Introduction
Today, we welcome a guest post from our technology partner Streamkap, an out-of-the-box change data capture (CDC) solution for ClickHouse. This blog dives into the details and challenges of building such a product. For those of you who just want a working out-of-the-box CDC solution for ClickHouse, we are pleased to recommend Streamkap as a hosted service.
We’re excited to announce our new ClickHouse connector for streaming CDC data into ClickHouse from databases such as PostgreSQL, MySQL, SQL Server, Oracle & MongoDB.
Streamkap recently switched to ClickHouse to process all of our logs and metrics in real-time after we found that other solutions failed to achieve the query performance we required. Upon adopting ClickHouse ourselves, we wished to start offering a ClickHouse CDC integration but found issues with the existing connectors available, so we set out to build a new connector that addresses these issues.
In this post, we assume you’re familiar with the ClickHouse database and the concept of Change Data Capture (CDC), but if not, you can learn more by reading about Change Data Capture in Streaming.
We will dive into the challenges of building a CDC solution for ClickHouse and how we have addressed these, discussing how we handle schema evolution, data consistency, and snapshotting. Finally, we show this can all be achieved while maintaining a performant streaming pipeline.
Technologies
ClickHouse is an open-source column-oriented database. A column-oriented structure means data is stored and retrieved by columns rather than by rows. ClickHouse has become the de-facto choice for building real-time applications due to its ability to ingest large volumes as well as materialize the data at write instead of at read time. This results in significantly faster queries, making ClickHouse suitable for serving real-time applications.
Streamkap is a serverless streaming platform enabling real-time Change Data Capture (CDC) ingestion into ClickHouse. Under the hood, technologies such as Kafka, Debezium, Flink are combined with production-grade connectors/pipelines.
Here is an overview of how Streamkap streams from a database to ClickHouse.
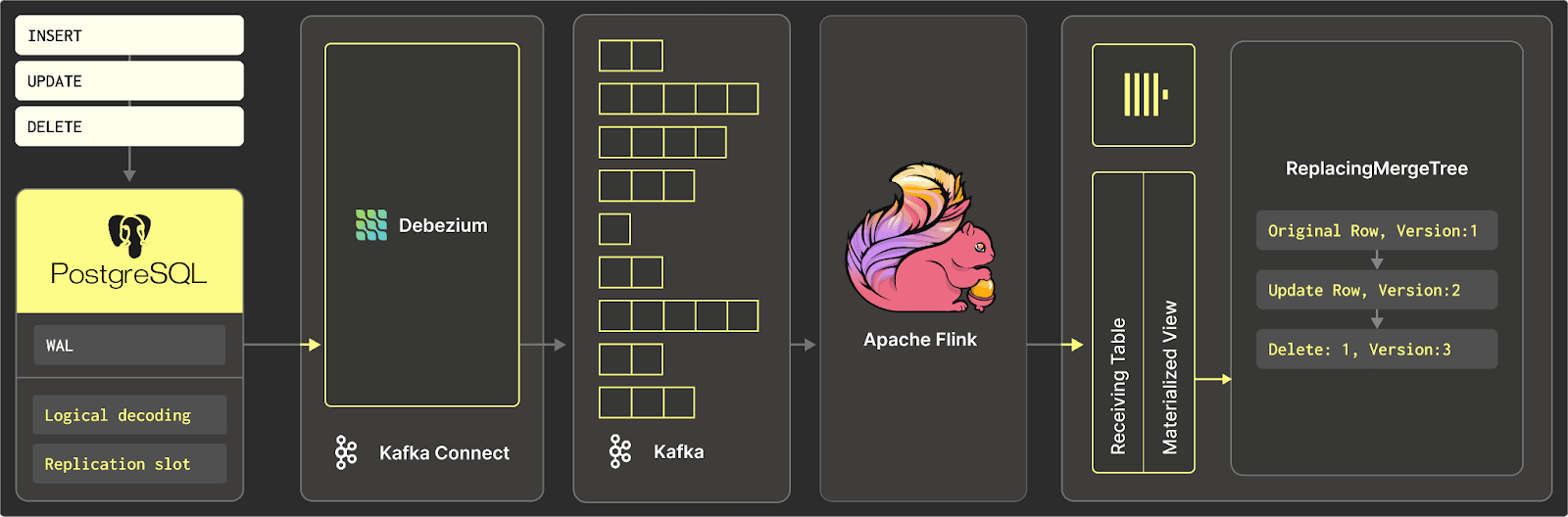
Challenges
When we first looked to stream CDC data to ClickHouse, we went looking for existing connectors we could use. After reviewing the official ClickHouse Kafka Connect connector, as well as others on the market, we soon realized that we would need to modify them extensively to support varying use cases. Realizing these connectors would need extensive modifications, we set about building our own solution. Below are some key requirements we needed to ensure were addressed before we could bring our solution to production.
