Table of Contents
- Introduction
- Synchronous data inserts primer
- Data needs to be batched for optimal performance
- Sometimes client-side batching is not feasible
- Example application and benchmark setup
- Synchronous inserts benchmark
- Asynchronous inserts
- Configuring the return behavior
- Default return behavior
- Fire-and-forget return behavior
- Summary
Introduction
ClickHouse is designed to be fast not just for queries but also for inserts. ClickHouse tables are intended to receive millions of row inserts per second and store substantial (100s of Petabytes) volumes of data. A very high ingest throughput traditionally requires appropriate client-side data batching.
In this post, we will describe the motivation and mechanics behind an alternative way of ingesting data with high throughput: ClickHouse asynchronous data inserts shift the batching of data from the client side to the server side and support use cases where client-side batching is not feasible. We will look under the hood of asynchronous inserts and use an example application simulating realistic scenarios to demonstrate, benchmark, and tune traditional synchronous and asynchronous inserts with different settings.
Synchronous data inserts primer
With traditional inserts into tables of the merge tree engine family, data is speedily written to the database storage in the form of a new data part synchronously to the reception of the insert query. The following diagram illustrates this:
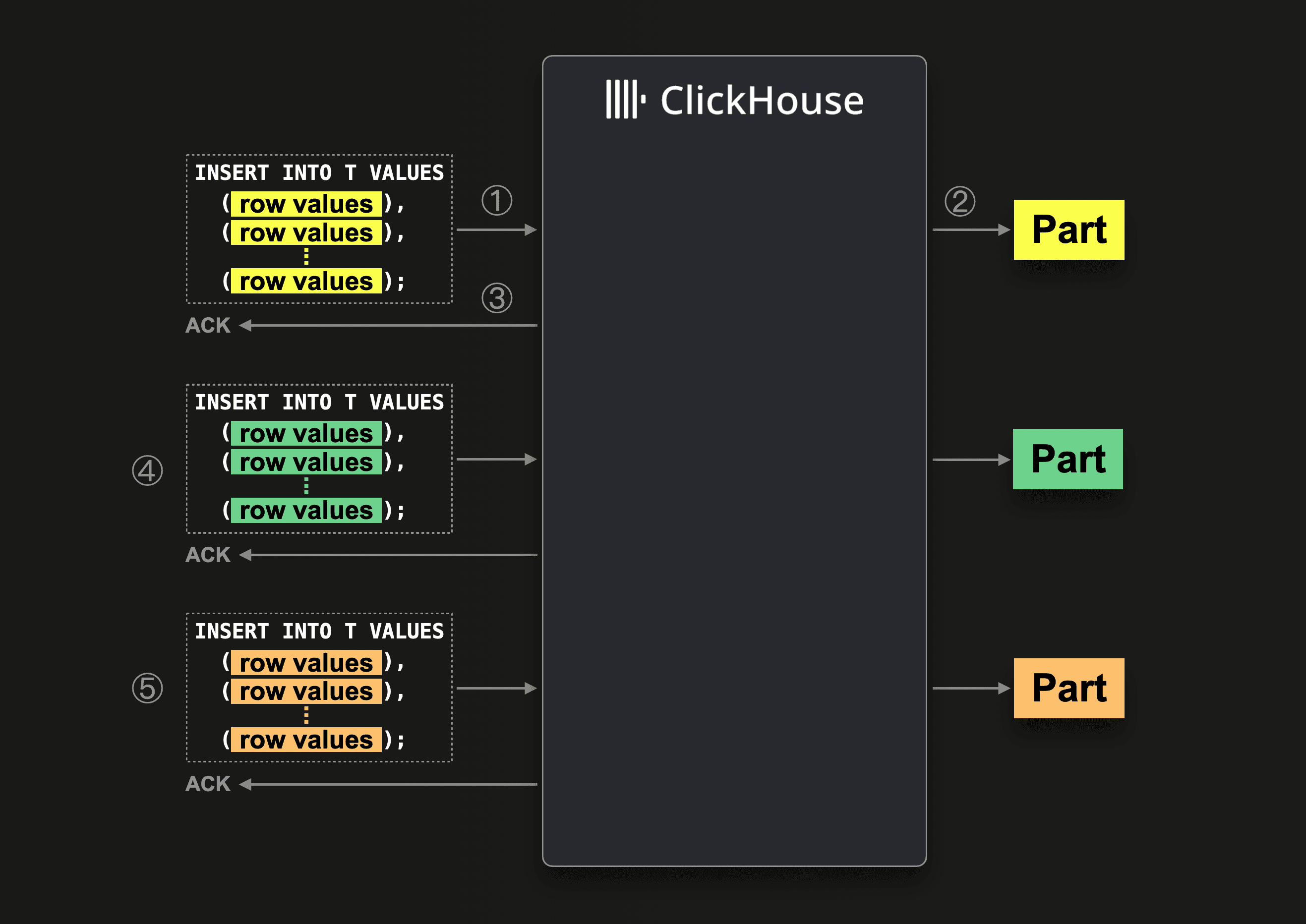 When ClickHouse ① receives an insert query, then the query’s data is ② immediately (synchronously) written in the form of (at least) one new data part (per partitioning key) to the database storage, and after that, ③ ClickHouse acknowledges the successful execution of the insert query
When ClickHouse ① receives an insert query, then the query’s data is ② immediately (synchronously) written in the form of (at least) one new data part (per partitioning key) to the database storage, and after that, ③ ClickHouse acknowledges the successful execution of the insert query
In parallel (and in any order) ClickHouse can receive and execute other insert queries (see ④ and ⑤ in the diagram above).
Data needs to be batched for optimal performance
In the background, for incrementally optimizing the data for reads, ClickHouse is continuously merging data parts into larger parts. The merged parts are marked as inactive and finally deleted after a configurable number of minutes. Creating and merging data parts requires cluster resources. Files are created and handled for each part, and in wide format each table column is stored in a separate file. In a replicated setup, ClickHouse Keeper entries are created for each data part. Furthermore, data is sorted and compressed when a new part is written. When parts are merged, the data needs to be decompressed and merge-sorted. Also, table engine specific optimizations are applied before the merged data is compressed and written to storage again.
Users should avoid creating too many small inserts and too many small initial parts, respectively. As this creates (1) overhead on the creation of files, (2) increasing write amplification (leading to higher CPU and I/O usage), and (3) overhead on ClickHouse Keeper requests. These leads to degradation of ingestion performance in case of frequent small inserts due to high CPU and I/O usage overhead. Leaving fewer resources available for other operations like queries.
ClickHouse actually has a built-in safeguard to protect itself from spending too many resources for creating and merging parts: It will return a Too many parts error to an insert query for a table T when there are more than 300 active parts within a single partition of T. To prevent that from happening, we recommend sending fewer but larger inserts instead of many small inserts by buffering data client-side and inserting data as batches. Ideally, with at least 1000 rows, or more. By default, a single new part can contain up to ~1 million rows. And, if a single insert query contains more than 1 million rows, ClickHouse will create more than one new part for the query’s data.
Generally, ClickHouse is capable of providing a very high ingest throughput with traditional synchronous inserts. Users choose ClickHouse especially because of this capability. Uber is using ClickHouse for ingesting millions of logs per second, Cloudflare stores 11 million rows per second in ClickHouse, and Zomato ingests up to 50 TB of log data per day.
Using ClickHouse is like driving a high-performance Formula One car 🏎. A copious amount of raw horsepower is available, and you can reach top speed. But, to achieve maximum performance, you need to shift up into a high enough gear at the right time and batch data appropriately, respectively.
Sometimes client-side batching is not feasible
There are scenarios where client-side batching is not feasible. Imagine an observability use case with 100s or 1000s of single-purpose agents sending logs, metrics, traces, etc., where real-time transport of that data is key to detect issues and anomalies as quickly as possible. Furthermore, there is the risk of event spikes in observed systems, potentially causing large memory spikes and related issues when trying to buffer observability data client-side.
