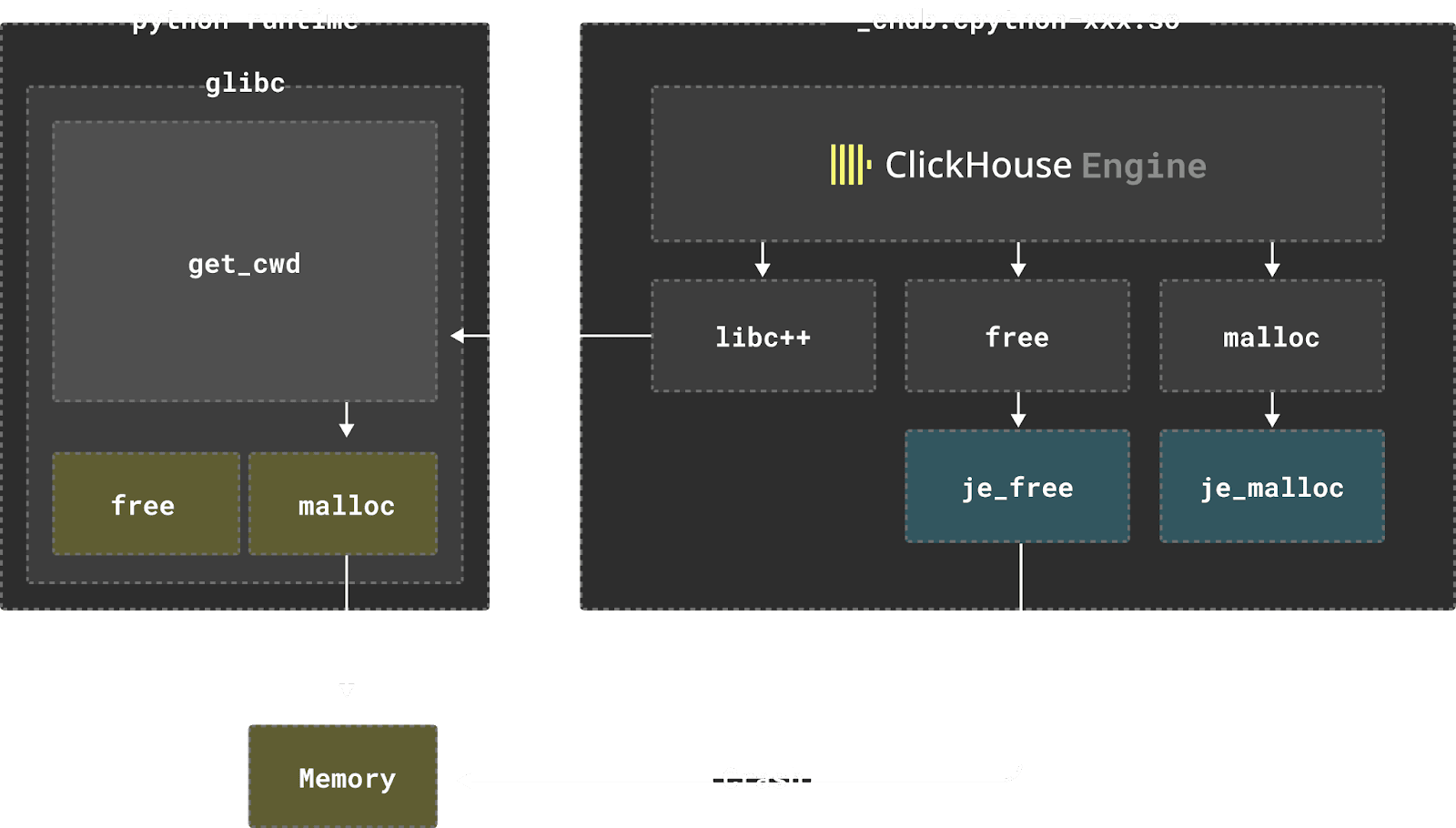
ClickHouse engine includes hundreds of submodules, including heavyweight libraries such as Boost and LLVM. In order to ensure good compatibility and to implement the JIT execution engine, ClickHouse statically links with its own LLVM versions of libc and libc++. This way the binary of ClickHouse can easily guarantee overall link security. However, for chDB, as a shared object (so), this part becomes exceptionally challenging due to several reasons:
- Python runtime has its own libc. After loading chdb.so, many memory allocation & management functions that should have been linked to jemalloc in the ClickHouse binary will unavoidably be connected to Python’s built-in libc through @plt.