Data typing
Data types were not well supported by existing solutions:
- Nested Struct
- Nested Array, arrays containing nested Struct
- Timestamp with microsecond precision
- Time with microsecond precision
- Date without time information (days since epoch)
- JSON transported as plain string fields
Metadata
When dealing with CDC data, it’s helpful to add additional metadata columns such as timestamps and type of CDC record. This allows for simpler and more powerful post-ingestion transformations as well as diagnosing any issues in latency.
Insert/upserts
At Streamkap we see an equal split of customers wishing to use inserts or upserts. Inserts being append-only mode and therefore maintaining a history of all changes, while upserts result in only the final data being visible (inserts + updates). While most companies are used to this ability with batch ETL, it is a new concept when combined with streaming ETL. Learn more at Batch vs Real-Time Processing
Schema evolution
When a source table is changed, we need the destination table to be updated to handle this schema drift and not result in a broken pipeline.
Semi-structured data
Sources like MongoDB/Elasticsearch allow inconsistencies within complex nested record structures which need to be reconciled by the ingest pipeline prior to insertion into ClickHouse. For example:
- Date/Time represented as a number (sec/ms since epoch) in some records and as a string (ISO format) in other records
- Nested fields that are strings in some records and a more complex nested struct in other records
- Deeply nested complex semi-structured data usually needs preprocessing before insertion into ClickHouse, with mapping to the appropriate types e.g. Tuples, Nested.
Our approach
Now let’s dig into our connector and how we addressed each of these challenges.
Data types
We found the default approach was often to just insert data into ClickHouse as JSON and then transform the data post-loading.
We’ve built-in support for the following data types:
| Kafka Connect Data Type | ClickHouse Data type |
|---|---|
| INT8 | Int8 |
| INT16 | Int16 |
| INT32 | Int32 |
| INT64 | Int64 |
| FLOAT32 | Float32 |
| FLOAT64 | Float64 |
| BOOLEAN | Bool |
| BYTES | BLOB (String) |
| STRING | String |
| org.apache.kafka.connect.data.Decimal | DECIMAL(38, 0) |
| org.apache.kafka.connect.data.Timestampio.debezium.time.ZonedTimestamp | DateTime64 |
| org.apache.kafka.connect.data.Date | Date |
| io.debezium.data.Json | String |
| STRUCT | Tuple |
| ARRAY | Array |
JSON fields are currently ingested as strings, the use of allow_experimental_object_type=1 is currently under testing.
Metadata
The connector adds additional key columns to each insert to the ClickHouse table for better analysis and modeling post-loading, as well as to support upserts.
The following metadata columns are added to each ClickHouse table:
_streamkap_ts_ms: CDC event timestamp_streamkap_deleted: if the current CDC event is a delete event_streamkap_partition: smallint representing the internal Streamkap partition number obtained by applying consistent hashing on the source records key fields_streamkap_source_ts_ms: timestamp when the change event happened in the source database_streamkap_op: CDC event operation type (c insert, u update, d delete, r snapshot, t truncate)
Inserts/Upserts
The Streamkap connector supports two modes of data ingestion into ClickHouse: Inserts (append) and Upserts.
Upsert mode is our connector's default mode and is used when ClickHouse tables are required to contain the latest version of the source data.
Insert (Append) mode
Insert mode results in every change being tracked and inserted as a new row in ClickHouse while delete events will be marked in ClickHouse as deleted using the meta value _streamkap_deleted.
This is useful with larger volumes to keep latency low as well as maintain a history of changes.
For example, Streamkap uses insert mode when collecting our metrics, as only immutable data is inserted.
We then use Materialized Views on top of the metrics table to create a number of aggregates for time series analysis upon ingestion. A suitable TTL on this table is set so that ClickHouse handles the delete operations for us while providing enough historical data to investigate any issues or if we have to rebuild the Materialized Views for some reason.
To use Insert (Append) mode, the ClickHouse engine MergeTree is used.