Example application and benchmark setup
To demonstrate and benchmark a scenario where client-side batching is not feasible, we implemented a simple example application coined UpClick for monitoring the global latency of clickhouse.com (or any other website). The following diagram sketches the architecture of UpClick:
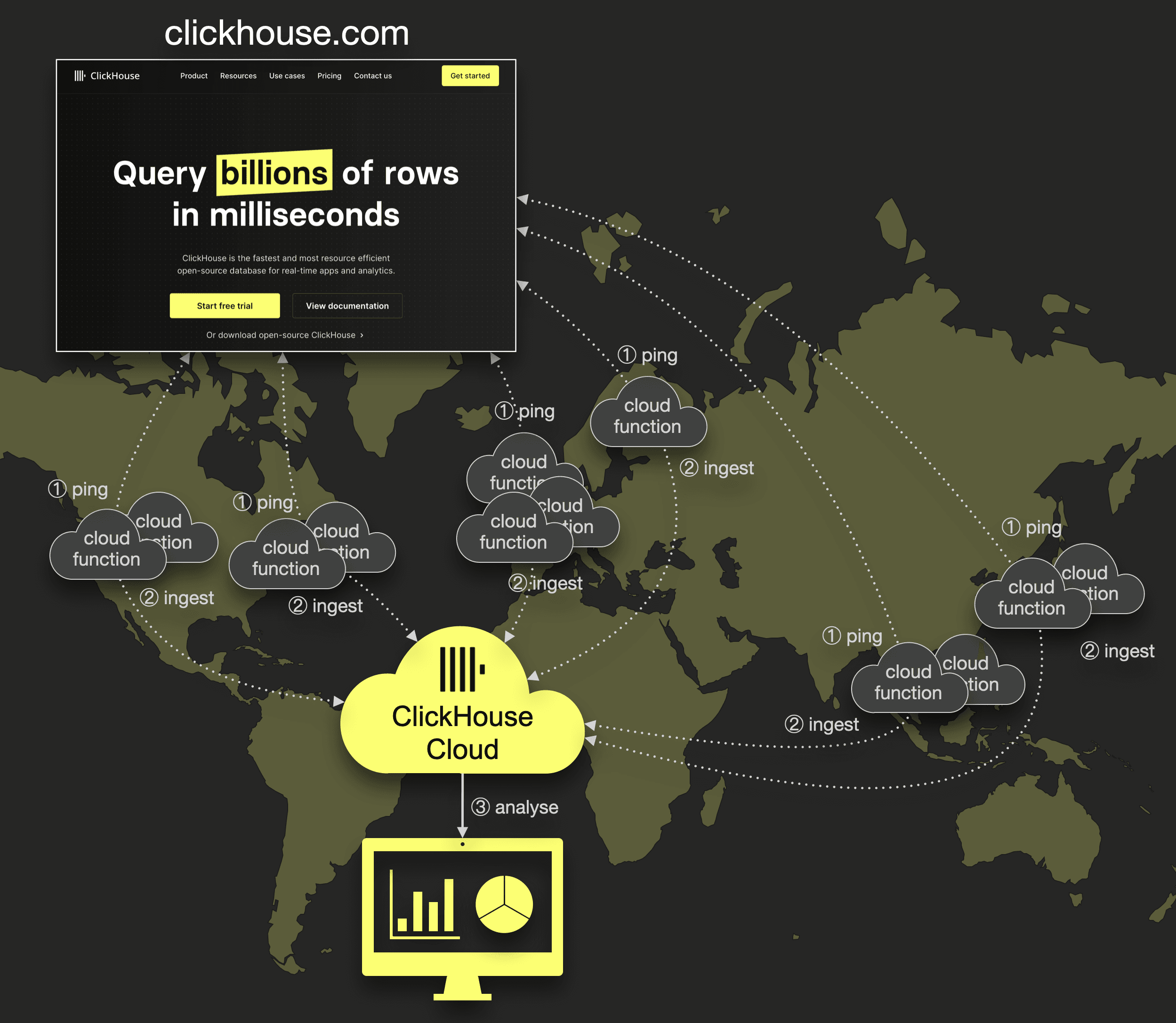 We are using a straightforward serverless Google cloud function that gets scheduled and executed every
We are using a straightforward serverless Google cloud function that gets scheduled and executed every n seconds (n is configurable) and then does the following:
① Ping clickhouse.com (the URL is configurable, and the function could be easily adapted to support an array of URLs)
② Via HTTP interface ingest the result from ① together with the cloud function’s geo location into a target table within a ClickHouse Cloud service
We are using a ClickHouse Cloud service with a service size of 24 GiB of main memory and 6 CPU cores for benchmarks. This service consists of 3 compute nodes with 8 GiB of main memory and 2 CPU cores.
Additionally, we ③ implemented a real-time Grafana dashboard that updates itself each n seconds and displays on a geo map the average latency for the last m seconds for all locations in Europe, North America, and Asia, where a cloud function is deployed. The following screenshot shows the latencies in Europe:
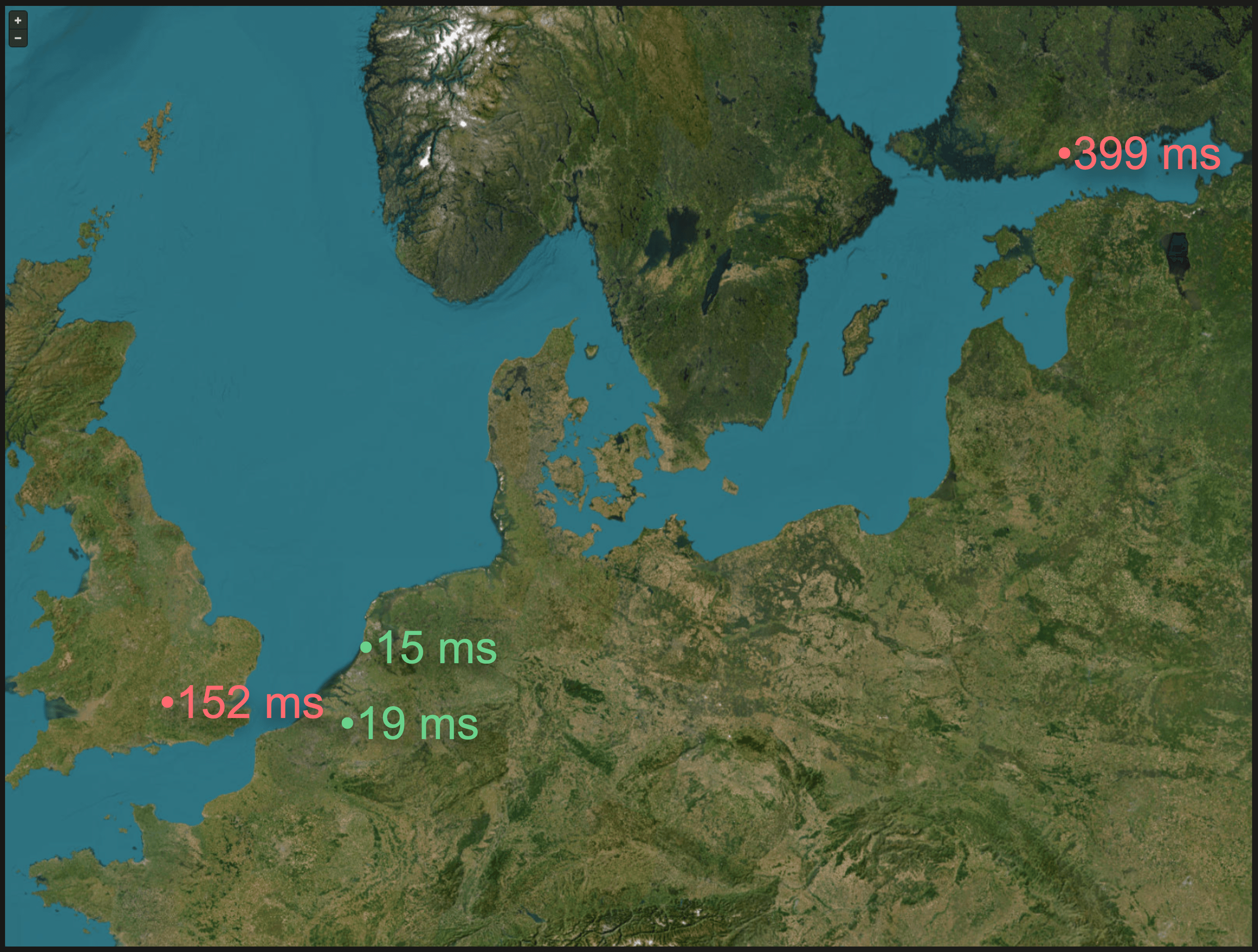 In the dashboard screenshot above, we can see by the color coding that the access latency to clickhouse.com was below the (configurable) KPI in the Netherlands and Belgium and above in London and Helsinki.
In the dashboard screenshot above, we can see by the color coding that the access latency to clickhouse.com was below the (configurable) KPI in the Netherlands and Belgium and above in London and Helsinki.
We will use the UpClick application to compare synchronous and asynchronous inserts with different settings.
In order to match realistic observability scenarios, we use a load generator that can create and drive an arbitrary amount of simulated cloud function instances. With that, we created and scheduled n instances of the cloud function for benchmark runs. Each instance is getting executed once per m seconds.
After each benchmark run, we used three SQL queries over the ClickHouse system tables to introspect (and visualize) the changes over time of the:
- number of active parts in the cloud function’s target table
- number of all parts (active + inactive) in the cloud function’s target table
- CPU utilization of the ClickHouse Cloud service
Note that some of these queries must be executed on a cluster with a specific name by utilizing the clusterAllReplicas table function.
Synchronous inserts benchmark
We run a benchmark with the following parameters:
• 200 UpClick cloud function instances
• Once every 10 seconds schedule/execution per cloud function
Effectively 200 inserts are sent to ClickHouse every 10 seconds, resulting in ClickHouse creating 200 new parts every 10 seconds. With 500 cloud function instances, ClickHouse would create 500 new parts every 10 seconds. And so on. What can possibly go wrong here?
