While main memory is considered to be rather cheap by some systems designers it is not always possible to store everything in the main memory. When data is stored in external memory one has to think carefully how to access the data. There are several kind of storage devices and more than one system call to read from them. We performed experiments to find out how different Linux system calls perform for available devices. In total HDD, SATA SSD, NVMe SSD, and Intel Optane were accessed via single-threaded and multi-threaded pread, Linux aio, and new io_uring interfaces. Full report is available in PDF format: link. We give one section from the report as an example.
Single Random Read
External memory devices are block devices which means data transfer between a device and a host is done in blocks rather than single bytes. Typically 512 bytes or 4 kilobytes blocks are used. These block sizes have been chosen by manufactures long time ago and may be not the best choice for modern devices. By requesing larger amount of contigious data we can emulate larger block size. Let's find out how modern devices perform with larger blocks.
Our goal is to pick the best block size for a random read. An application (or filesystem) can pick any block size and access data with respect to this block size. We vary block size from 4 kilobytes up to 32 megabytes. For each block size we make some random reads. Among these reads we calculate average, minimum and maximum latency as well as 99,0 and 99,9 percentiles. We use system call pread(2) in this experiment. We believe that lseek(2) followed by read(2) should have the same performance since the observed storage access time is far longer than a system call.
Hard Disk Drive
This figure shows results for HDD.
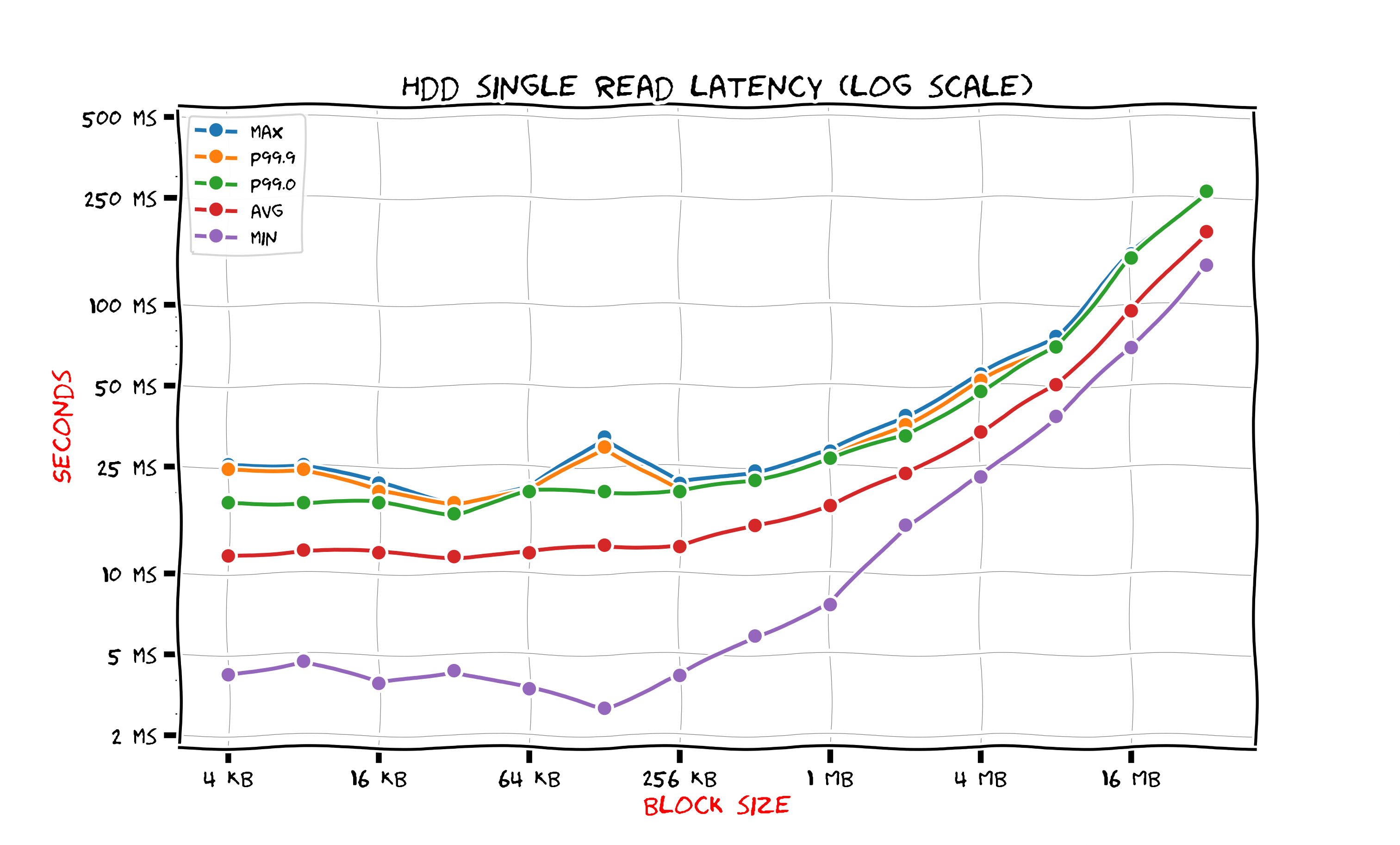
The latency is almost the same for all block sizes smaller than 256 kilobytes. This happens because seek time is much larger than the data transfer time. The seek time includes arm positioning to find the right track and awaiting for platter rotation to bring data under the head. A simple