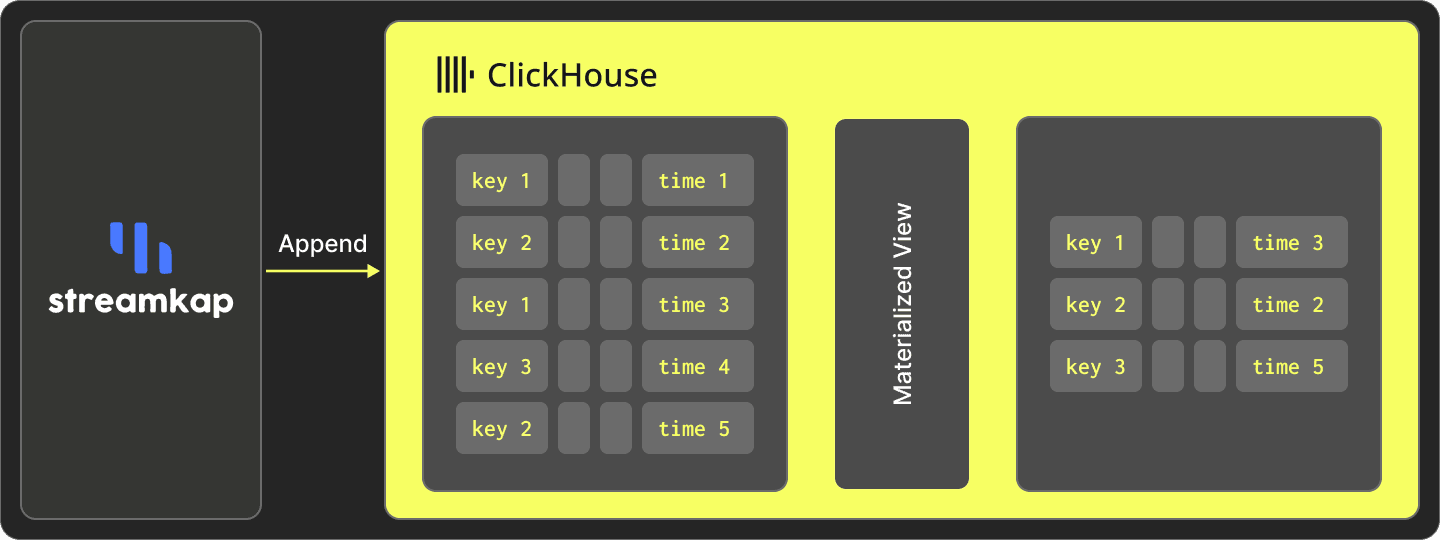
Upsert mode
Upserts are both inserts and updates combined. If there is a match on the primary key of the row, the value will be overwritten. Conversely, if there is no match, the event will be inserted.
Upsert mode is implemented using ClickHouse's ReplacingMergeTree engine.
The ReplacingMergeTree engine de-duplicates data during periodic background merges based on the ordering key, allowing old records to be cleaned up. The asynchronous nature of this process means there could be a small window where you are left with older records in the view. Queries must, therefore, use the FINAL modifier to ensure that the latest version of the data is returned, and this will then perform a deduplication of any remaining identical records at query time.
Upsert Example with basic types
An input record for an upsert is shown here in JSON format. The key has only one field, id, which is the primary key on which rows will be de-duplicated:
{
"id": "123456hYCcEM62894000000000",
"str_col": "some-str-values-000000000",
"IntColumn": 123000,
"Int8": 0,
"InT16": 10,
"bool_col": true,
"double_col": 1.7976931348623157E308,
"json_col": "{\"a\": 0}",
"__deleted": false,
"created_at": 1707379532748,
"date_col": 19761,
"ts_tz": "2023-10-24T15:19:51Z",
"_streamkap_ts_ms": 1707379532748,
"binary_col": "AQIDBAU=",
"byte_buf": "AQIDBAU=",
"bigint_col": "E4f/////0tCeAA=="
}
The resulting table:
SHOW CREATE TABLE streamkap_test_nominal_upsert
FORMAT Vertical
Query id: 1abf2898-69b3-4785-a849-65c3879493bb
Row 1:
──────
statement: CREATE TABLE streamkap.streamkap_test_nominal_upsert
(
`id` String COMMENT 'id',
`str_col` String COMMENT 'str_col',
`IntColumn` Int32 COMMENT 'IntColumn',
`Int8` Int8 COMMENT 'Int8',
`InT16` Int16 COMMENT 'InT16',
`bool_col` Bool COMMENT 'bool_col',
`double_col` Float64 COMMENT 'double_col',
`json_col` String COMMENT 'json_col',
`__deleted` Bool COMMENT '__deleted',
`created_at` DateTime64(3) COMMENT 'created_at',
`date_col` Date COMMENT 'date_col',
`ts_tz` DateTime64(3) COMMENT 'ts_tz',
`_streamkap_ts_ms` Int64 COMMENT '_streamkap_ts_ms',
`binary_col` String COMMENT 'binary_col',
`byte_buf` String COMMENT 'byte_buf',
`bigint_col` Decimal(38, 0) COMMENT 'bigint_col',
`_streamkap_partition` Int32 COMMENT '_streamkap_partition',
`_streamkap_deleted` UInt8 MATERIALIZED if(__deleted = true, 1, 0)
)
ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/{uuid}/{shard}', '{replica}', _streamkap_ts_ms, _streamkap_deleted)
PARTITION BY _streamkap_partition
PRIMARY KEY id
ORDER BY id
SETTINGS index_granularity = 8192
Example data:
SELECT *
FROM streamkap_test_nominal_upsert
FORMAT Vertical
Row 1:
──────
id: 123456hYCcEM62894000000000
str_col: some-str-values-000000000
IntColumn: 123000
Int8: 0
InT16: 10
bool_col: true
double_col: 1.7976931348623157e308
json_col: {"a": 0}
__deleted: false
created_at: 2024-02-08 08:03:37.368
date_col: 2024-02-08
ts_tz: 2023-10-24 15:19:51.000
_streamkap_ts_ms: 1707379417368
binary_col:
byte_buf:
bigint_col: 92233720368547000000000
_streamkap_partition: 0
Row 2:
──────
id: 123456hYCcEM62894000000000
str_col: some-str-values-000000000
IntColumn: 123000
Int8: 0
InT16: 10
bool_col: true
double_col: 1.7976931348623157e308
json_col: {"a": 0}
__deleted: false
created_at: 2024-02-08 08:03:41.608
date_col: 2024-02-08
ts_tz: 2023-10-24 15:19:51.000
_streamkap_ts_ms: 1707379421608
binary_col: java.nio.HeapByteBuffer[pos=0 lim=5 cap=5]
byte_buf: java.nio.HeapByteBuffer[pos=0 lim=5 cap=5]
bigint_col: 92233720368547000000000
_streamkap_partition: 0
De-duplicated data, using FINAL:
SELECT *