The following three charts visualize the number of active parts, the number of all parts (active and inactive) in the cloud function’s target table, and the CPU utilization of the ClickHouse cluster during the benchmark run:
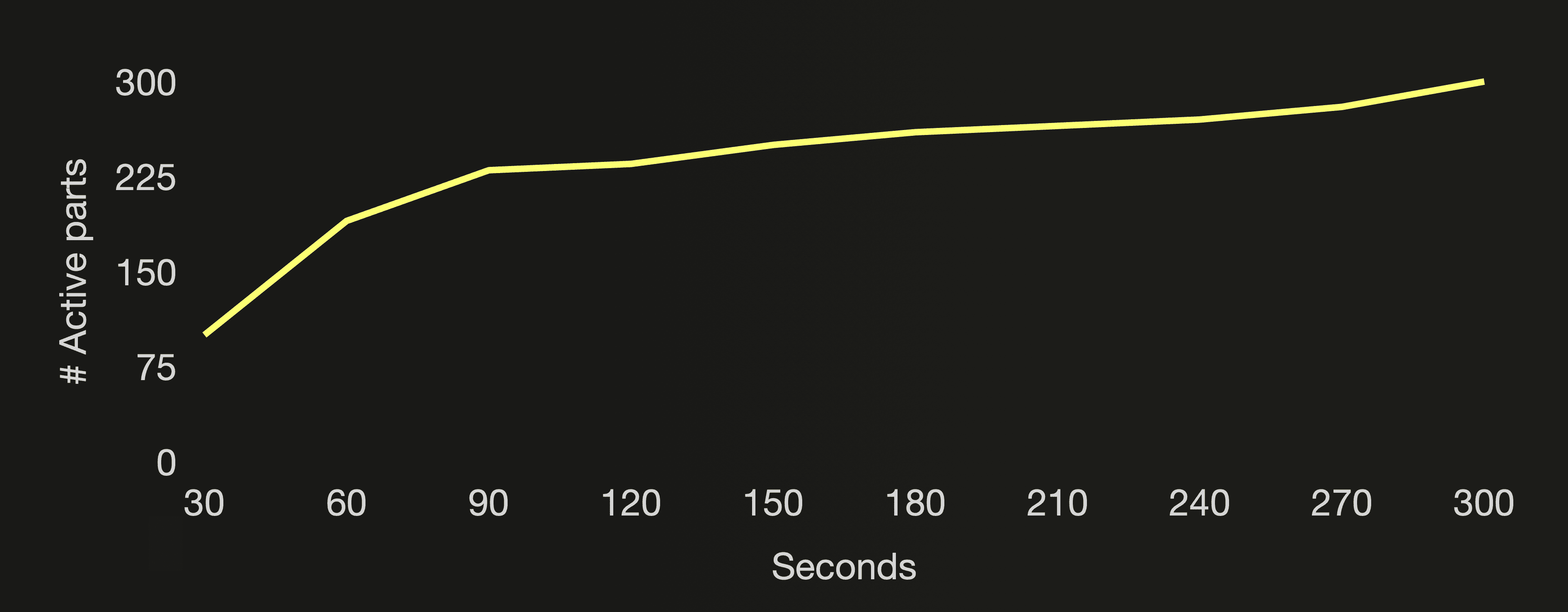
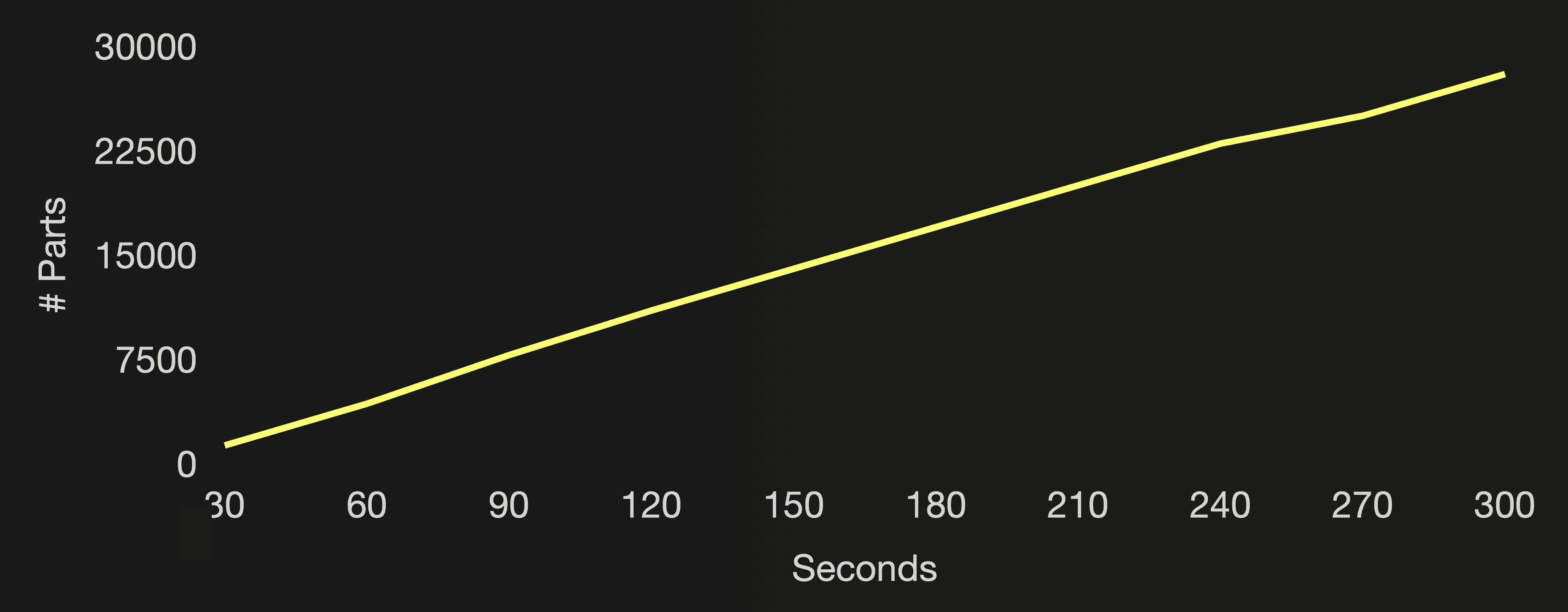
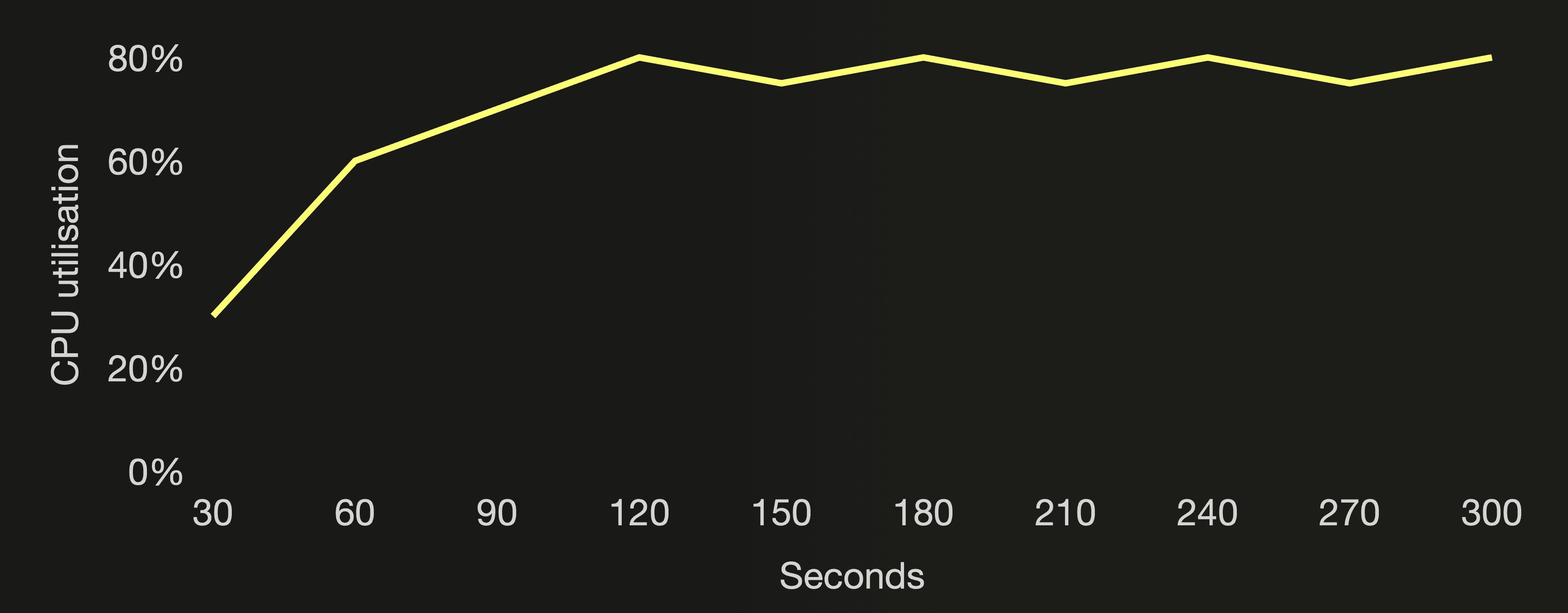
5 minutes after the start of the benchmark, the number of active parts was reaching the threshold mentioned above for the Too many parts error, and we aborted the benchmark. With ~200 new parts created per second, ClickHouse couldn’t merge the target table’s parts fast enough to stay below the 300 active parts threshold, protecting itself from spiraling into an unmanageable situation. When the Too many parts error was raised, almost 30k parts existed in total (active and inactive) for the cloud function’s table. Remember that merged parts are marked inactive and deleted after a few minutes. As mentioned above, creating and merging (too many) parts is resource intensive. We are trying to drive our Formula One car 🏎 at top speed, but in a too low gear, by sending very small inserts too frequently.