consequence is that for a HDD random read one should use blocks of size at least 256 kilobytes. Even if an application use smaller blocks the drive access time would be the same. However one could still decide to use smaller blocks for better cache utilization: if the amount of data per request is small and is expected to fit in cache then storing a large block along with the requested data would actually make cache capacity smaller in terms of useful data.
The 256 kilobyte block read takes 12 milliseconds on the average. We experienced variations from 4 milliseconds up to 25 milliseconds. This is really a huge amount of time for a computer. For example the typical process scheduling quantum is just a few milliseconds. An operating system can (and in fact does) execute other processes while our process waits for the data to arrive from the hard drive.
SATA SSD
The figure below shows SATA SSD read latencies.
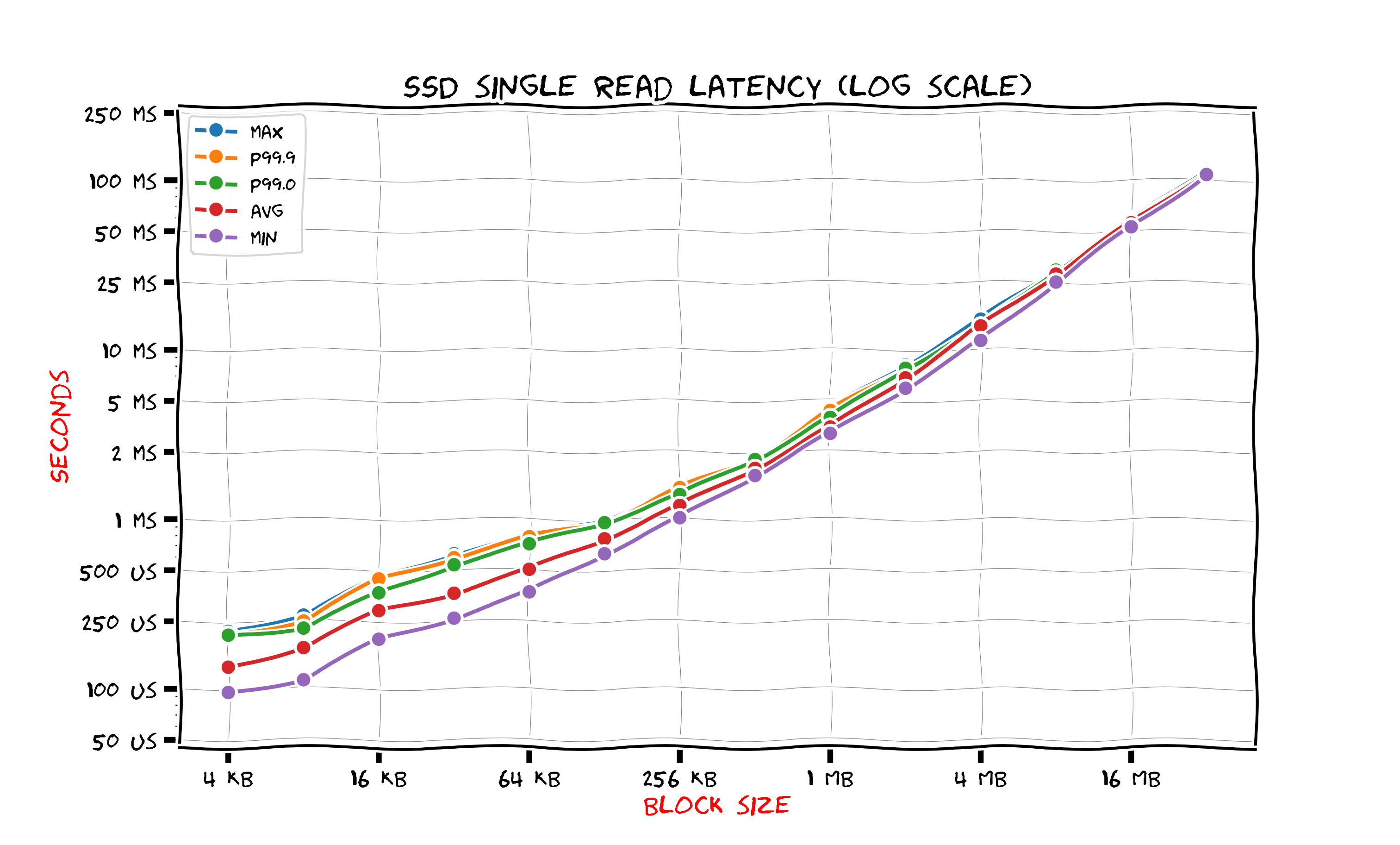