FROM streamkap_test_nominal_upsert
FINAL
FORMAT Vertical
Row 1:
──────
id: 123456hYCcEM62894000000000
str_col: some-str-values-000000000
IntColumn: 123000
Int8: 0
InT16: 10
bool_col: true
double_col: 1.7976931348623157e308
json_col: {"a": 0}
__deleted: false
created_at: 2024-02-08 08:03:41.608
date_col: 2024-02-08
ts_tz: 2023-10-24 15:19:51.000
_streamkap_ts_ms: 1707379421608
binary_col: java.nio.HeapByteBuffer[pos=0 lim=5 cap=5]
byte_buf: java.nio.HeapByteBuffer[pos=0 lim=5 cap=5]
bigint_col: 92233720368547000000000
_streamkap_partition: 0
Handling semi-structured data
Nested arrays & structs
Below, we provide some examples of how complex structures are mapped to ClickHouse types automatically.
For supporting Arrays containing structs, we need to alter Streamkap’s role in ClickHouse to set flatten_nested to 0:
ALTER ROLE STREAMKAP_ROLE SETTINGS flatten_nested = 0;
Nested struct field containing sub array
An input record is shown here in JSON format, where the key has only one field id:
{
"id": 1,
"obj": {
"nb": 123,
"str": "abc",
"sub_arr": [
{
"sub_nb": 789,
"sub_str": "mnp"
}
]
}
}
The resulting table. Not how the obj column has been mapped to an Tuple(nb Int32, str String, sub_arr Array(Tuple(n Int32, s String)), sub_arr_str Array(String)) to handle the complex structure:
SHOW CREATE TABLE chdb.streamkap_nested_struct_with_array
CREATE TABLE chdb.streamkap_nested_struct_with_array
(
`obj` Tuple(nb Int32, str String, sub_arr Array(Tuple(n Int32, s String)), sub_arr_str Array(String)) COMMENT 'obj',
`__deleted` Bool COMMENT '__deleted',
`_streamkap_ts_ms` Int64 COMMENT '_streamkap_ts_ms',
`_streamkap_partition` Int32 COMMENT '_streamkap_partition',
`id` Int32 COMMENT 'id',
`_streamkap_deleted` UInt8 MATERIALIZED if(__deleted = true, 1, 0)
)
ENGINE = ReplacingMergeTree(_streamkap_ts_ms, _streamkap_deleted)
PARTITION BY _streamkap_partition
PRIMARY KEY id
ORDER BY id
SETTINGS index_granularity = 8192
Example data:
SELECT *
FROM chdb.streamkap_nested_struct_with_array
LIMIT 1 format Vertical
obj: (123,'abc',[(789,'mnp')],['efg'])
__deleted: false
_streamkap_ts_ms: 1702519029407
_streamkap_partition: 0
id: 1
Nested array field containing sub struct
An input record is shown here as JSON format, where key has only one field id:
{
"id": 1,
"arr": [
{
"nb": 123,
"str": "abc"
}
]
}
SHOW CREATE TABLE streamkap_nested_array_of_struct
CREATE TABLE streamkap.streamkap_nested_array_of_struct
(
`arr` Array(Tuple(nb Int32, str String)) COMMENT 'arr',
`__deleted` Bool COMMENT '__deleted',
`_streamkap_ts_ms` Int64 COMMENT '_streamkap_ts_ms',
`_streamkap_partition` Int32 COMMENT '_streamkap_partition',
`id` Int32 COMMENT 'id',
`_streamkap_deleted` UInt8 MATERIALIZED if(__deleted = true, 1, 0)
)
ENGINE = ReplacingMergeTree( _streamkap_ts_ms, _streamkap_deleted)
PARTITION BY _streamkap_partition
PRIMARY KEY id
ORDER BY id
SETTINGS index_granularity = 8192
Example data:
SELECT *
FROM streamkap_nested_array_of_struct
LIMIT 1 format Vertical
arr: [(123,'abc')]
__deleted: false
_streamkap_ts_ms: 1702529856885
_streamkap_partition: 0
id: 1
Snapshotting
Snapshotting refers to the process of loading existing data from the database into ClickHouse.
We have two methods in which we can load this historical data.
Blocking Snapshot
A blocking snapshot serves the purpose of capturing the entire current state of the database tables and will use large select statements to do so. These can also be run concurrently and are very fast. Efficiency-wise, a blocking snapshot may have a higher impact on system resources, especially for large tables, and can take longer per query.