Note that client-side batching is not a feasible design pattern for our cloud function. We could have used an aggregator or gateway architecture instead to batch the data. However, that would have complicated our architecture and require additional third-party components. Luckily, ClickHouse already comes with the perfect built-in solution for our issue.
Asynchronous inserts.
Asynchronous inserts
Description
With traditional insert queries, data is inserted into a table synchronously: When the query gets received by ClickHouse, the data is immediately written to the database storage.
With asynchronous inserts, data is inserted into a buffer first and then written to the database storage later or asynchronously, respectively. The following diagram illustrates this:
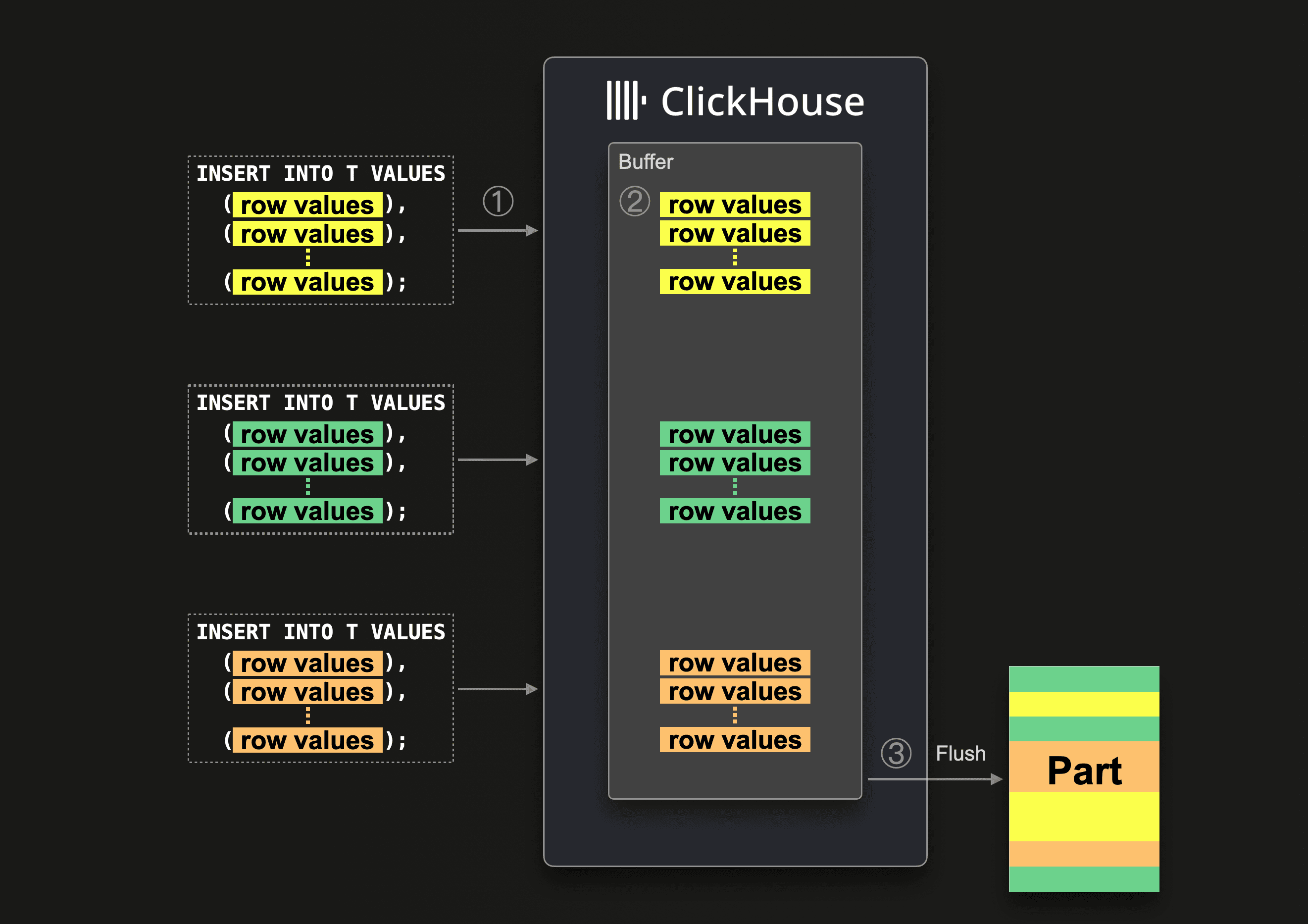 With enabled asynchronous inserts, when ClickHouse ① receives an insert query, then the query’s data is ② immediately written into an in-memory buffer first. Asynchronously to ①, only when ③ the next buffer flush takes place, the buffer’s data is sorted and written as a part to the database storage. Note, that the data is not searchable by queries before being flushed to the database storage; the buffer flush is configurable and we show some examples later.
With enabled asynchronous inserts, when ClickHouse ① receives an insert query, then the query’s data is ② immediately written into an in-memory buffer first. Asynchronously to ①, only when ③ the next buffer flush takes place, the buffer’s data is sorted and written as a part to the database storage. Note, that the data is not searchable by queries before being flushed to the database storage; the buffer flush is configurable and we show some examples later.
Before the buffer gets flushed, the data of other asynchronous insert queries from the same or other clients can be collected in the buffer. The part created from the buffer flush will potentially contain the data from several asynchronous insert queries. Generally, these mechanics shift the batching of data from the client side to the server side (ClickHouse instance). Perfect for our UpClick use case.
There can be multiple parts
The table rows buffered in the asynchronous insert buffer can potentially contain several different partitioning key values, and therefore, during buffer flush, ClickHouse will create (at least) one new part per distinct partitioning key value contained in the buffer. Also, for tables without a partitioning key, depending on the number of rows collected in the buffer, a buffer flush can result in multiple parts.