Note that the time at the lower part of the figure is in microseconds (we use standard shortenings ms for milliseconds and us for microseconds). Reading block of size 4 kilobytes takes 140 microseconds on the average and the time growth is linear when the block size increase. Compared to HDD reading a 4 kilobyte block from SSD is 80 times faster. For a 256 kilobyte block SSD is ten times faster than HDD. When block size is large enough (starting from 4 megabytes) SSD is only two times faster than HDD.
NVMe SSD
The next figure shows results for NVMe SSD.
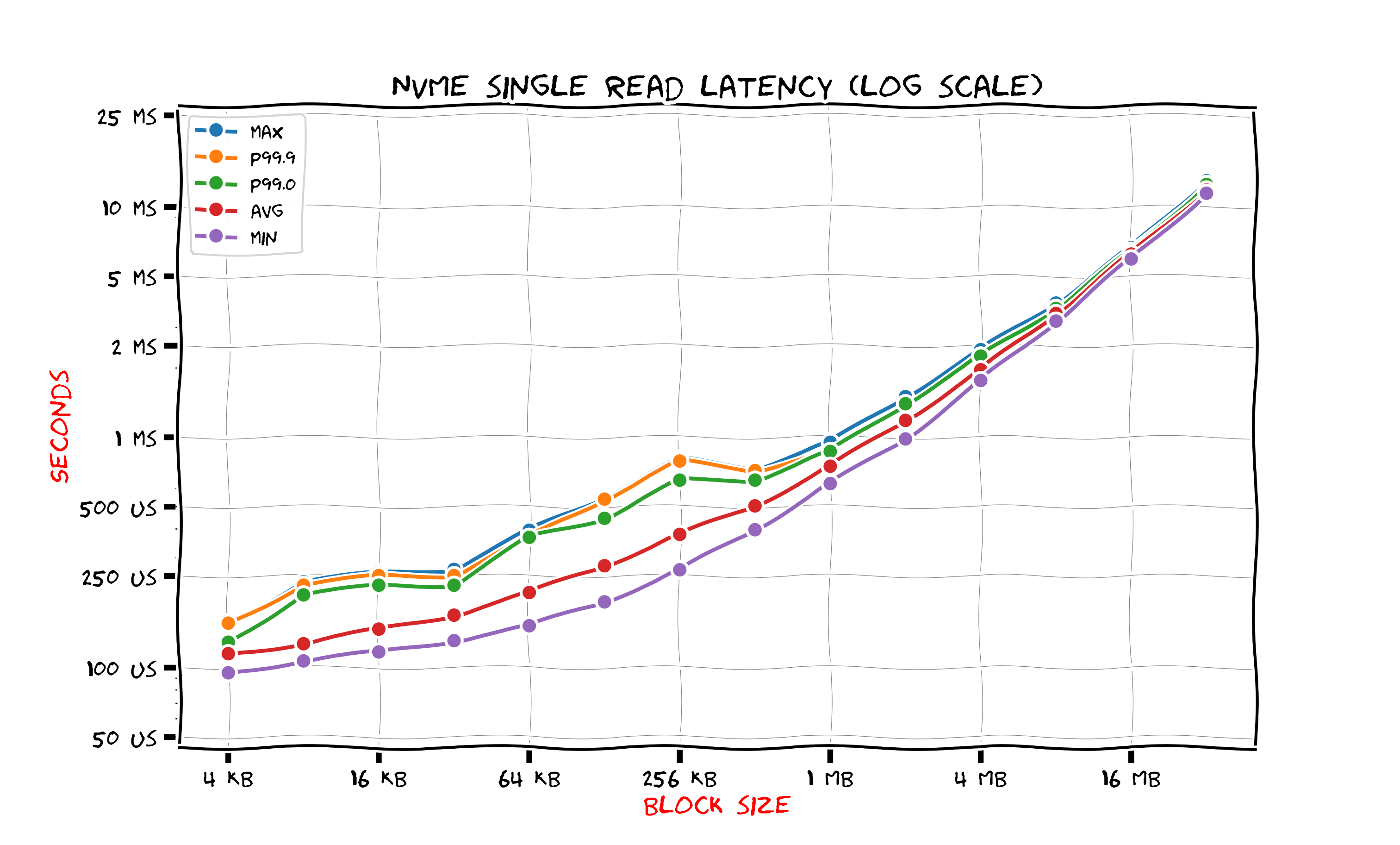
The latency is better than those for SATA SSD. For a 4 kilobytes block size the average time improved only a little, but the 99 percentile is two times lower. It takes less than millisecond to read a megabyte block from NVMe SSD. For SATA SSD it took 3 milliseconds. As we see, upgrade from SATA SSD to NVMe SSD is not as dramatic as upgrade from HDD to SATA SSD. This is not surprising since both SATA and NVMe SSD are based on the same thechnology. Only interfaces differ.
Intel Optane
This figure shows results for Intel Optane SSD.