Incremental Snapshot
Incremental snapshots aim for efficiency with a generally lower impact on system resources and are particularly well suited for very large tables or when wishing to snapshot and stream at the same time.
Data Consistency & Delivery Guarantees
Delivery guarantees mainly refer to failure scenarios where unconfirmed CDC events could be replayed, resulting in duplicated rows inserted into ClickHouse.
Streamkap offers at-least-once delivery guarantee for ClickHouse.
With insert ingestion mode, it’s possible that some duplicate rows can be inserted into ClickHouse. However, by adding in dedupe code into your materialized view, there will not be any impact.
As mentioned earlier, for the upsert ingestion mode, we carry out deduplication with the source record key. Enforcing exactly-once delivery guarantees adds a performance penalty without any additional benefit since the same process handles duplicated CDC events, merging all CDC events for one record into the final record state.
Transforms
Streamkap supports transformations in the pipeline so that data can be sent to ClickHouse pre-processed.
This is especially useful for semi-structured data, pre-processing, and cleanup tasks. This can be significantly more efficient than working on the data post-ingestion.
Real-time analytics on cleaned-up structured data is naturally done in ClickHouse, with the query performance benefiting from moving data transformation to insert time.
Below, we present some common transformations performed by Streamkap.
Fix inconsistencies in semi-structured data
Consider the fixing of an inconsistent semi-structured date field:
"someDateField": {"$date": "2023-08-04T09:12:20.29Z"}
"someDateField": "2023-08-07T08:14:57.817325+00:00"
"someDateField": {"$date": {"$numberLong": 1702853448000}}
Using Streamkap transforms, all records can be converted to a common format for ingestion into Clickhouse DateTime64 column:
"someDateField": "yyyy-MM-dd HH:mm:ss.SSS"
Split large semi-structured JSON documents
With document databases, child entities can be modelled as sub-arrays nested inside the parent entity document:
{
"key": "abc1234",
"array": [
{
"id": "11111",
"someField": "aa-11"
},
{
"id": "22222",
"someField": "bb-22"
}
]
}
In ClickHouse it can make sense to represent these child entities as separate rows. Using Streamkap transforms, the child entity records can be split into individual records:
{
"id": "11111",
"parentKey": "abc1234",
"someField": "aa-11"
}
{
"id": "22222",
"parentKey": "abc1234",
"someField": "bb-22"
}
Schema evolution
Schema evolution or drift handling is the process of making changes to the destination tables to reflect upstream changes.
The Streamkap connector automatically handles schema drift in the following scenarios.
- Additional Columns: An additional field will be detected, and a new column in the table will be created to receive the new data.
- Removal of Columns: This column will now be ignored, and no further action will be taken.
- Changing Column Type: An additional column is created in the table using a suffix to represent the new type. e.g.
ColumnName_type
Additional tables can be added to the pipeline at any stage. We show some examples of this schema evolution below.
Add Column
Consider the following input record before schema evolution:
{
"id": "123456hYCcEM62894000000000",
"str_col": "some-str-values-000000000",
"IntColumn": 123000,
"Int8": 0,
"InT16": 10,
"bool_col": true,
"double_col": 1.7976931348623157E308,
"json_col": "{\"a\": 0}",
"binary_col": "AQIDBAU=",
"byte_buf": "AQIDBAU=",
"bigint_col": "E4f/////0tCeAA==",
"__deleted": false,
"created_at": 1702894985613,
"ts_tz": "2023-10-24T15:19:51Z",
"_streamkap_ts_ms": 1702894985613
}
A new column new_double_col is added to the upstream schema. This causes the ClickHouse schema to evolve:
{
"id": "123456hYCcEM62894xxx",
"str_col": "some-str-values-000000000",
"IntColumn": 123000,
"Int8": 0,
"InT16": 10,
"bool_col": true,
"double_col": 1.7976931348623157E308,
"json_col": "{\"a\": 0}",
"binary_col": "AQIDBAU=",
"byte_buf": "AQIDBAU=",
"bigint_col": "E4f/////0tCeAA==",
"__deleted": false,
"created_at": 1702894985613,
"ts_tz": "2023-10-24T15:19:51Z",
"_streamkap_ts_ms": 1702894985613,
"new_double_col": 1.7976931348623157E308
}
ClickHouse data:
SELECT
id,
new_double_col
FROM streamkap_test_nominal_add_new_column
ORDER BY _streamkap_ts_ms ASC
┌─id─────────────────────────┬─new_double_col─┐
│ 123456hYCcEM62894000000000 │ 0 │
└────────────────────────────┴────────────────┘
┌─id───────────────────┬─────────new_double_col─┐
│ 123456hYCcEM62894xxx │ 1.7976931348623157e308 │
└──────────────────────┴────────────────────────┘
Evolve Int to String
An input record before schema evolution:
{
"id": "123456hYCcEM62894000000000",
. . .
"IntColumn": 123000,
. . .
"_streamkap_ts_ms": 1702894492041
}
A new record ingested after the schema has evolved upstream:
{
"id": "123456hYCcEM62894xxx",
. . .