There can be multiple buffers
There will be one buffer per insert query shape (the syntax of the insert query excluding the values clause / the data) and settings. And on a multi-node cluster (like ClickHouse Cloud), the buffers will exist per node. The following diagram illustrates that:
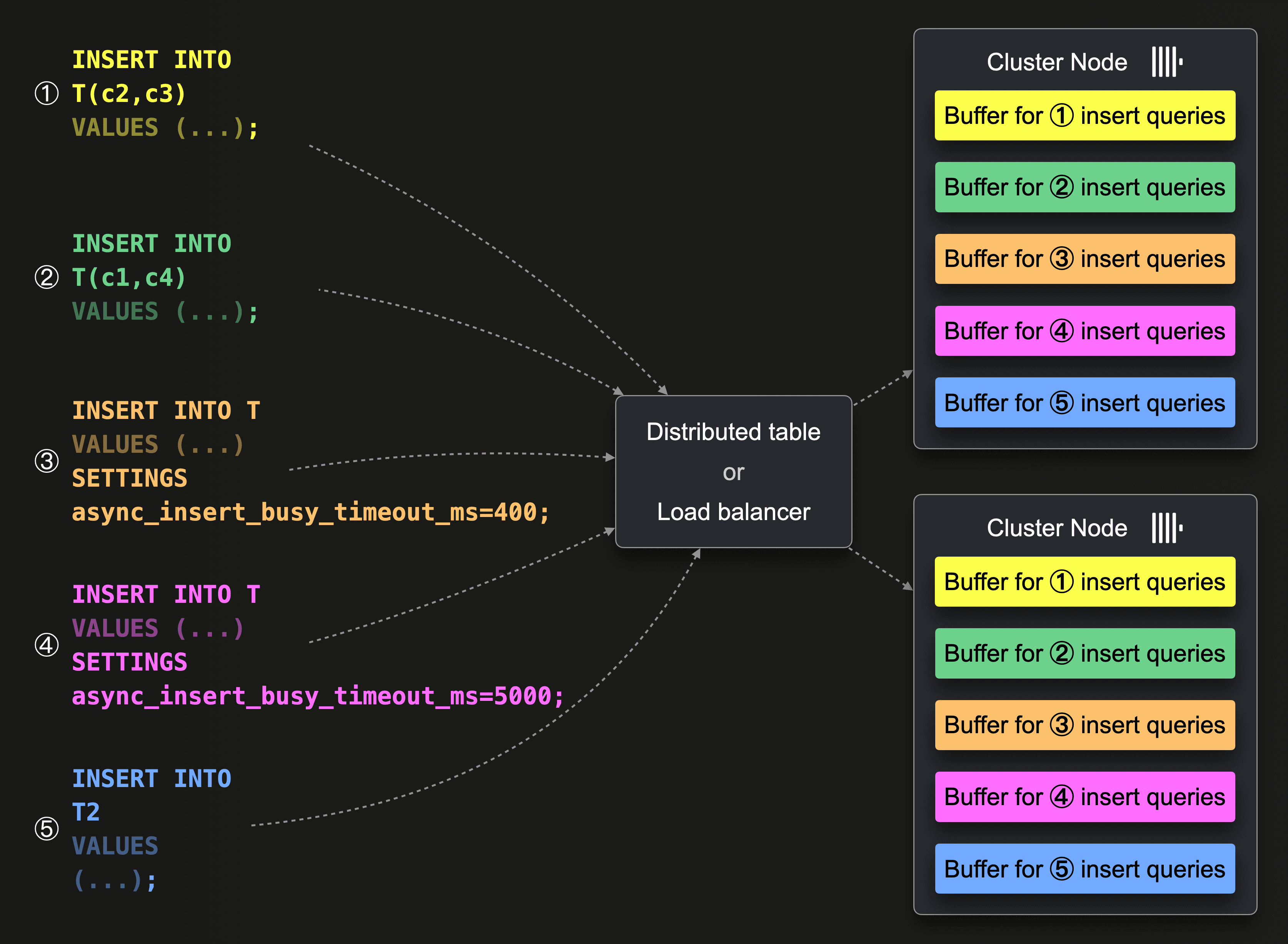 Queries ①, ②, and ③ (and ④) have the same target table T but different syntactical
Queries ①, ②, and ③ (and ④) have the same target table T but different syntactical shapes. Queries ③ and ④ have the same shape but different settings. Query ⑤ has a different shape because it is targeting table T2. Therefore there will be a separate asynchronous insert buffer for all 5 queries. And when the queries are targeting a multi-node cluster via a distributed table (Self-managed cluster) or load balancer (ClickHouse Cloud), the buffers will be per node.
The per settings buffer enables different flush times for data for the same table. In our UpClick example application, there could be important sites that should be monitored in near real-time (with a low async_insert_busy_timeout_ms setting) and less important sites whose data can be flushed with higher time granularity (with a higher async_insert_busy_timeout_ms setting) resulting in less resource usage for this data.
Inserts are idempotent
For tables of the merge tree engine family, ClickHouse will, by default, automatically deduplicate asynchronous inserts. That makes asynchronous inserts idempotent and, therefore failure tolerant in cases like the following:
-
If the node containing the buffer crashes for some reason before the buffer got flushed, the insert query will time out (or get a more specific error) and not get an acknowledgment.
-
If the data got flushed, but the acknowledgment can’t be returned to the sender of the query because of network interruptions, the sender will either get a time-out or a network error.
From the client's perspective 1. and 2. can be hard to distinguish. However, in both cases, the unacknowledged insert can just immediately be retried. As long as the retried insert query contains the same data in the same order, ClickHouse will automatically ignore the retried asynchronous insert if the (unacknowledged) original insert succeeded.
Insert errors can occur during buffer flush
Insert errors can happen when the buffer gets flushed: Also with asynchronous inserts, the Too many parts error can occur. For example, with a poorly chosen partitioning key. Or the cluster node where the buffer flush takes place has some operational issues at the moment in time when the buffer flushes. Furthermore, the data from an asynchronous insert query is only parsed and validated against the target table's schema when the buffer gets flushed. If some row values from an insert query can’t be inserted because of parsing or type errors, then none of the data from that query is flushed (the flushing of data from other queries is unaffected by this). ClickHouse will write detailed error messages for insert errors during buffer flushes into log files and system tables. We will discuss later how clients can handle such errors.
Asynchronous inserts vs. buffer tables
With the buffer table engine, ClickHouse provides a data insert mechanism similar to asynchronous inserts. Buffer tables buffer the received data in the main memory and periodically flush it to a target table. There are major differences between buffer tables and asynchronous inserts, though:
-
Buffer tables need to be explicitly created (on each node in a multi-node cluster) and connected to a target table. Asynchronous inserts can be switched on and off with a simple setting change.
-
Insert queries need to target the buffer table explicitly instead of the
realtarget table. With asynchronous inserts, that is not the case. -
Buffer Tables require DDL changes whenever the target table's DDL changes. That is not required with asynchronous inserts.
-
Data in the buffer table would be lost in a node crash, similar to asynchronous inserts in fire and forget mode. That is not the case for asynchronous inserts in default mode.
-
As described above, asynchronous inserts provide a buffer per insert query
shapeand settings even if all insert queries target the same table. Enabling granular data flush policies for different data within the same table. Buffer tables don’t have such a mechanism.
Generally, compared to buffer tables, from the client’s perspective, the buffering mechanism of asynchronous inserts is completely transparent and entirely managed by ClickHouse. Asynchronous inserts can be considered as a successor to buffer tables.
Supported interfaces and clients
Asynchronous inserts are supported by both the HTTP and the native interface, and popular clients like the Go client have either direct support for asynchronous inserts or support them indirectly when enabled on the query setting or user setting, or connection setting level.
Configuring the return behavior
You can choose when an asynchronous insert query returns to the sender of the query and when the acknowledgment of the insert takes place, respectively. Configurable via the wait_for_async_insert setting:
-
The default return behavior is that the insert query only returns to the sender after the next buffer flush occurs and the inserted data resides on disk, respectively.
-
Alternatively, by setting the setting to
0, the insert query returns immediately after the data just got inserted into the buffer. We call this thefire and forgetmode in the following.
Both modes have pretty significant pros and cons. Therefore we will discuss these two modes in more detail in the following two sections.
Default return behavior
Description
This diagram sketches the default return behavior (wait_for_async_insert = 1) for asynchronous inserts:
 When ClickHouse ① receives an insert query, then the query’s data is ② immediately written into an in-memory buffer first. When ③ the next buffer flush takes place, the buffer’s data is sorted and written as one or more data parts to the database storage. Before the buffer gets flushed, the data from other insert queries can be collected in the buffer. ④ Only after the next regular buffer flush occurred, the insert query from ① returns to the sender with an acknowledgment of the insert. Or in other words, the client-side call that is sending the insert query is blocked until the next buffer flush takes place. Therefore the sketched 3 inserts in the diagram above can't stem from the same single-threaded insert loop but from different multi-threaded parallel insert loops or different parallel clients/programs.
When ClickHouse ① receives an insert query, then the query’s data is ② immediately written into an in-memory buffer first. When ③ the next buffer flush takes place, the buffer’s data is sorted and written as one or more data parts to the database storage. Before the buffer gets flushed, the data from other insert queries can be collected in the buffer. ④ Only after the next regular buffer flush occurred, the insert query from ① returns to the sender with an acknowledgment of the insert. Or in other words, the client-side call that is sending the insert query is blocked until the next buffer flush takes place. Therefore the sketched 3 inserts in the diagram above can't stem from the same single-threaded insert loop but from different multi-threaded parallel insert loops or different parallel clients/programs.
Advantages
The advantage of this mode is the durability guarantee + easy way to identify failed batches:
-
Durability guarantee: When a client gets the acknowledgment for the insert, the data is guaranteed to be written to database storage (and is searchable by queries).
-
Insert errors are returned: When insert errors occur during buffer flush, the sender of the query gets a detailed error message returned instead of an acknowledgment. Because ClickHouse waits to return an acknowledgment for an insert until the buffer got flushed.
-
Identifying failed data sets is easy: Because, as mentioned above, insert errors are returned in a timeliness fashion, it is easy to identify the sets of data that couldn’t be inserted.
Disadvantage
Since ClickHouse release 24.2 this disadvantage is resolved by adaptive asynchronous inserts.
A con is that this mode can create back pressure in scenarios where a single client is used for ingesting data with a single-threaded insert loop:
1. Get the next batch of data
2. Send insert query with the data to ClickHouse
Now the call is blocked until the next buffer flush takes place
3. Receive acknowledgment that the insert succeeded
4. Go to 1
In such scenarios, ingest throughput can be increased by appropriately batching the data client-side and using multi-threaded parallel insert loops.
Benchmark
We run two benchmarks.