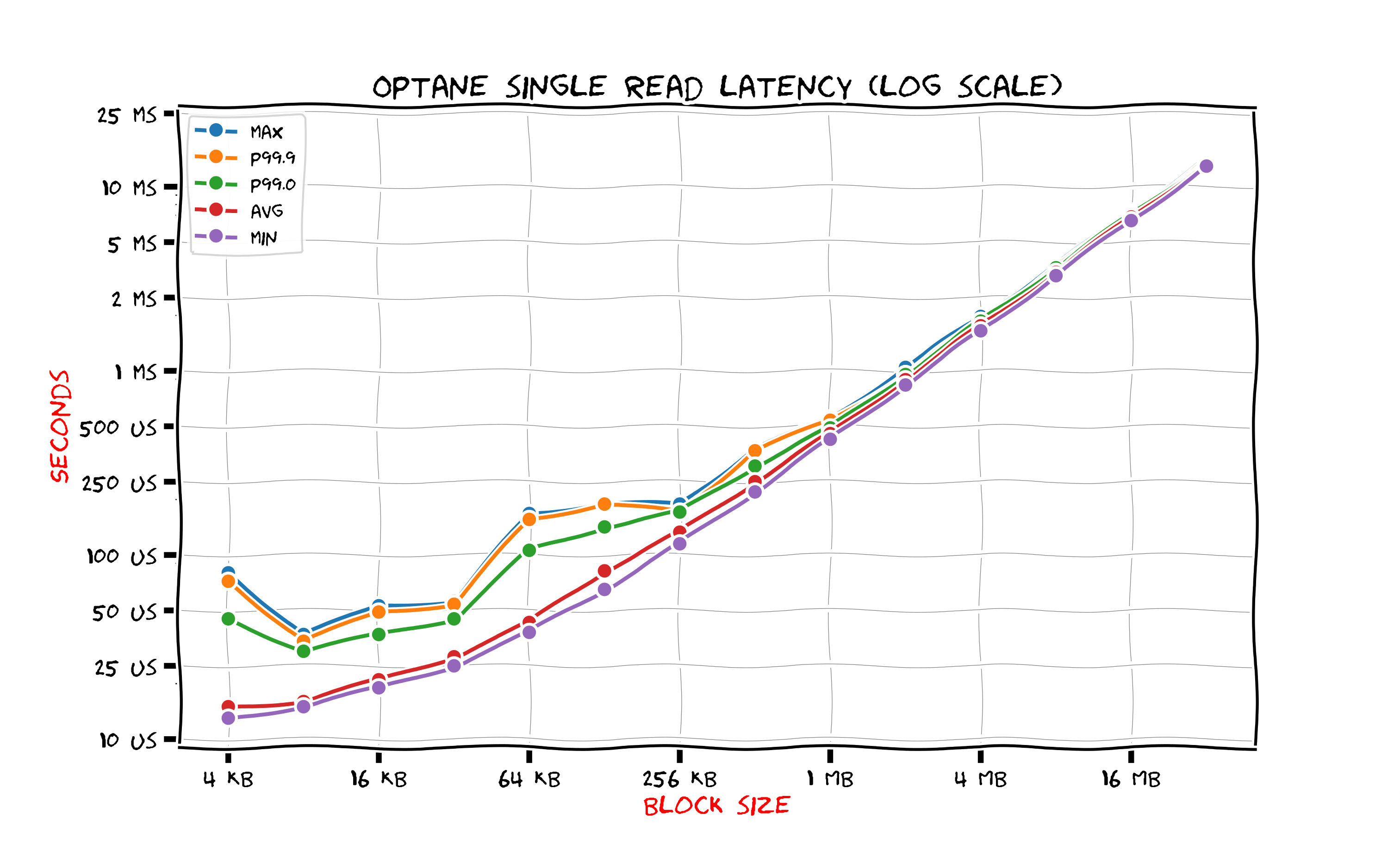
Minimal latency is 12 microseconds whih is 10 times lower than those of NVMe SSD. Average latency is 1000 lower than those of HDD. There is quite large variation for small block read latency: even though the average time is quite low and close to minimal latency the maximum latency and even 99 percentile are significantly worse. If somebody looks at these results and wishes to create an Intel Optane-based service with 12 microsecond latency for reads they would have to install larger number of Intel Optane drives or consider providing more realistic timings.
When latency is so small overheads of context switching and interrupt handling become noticeable. One can use polling mode to gain some improvement. In this mode the Linux kernel monitors the completion queue instead of switching to some other job and relying on hardware interrupt with interrupt handler to notify about completion. Clearly, it is considerable to use the polling mode only when hardware response is expected to arrive fast enough.