- To solve the above problem, one solution is modifying ClickHouse source code so that all relevant functions are explicitly called with
je_prefix, such asje_malloc,je_free. But this approach brings two new problems; one of which can be easily solved.Modifying third-party library’s malloc calling code would be a huge project. Instead i used a trick when linking with clang++:-Wl,-wrap,malloc. For example, during the linking phase, all calls to malloc symbol are redirected to__wrap_malloc. You can refer to this piece of code in chDB: mallocAdapt.c
It seems like the issue has been resolved, but a real nightmare has emerged. chDB still occasionally crashes on some je_free calls. After relentless investigation, it was finally discovered to be an ancient legacy issue with libc:
When writing C code, malloc/calloc is generally paired with free. We will try our best to avoid returning memory allocated on the heap by malloc from within a function. This is because it can easily lead to the caller forgetting to call free, resulting in memory leaks.
However, due to historical legacy issues, there are certain functions in GNU libc such as getcwd() and get_current_dir_name() that internally call malloc to allocate their own memory and return it.
And these functions are widely used in libraries like STL and Boost for implementing path-related functions. Therefore, we encounter a situation where getcwd returns memory allocated by glibc’s version of malloc, but we attempt to release it using je_free. So… Crash!
Ideally jemalloc would provide an interface to query whether the memory pointed by a pointer is allocated by jemalloc. We just need to check it before calling je_free like below.
void __wrap_free(void * ptr)
{
int arena_ind;
if (unlikely(ptr == NULL))
{
return;bun
}
// in some glibc functions, the returned buffer is allocated by glibc malloc
// so we need to free it by glibc free.
// eg. getcwd, see: https://man7.org/linux/man-pages/man3/getcwd.3.html
// so we need to check if the buffer is allocated by jemalloc
// if not, we need to free it by glibc free
arena_ind = je_mallctl("arenas.lookup", NULL, NULL, &ptr, sizeof(ptr));
if (unlikely(arena_ind != 0)) {
__real_free(ptr);
return;
}
je_free(ptr);
}
But unfortunately, the mallctl of jemalloc can fail on assert when using arenas.lookup to query memory that was not allocated by jemalloc…
Lookup causing assertion failure? That’s clearly not ideal, so I submitted a patch to jemalloc: #2424 Make arenas_lookup_ctl triable. The official repository has already merged this PR. Therefore, I have now become a contributor to jemalloc.
Show time
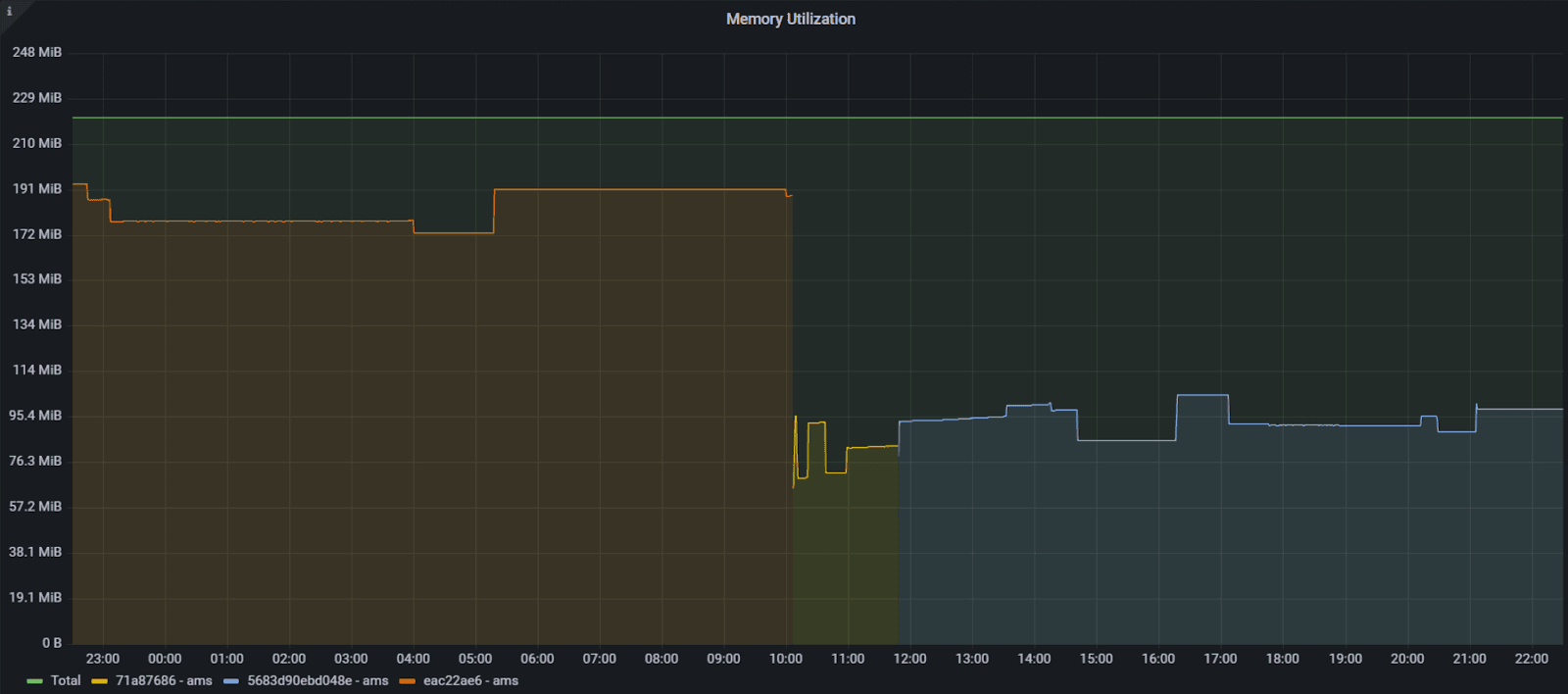
Through several weeks of effort on ClickHouse and jemalloc, the memory usage of chDB has been significantly reduced by 50%.
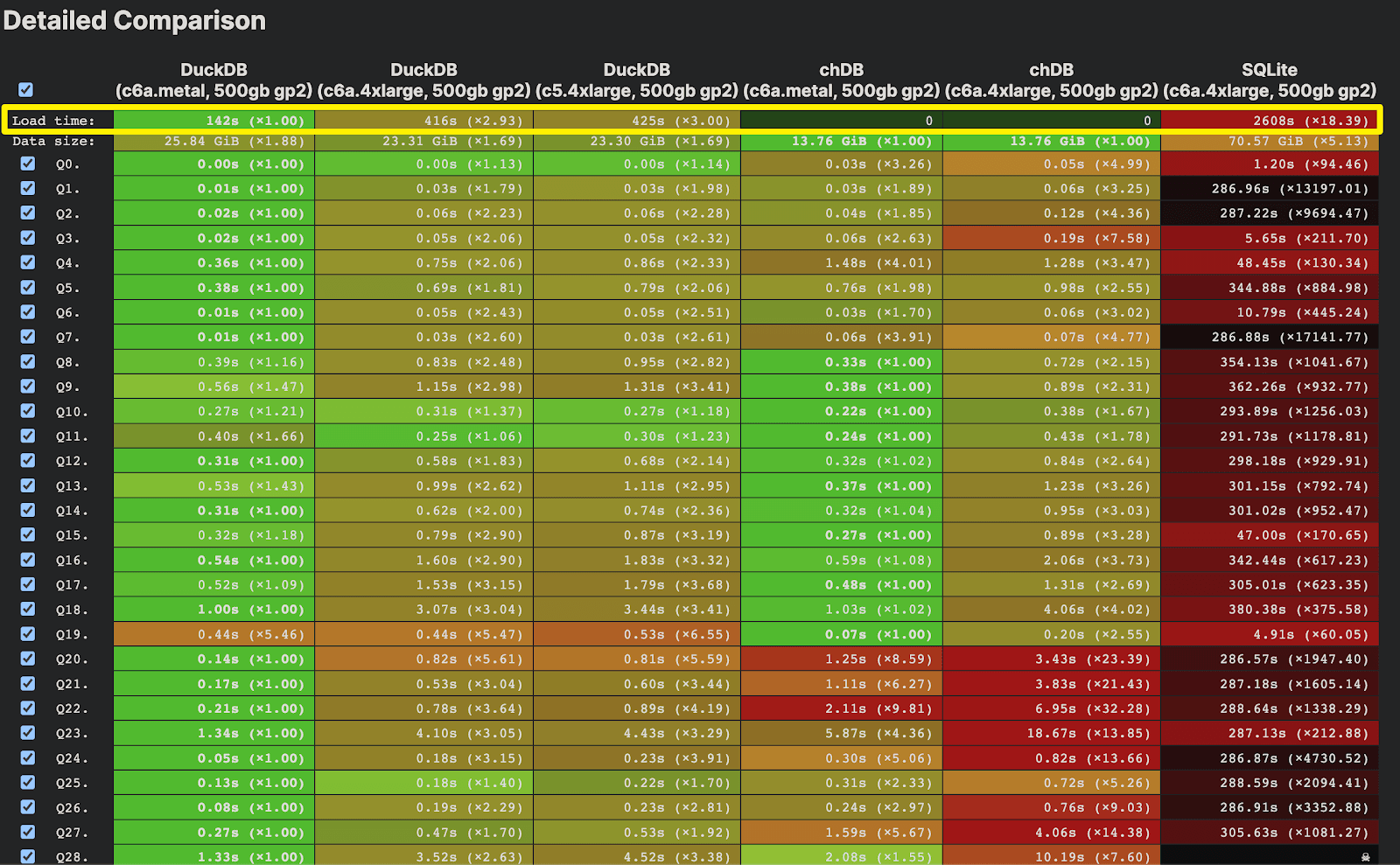