Benchmark 1:
• 200 UpClick cloud function instances
• Once every 10 seconds schedule/execution per cloud function
• 1 second buffer flush time
Benchmark 2:
• 500 UpClick cloud function instances
• Once every 10 seconds schedule/execution per cloud function
• 1 second buffer flush time
We use the following asynchronous insert settings for both benchmark runs:
① async_insert = 1
② wait_for_async_insert = 1
③ async_insert_busy_timeout_ms = 1000
④ async_insert_max_data_size = 1_000_000
⑤ async_insert_max_query_number = 450
① Enables asynchronous inserts. With ② we set the default return behavior described above for asynchronous inserts. We configured that the buffer should be flushed either ③ once per second, or if ④ 1 MB of data, or ⑤ the data from 450 insert queries are collected. Whatever happens first triggers the next buffer flush. ②, ③, ④, ⑤ are the default values in ClickHouse (③ has 200 as default value in OSS and 1000 in ClickHouse Cloud).
The following three charts visualize the number of active parts, the number of all parts (active and inactive) in the cloud function’s target table, and the CPU utilization of the ClickHouse cluster during the first hour of both benchmark runs:
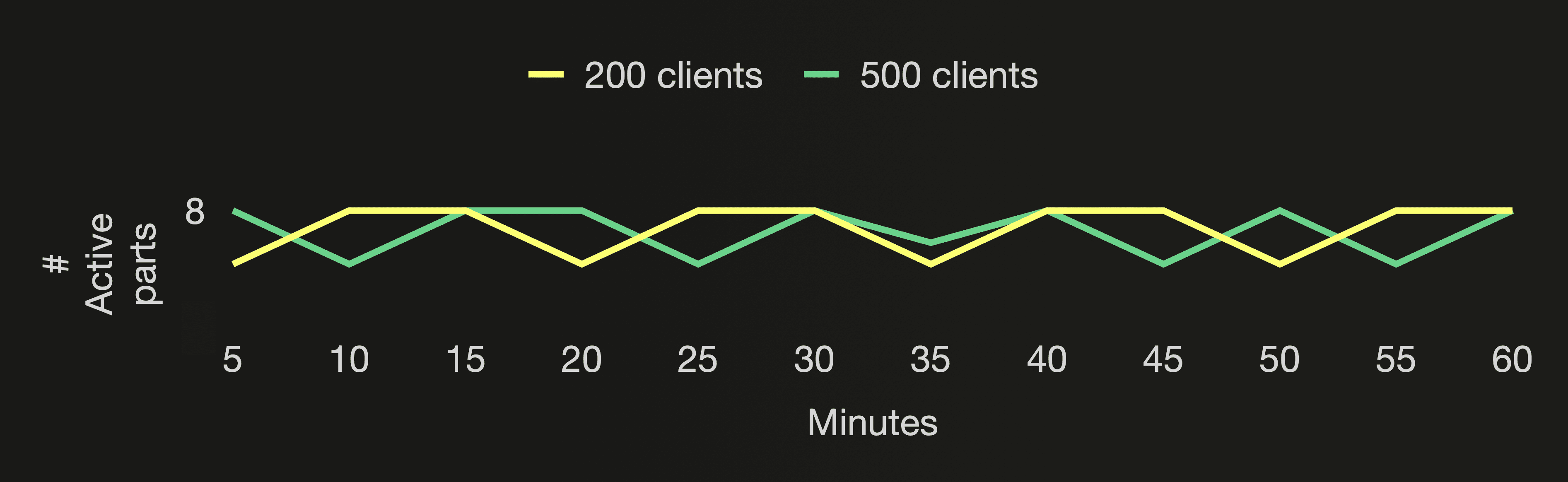
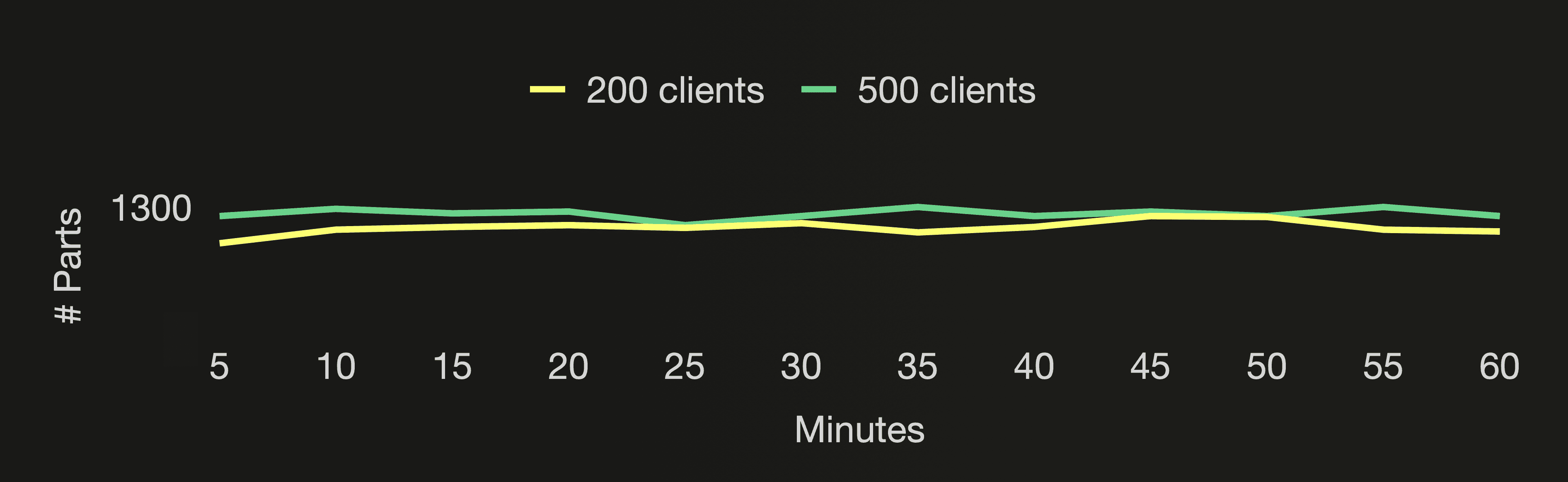
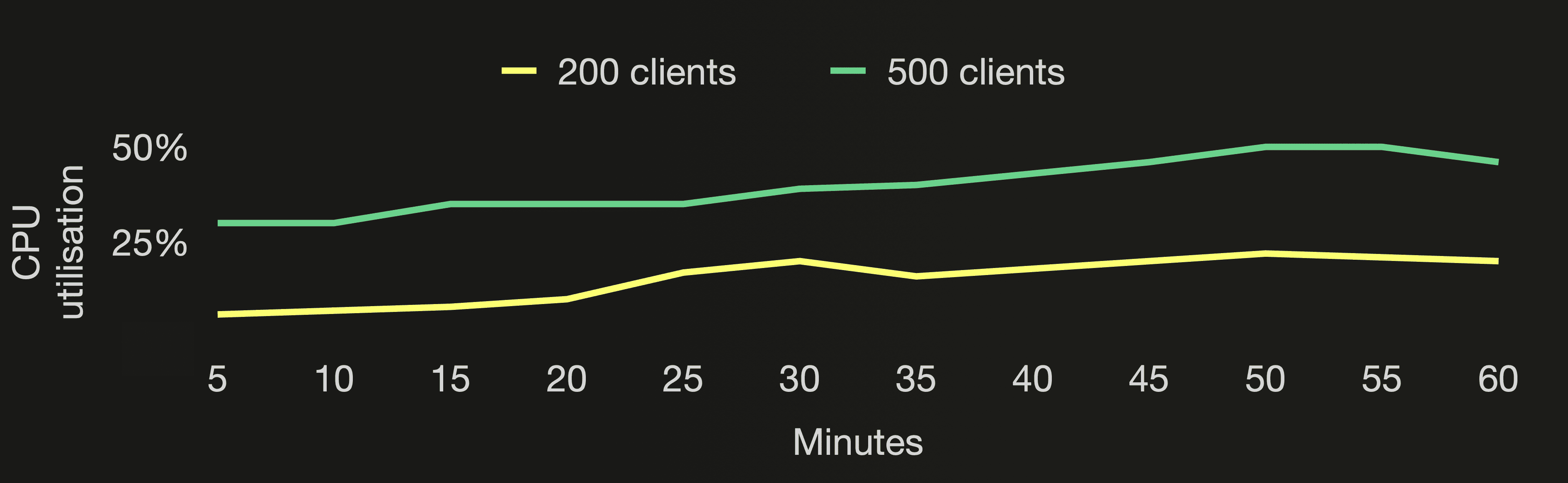 You can see that the number of active parts stays stable below 8 independently of how many cloud function instances we are running. And the number of all parts (active and inactive) stays stable below 1300 independently of how many cloud function instances we are running.
You can see that the number of active parts stays stable below 8 independently of how many cloud function instances we are running. And the number of all parts (active and inactive) stays stable below 1300 independently of how many cloud function instances we are running.