"IntColumn": "new-str-value",
. . .
}
ClickHouse data, after the new column IntColumn_str has been added:
SELECT
id,
IntColumn,
IntColumn_str
FROM streamkap_test_nominal_evolve_int2string
ORDER BY _streamkap_ts_ms ASC
┌─id─────────────────────────┬─IntColumn─┬─IntColumn_str─┐
│ 123456hYCcEM62894000000000 │ 123000 │ │
└────────────────────────────┴───────────┴───────────────┘
┌─id───────────────────┬─IntColumn─┬─IntColumn_str─┐
│ 123456hYCcEM62894xxx │ 0 │ new-str-value │
└──────────────────────┴───────────┴───────────────┘
Performance
The following 15-minute load tests aim to show the performance characteristics of various bulk sizes in relation to latency. Also, we’ll evaluate the scalability of the Streamkap ClickHouse destination connector.
ClickHouse Cloud instance details: 3 nodes each of 32GiB with 8 vCPUs
Input record format contains basic types, a medium string ~100 characters and a large string of ~1000 characters:
select * from streamkap_test_nominal_perf limit 1 format Vertical;
id: 123456hYCcEM62894000000001
str_col: some-str-values-000000001
IntColumn: 123001
Int8: 1
InT16: 10
bool_col: true
double_col: 1.7976931348623157e308
json_col: {"a": 1}
__deleted: false
created_at: 1970-01-01 00:00:19.751
ts_tz: 2023-10-24 15:19:51.000
_streamkap_ts_ms: 1706539233685
binary_col: java.nio.HeapByteBuffer[pos=0 lim=5 cap=5]
byte_buf: java.nio.HeapByteBuffer[pos=0 lim=5 cap=5]
bigint_col: 92233720368547000000001
medium_str: str-medium-000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001
large_str: str-large-000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001x000000001
_streamkap_partition: 0
Ingestion mode is set to "upsert" for the current tests. When using "append" the throughput will be slightly better since some in-memory de-duplication logic is not needed.
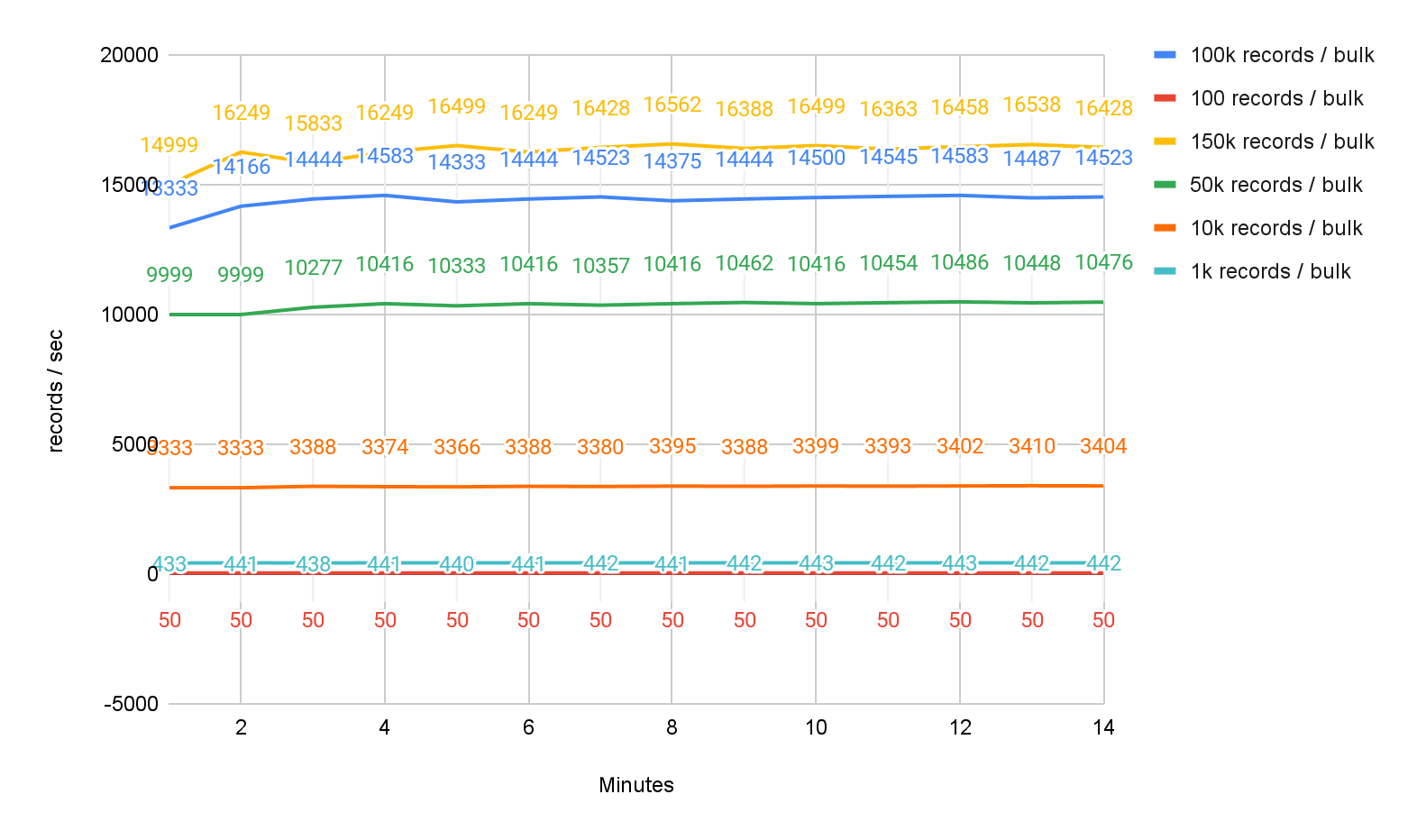
Baseline single partition
Baselining with a single Streamkap task and Clickhouse partition with multiple bulk sizes.