According to the data on ClickBench, chDB is currently the fastest stateless and serverless database(not including ClickHouse Web)
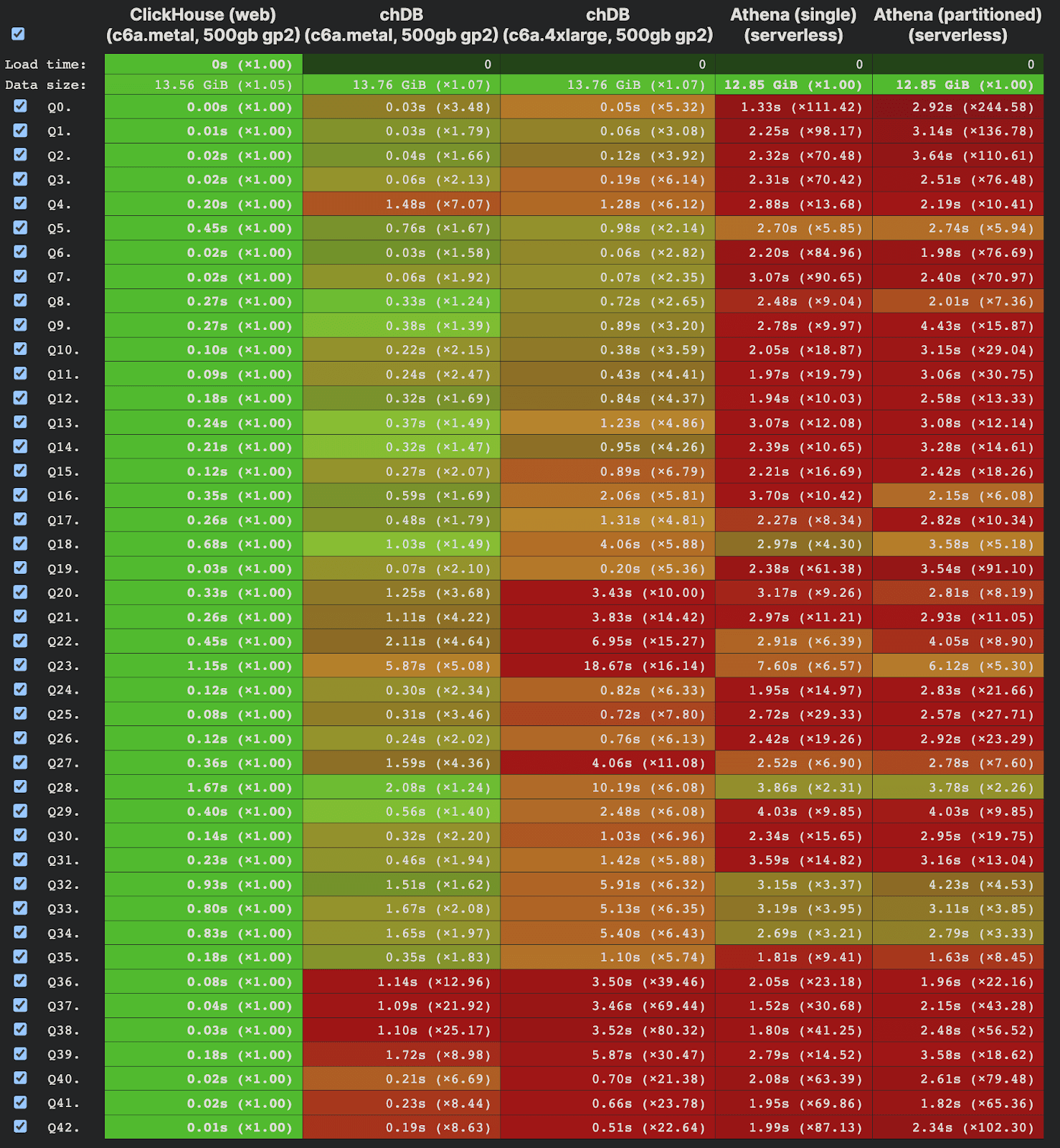
chDB is currently the fastest implementation of SQL on Parquet(The actual performance of DuckDB is achieved after a “Load” process that takes as long as 142~425 seconds.
Recent work
With the release of, chDB v0.14 ,let’s review what’s being going on recently:
-
v0.12 - Query on multiple Pandas DataFrame. You can even join Parquet with a DataFrame!
df1 = pd.DataFrame({'a': [1, 2, 3], 'b': ["one", "two", "three"]}) df2 = pd.DataFrame({'c': [1, 2, 3], 'd': ["ONE", "TWO", "THREE"]}) # Save df2 to Parquet file df2.to_parquet('df2.parquet') print("\n# Join DataFrame and Parquet:") print(cdf.query(sql="select * from __tbl1__ t1 join __tbl2__ t2 on t1.a = t2.c", tbl1=df1, tbl2=cdf.Table(parquet_path='df2.parquet'))) -
v0.13 - Get Query stats like
rows_read,bytes_read,time elapsed.# Query read_rows, read_bytes, elapsed time data = "file('hits_0.parquet', Parquet)" sql = f"""SELECT RegionID, SUM(AdvEngineID), COUNT(*) AS c, AVG(ResolutionWidth), COUNT(DISTINCT UserID) FROM {data} GROUP BY RegionID ORDER BY c DESC""" res = chdb.query(sql) print(f"\nSQL read {res.rows_read()} rows, {res.bytes_read()} bytes, elapsed {res.elapsed()} seconds") -
v0.14 - Python UDF (User-Defined Functions)