This is the advantage of using asynchronous inserts for the UpClick cloud functions. Regardless of how many cloud function instances we are running - 200 or 500, or even 1000 and more - ClickHouse will batch the data received from the cloud functions and create one new part per second. Because we set async_insert_busy_timeout_ms to 1000. We are driving our Formula One car 🏎 at top speed in a high enough gear, respectively. That minimizes I/O and CPU cycles used for the data ingestion. As you can see, the CPU utilization for both benchmark runs is much lower than the benchmark run for traditional synchronous inserts that we did earlier in this post. The CPU utilization for the benchmark run with 500 parallel clients is higher than for the benchmark run with 200 parallel clients. With 500 clients the buffer contains more data when flushed once per second. And ClickHouse needs to spend more CPU cycles sorting and compressing that data when a new part is created during the buffer flush and when the larger parts merge.
Note that async_insert_max_data_size or async_insert_max_query_number could trigger a buffer flush before one second has passed, especially with a high amount of cloud functions or clients, respectively. You could set these two settings to an artificially high value to ensure that only the time setting triggers buffer flushes for the sacrifice of potentially higher primary memory usage as more data needs to be buffered temporarily.
Fire-and-forget return behavior
Description
This diagram illustrates the optional fire-and-forget return behavior (wait_for_async_insert = 0) for asynchronous inserts:
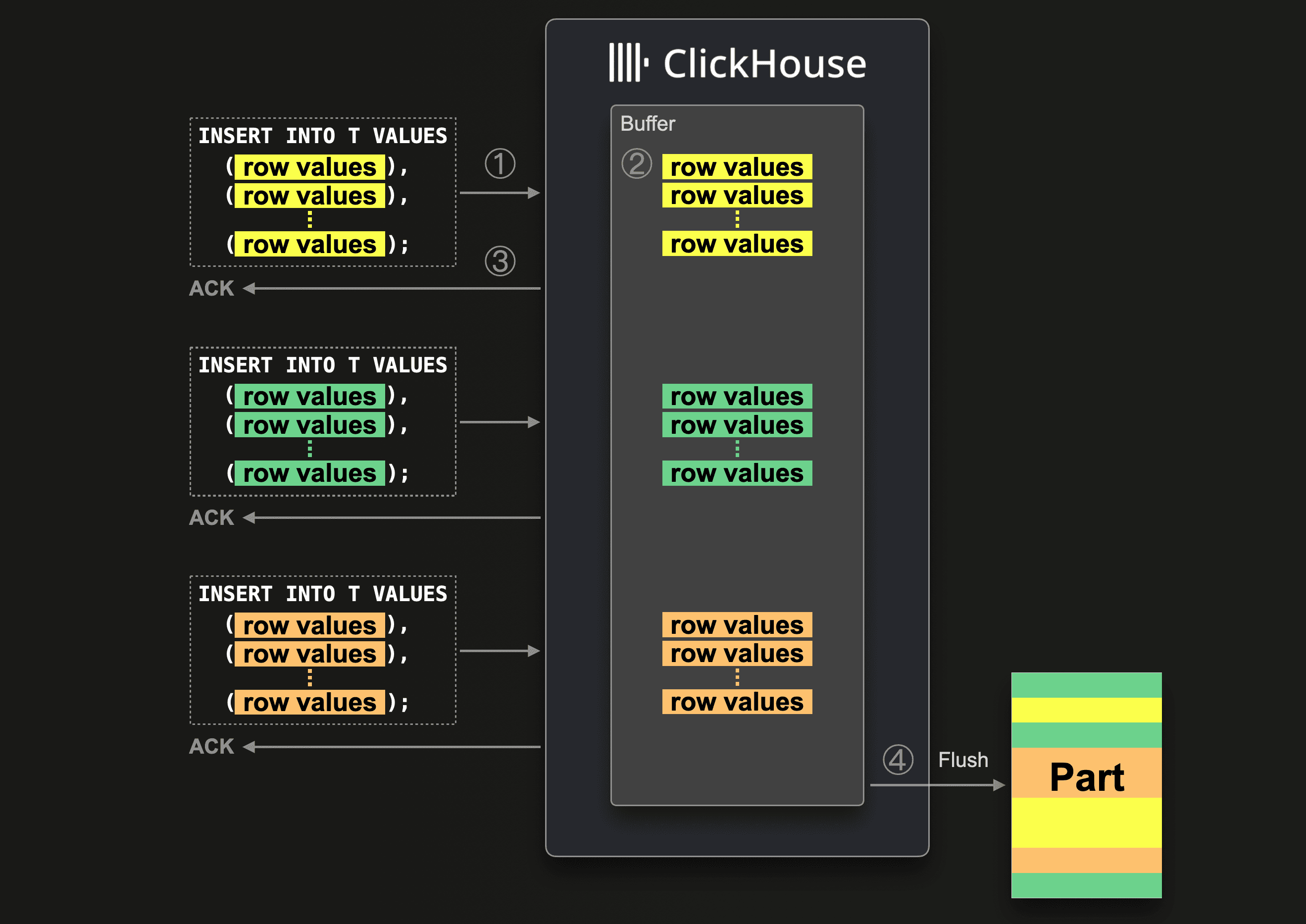 When ClickHouse ① receives an insert query, the query’s data is ② immediately written into an in-memory buffer first. After that, ③ the insert query returns to the sender with an acknowledgment of the insert. ④ When the next regular buffer flush takes place, the buffer’s data is sorted and written as one or more data parts to the database storage. Before the buffer gets flushed, the data from other insert queries can be collected in the buffer.
When ClickHouse ① receives an insert query, the query’s data is ② immediately written into an in-memory buffer first. After that, ③ the insert query returns to the sender with an acknowledgment of the insert. ④ When the next regular buffer flush takes place, the buffer’s data is sorted and written as one or more data parts to the database storage. Before the buffer gets flushed, the data from other insert queries can be collected in the buffer.
Advantage
An advantage of this mode is the very high ingest throughput (with minimal cluster resource utilization) that clients with a single-threaded insert loop can achieve:
1. Get the next batch of data
2. Send insert query with the data to ClickHouse
3. Immediately receive an acknowledgment that the insert got buffered
4. Go to 1
Disadvantages
However, this mode also comes with disadvantages:
-
No durability guarantee: Even when a client gets the acknowledgment for the insert query, that doesn’t necessarily mean that the query’s data is or will be written to database storage. An insert error can occur later during the buffer flush. And data loss can happen when a ClickHouse node crashes or is shut down before the next regular flush of the in-memory buffers occurs. And worse, it can be silent data loss, as it is tricky for clients to find out about such events, as the original inserts into the buffers got successfully acknowledged. For a graceful shutdown of a ClickHouse node, there is a SYSTEM command which flushes all asynchronous insert buffers. Additionally, a server-side setting determines whether to flush asynchronous insert buffers on graceful shutdown automatically.
-
Insert errors are not returned: When insert errors occur during buffer flush, the original insert into the buffer still got successfully acknowledged to the client. Clients can only discover these insert errors in hindsight by inspecting log files and system tables. In a second post, we will provide guidance for that.
-
Identifying failed data sets is complex: In the case of the aforementioned silent insert errors, identifying such failed data sets is tricky and complex. ClickHouse doesn’t currently log these failed data sets anywhere. A dead-letter queue for failed async inserts in
fire and forgetmode could help to identify the data sets that couldn’t be inserted in hindsight.
Generally, asynchronous inserts in fire-and-forget mode, as the name suggests, should only be used in scenarios where data loss is acceptable.
Benchmark
We run two benchmarks.
Benchmark 1:
• 500 UpClick cloud function instances
• Once every 10 seconds schedule/execution per cloud function
• 5 seconds buffer flush time
Benchmark 2:
• 500 UpClick cloud function instances
• Once every 10 seconds schedule/execution per cloud function
• 30 seconds buffer flush time
We use the following asynchronous insert settings for both benchmark runs:
① async_insert = 1
② wait_for_async_insert = 0
③ async_insert_busy_timeout_ms = 5000 (Benchmark 1)
async_insert_busy_timeout_ms = 30_000 (Benchmark 2)
④ async_insert_max_data_size = 100_000_000
⑤ async_insert_max_query_number = 450_000
① Enables asynchronous inserts. With ② we enable the fire and forget return behavior described above for asynchronous inserts. The buffer should be flushed ③ once every 5 seconds for benchmark 1 and once every 30 seconds for benchmark 2. Remember that the data is only searchable for queries after the buffer got flushed to a part on database storage. With ④ and ⑤ we set the other two buffer flush thresholds to an artificially high value to ensure that only the time setting ③ triggers buffer flushes.