Throughput:
Latency per bulk size:
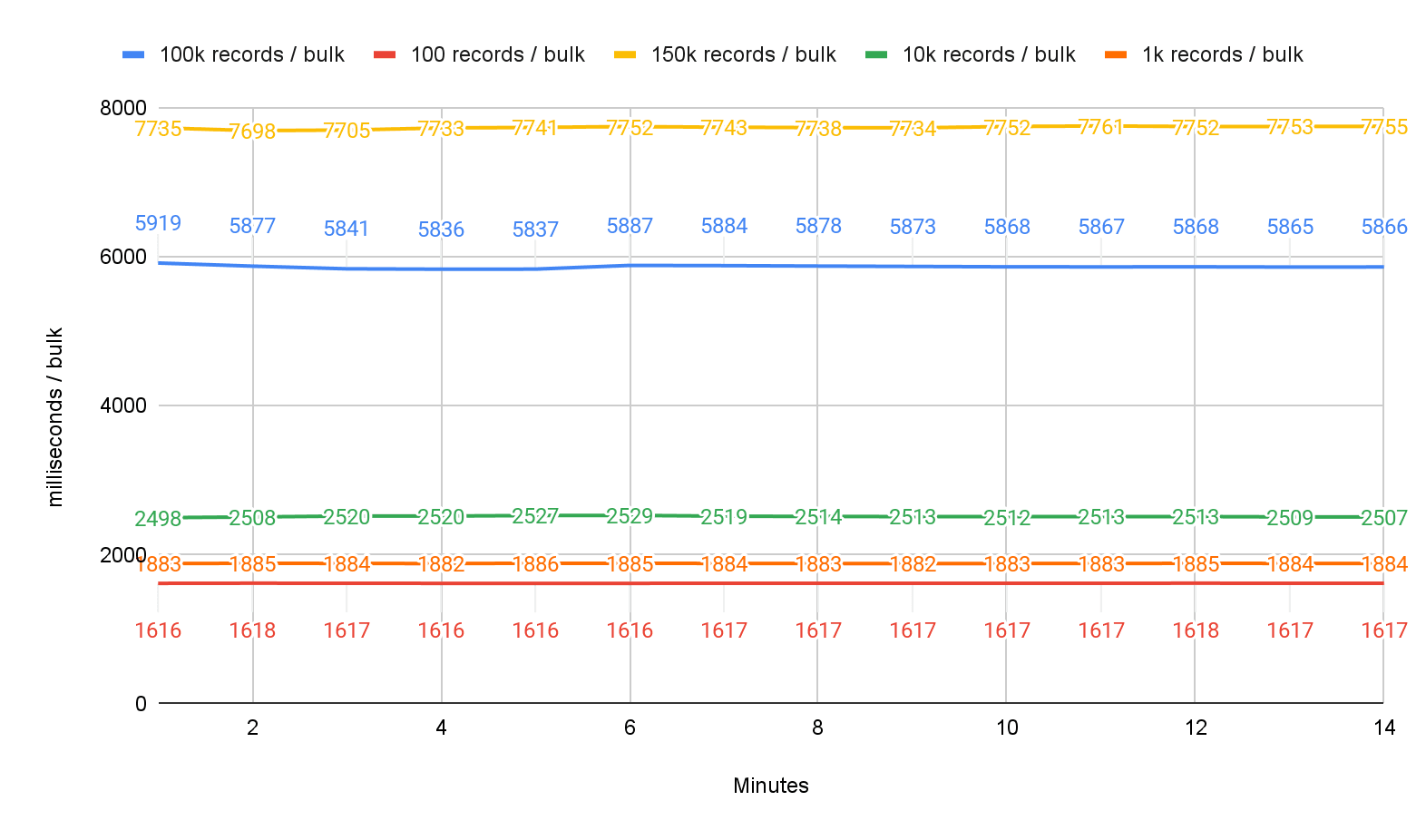
Generally, raw throughput is required for backfill, and latency is not a concern. In this case, larger bulk sizes of over 100k rows will be more appropriate.