from chdb.udf import chdb_udf from chdb import query @chdb_udf() def sum_udf(lhs, rhs): return int(lhs) + int(rhs) print(query("select sum_udf(12,22)"))
Looking Forward
chDB was upgraded to ClickHouse 23.6 on v0.11, and the performance of running SQL on Parquet saw significant improvements. But wait, there's more! Just a few days ago, we were thrilled to discover that ClickHouse 23.8 has further optimized Parquet performance with "Parquet filter pushdown" . So, chDB with ClickHouse 23.8 is one the way!
We are also closely collaborating with the ClickHouse team in the following areas:
- Reducing the overall size of the chDB installation package as much as possible (currently compressed to around 100MB, and we hope to slim it down to 80MB this year)
- Table Function and UDAF (User-Defined Aggregate Functions) for chDB
- chDB already supports using Pandas Dataframe as input and output, and we will continue optimizing its performance in this area.
We welcome everyone to use chDB, and we also appreciate your support by giving us a Star on GitHub.
Here, I would like to express my gratitude to ClickHouse CTO @Alexey and Head of Product @Tanya for their support and encouragement. Without your help, there wouldn’t be today’s chDB!
Currently, chdb.io has 10 projects, where everyone is a loyal fan of ClickHouse. We are a group of hackers who “generate power with love”! Our goal is to create the most powerful and high-performance embedded database in the world!