The following three charts visualize the number of active parts, and the number of all parts (active and inactive) in the cloud function’s target table, and the CPU utilization of the ClickHouse cluster during the first hour of both benchmark runs:
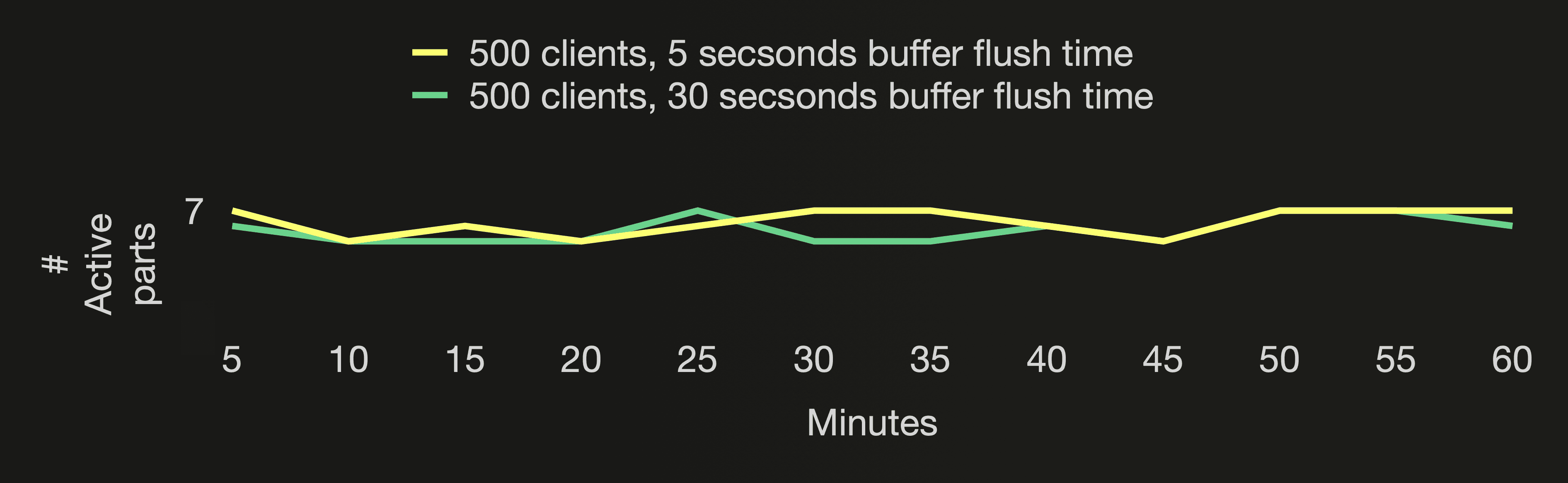
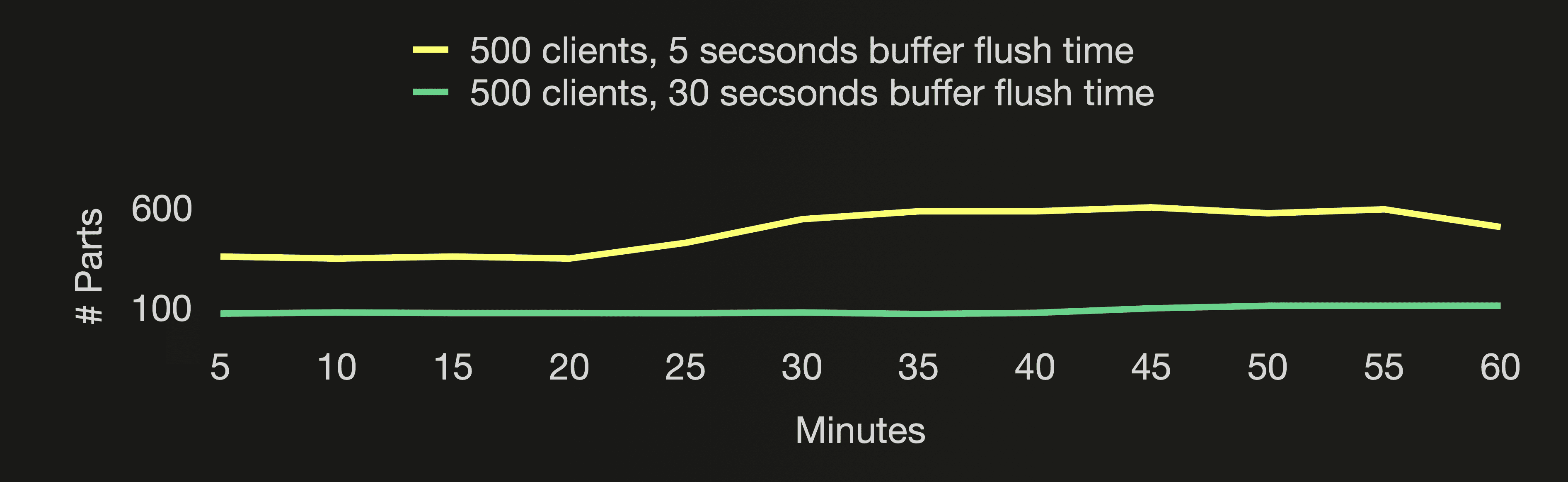
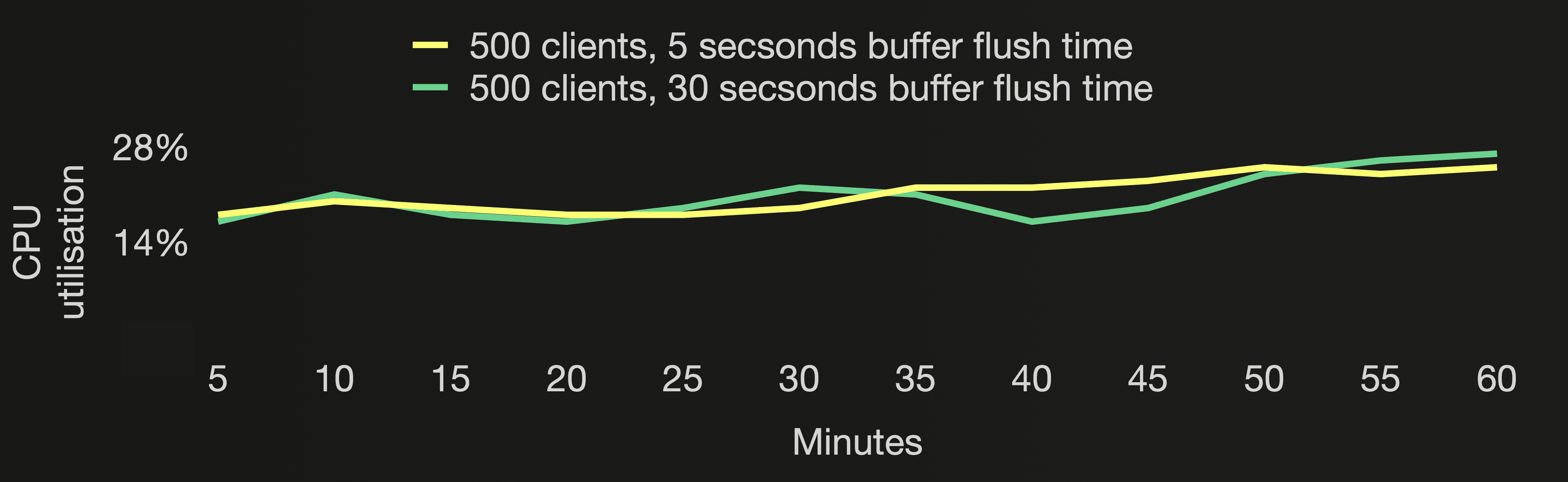 The number of active parts stays stable below 7 for both benchmark runs. All parts (active and inactive) are ~6 times lower when the buffer flush happens 6 times less frequently. With flushing the buffer only once every 5 or 30 seconds, the CPU utilisation is lower than flushing the buffer once per second as done in the benchmark runs for the default asynchronous insert return behavior we did earlier in this post. The CPU utilisation is very similar for both benchmark runs here, though. When the buffer gets flushed only once every 30 seconds, ClickHouse creates fewer but larger parts resulting in increased CPU demand for sorting and compressing the data.
The number of active parts stays stable below 7 for both benchmark runs. All parts (active and inactive) are ~6 times lower when the buffer flush happens 6 times less frequently. With flushing the buffer only once every 5 or 30 seconds, the CPU utilisation is lower than flushing the buffer once per second as done in the benchmark runs for the default asynchronous insert return behavior we did earlier in this post. The CPU utilisation is very similar for both benchmark runs here, though. When the buffer gets flushed only once every 30 seconds, ClickHouse creates fewer but larger parts resulting in increased CPU demand for sorting and compressing the data.
Summary
In this blog post, we have explored the mechanics of ClickHouse asynchronous data inserts. We discussed that traditional synchronous inserts require appropriate client-side data batching in high ingest throughput scenarios. In contrast, with asynchronous inserts the frequency of part creations is automatically kept under control by shifting data batching from the client side to the server side, which supports scenarios where client-side batching is not feasible. We used an example application for demonstrating, benchmarking, and tuning traditional synchronous and asynchronous inserts with different settings. We hope you learned new ways to speed up 🏎 your ClickHouse use cases.
In an upcoming post, we will guide monitoring and debugging the execution steps of asynchronous inserts.
Stay tuned!