Usually, throughput requirements are lower for streaming changes, and a smaller latency might be desired. In this case, smaller bulk sizes are more appropriate.
These are artificial tests with fixed bulk sizes to exemplify the tradeoff between throughput and latency. In practice, the bulk size varies with the internal queue size. If many records are waiting in the queue, the bulk size will grow, and thus, throughput will grow.
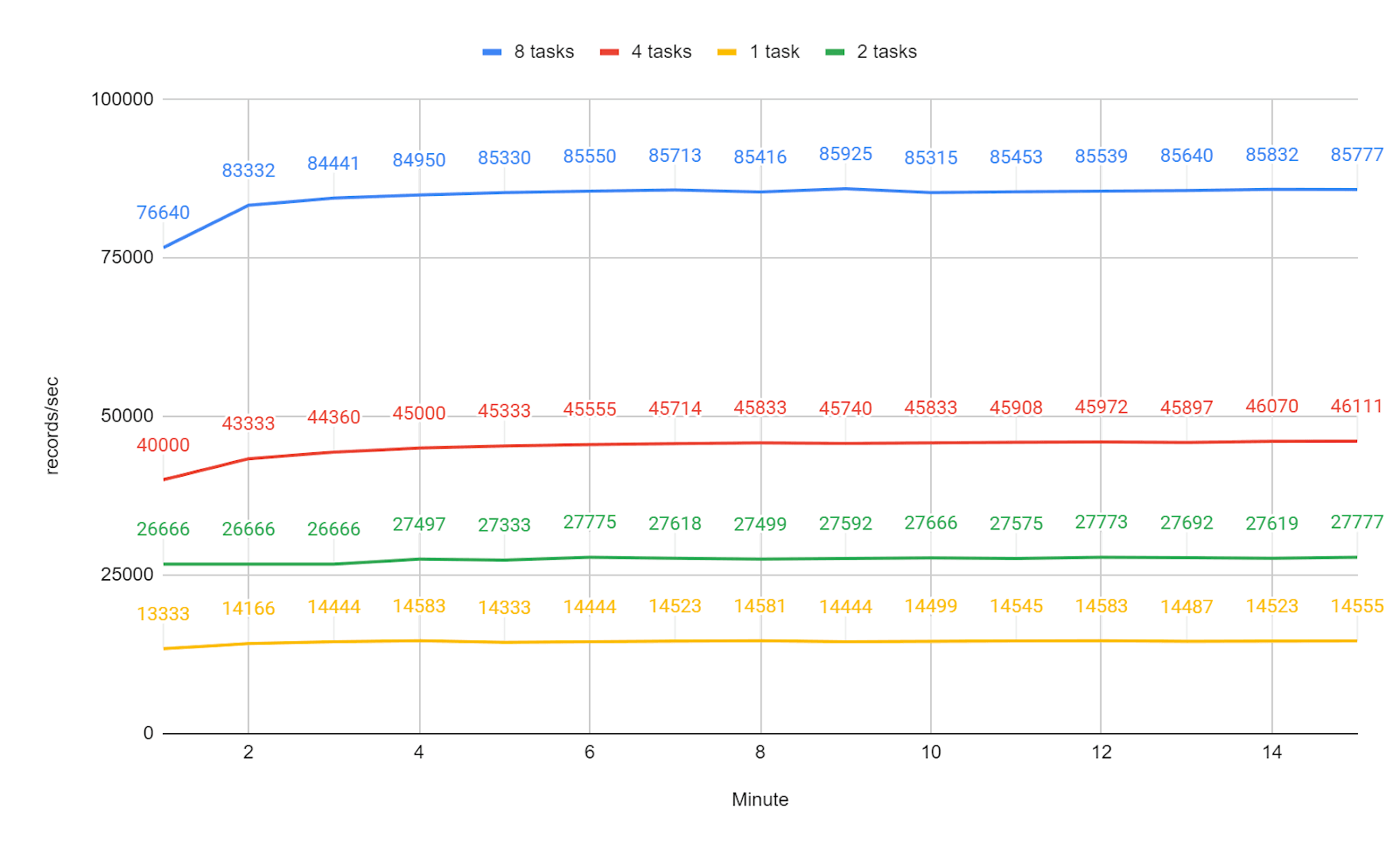
Scalability
Testing with the same bulk size: 100,000 records per bulk size, and increasing gradually the number of tasks: 1, 2, 4, and 8. We can see that the throughput scales roughly linearly with the number of tasks.
Summary
This is just the start of our partnership with ClickHouse, and in the coming weeks, we will continue to build the very best integration possible for handling Change Data Capture events and beyond.
Here are some areas we would like feedback on whether the community would vote for these
- The use of allow_experimental_object_type=1
- Auto-created Materialized views, template-based
- Streaming ACID transactions across multiple tables
- Single Record Transformations
- Multi Record Transformations (splits, joins, aggregations)
- Exactly-once
Hopefully, this connector will enable you to enjoy the benefits of ClickHouse more easily, as we do.
Streamkap & ClickHouse both offer free trials; you can sign up at Streamkap.com and ClickHouse.com.