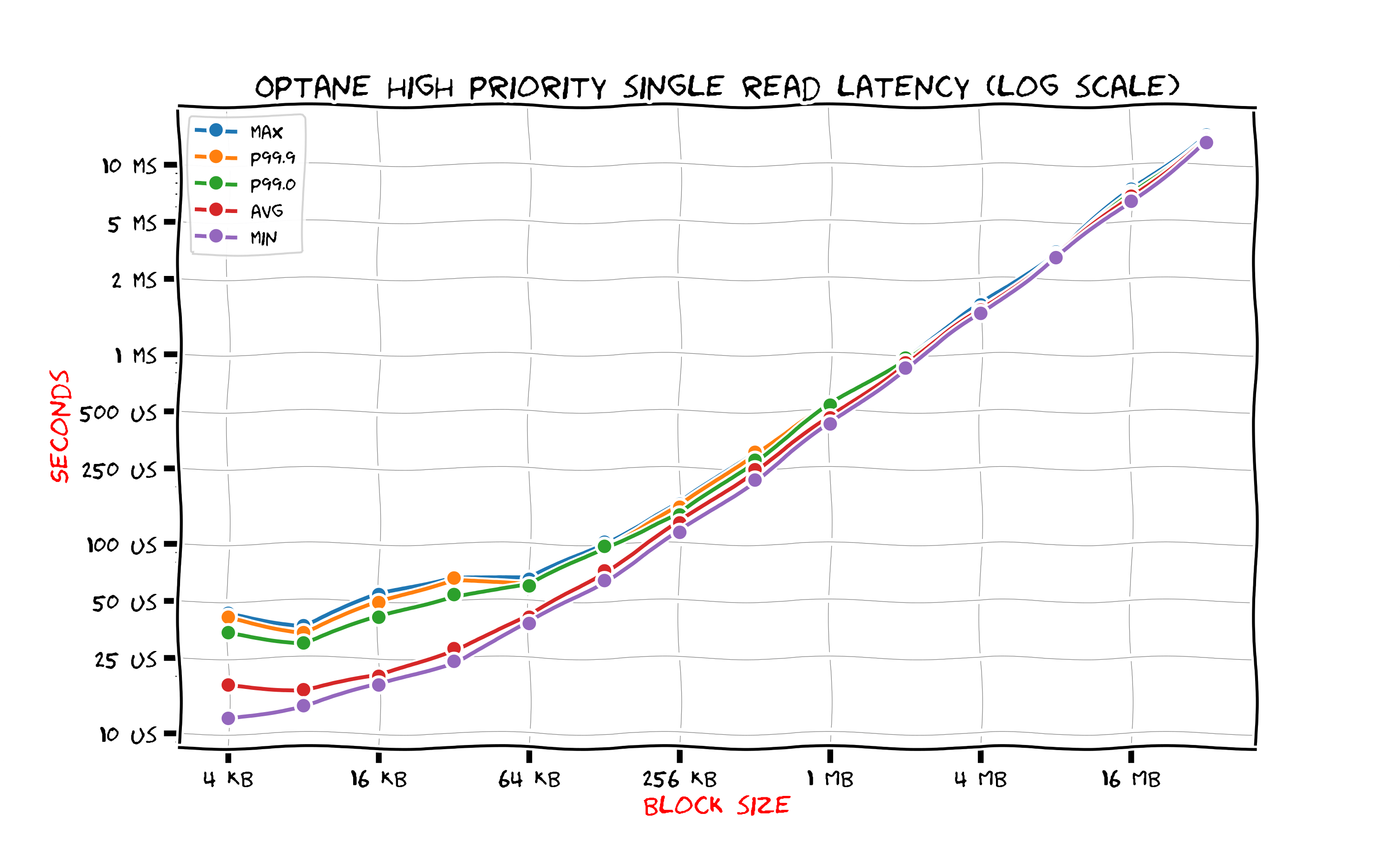
The figure above shows results for reading from Intel Optane in polling mode. The polling mode is used when an application calls preadv2(2) system call with RWF_HIGHPRI flag. Compared to usual pread(2) the polling mode lowers the maximum latency by a factor of two for block sizes up to 256 kilobytes.
Summary
To summarize our results the next figure shows single read latencies for all four storage types on a single chart.
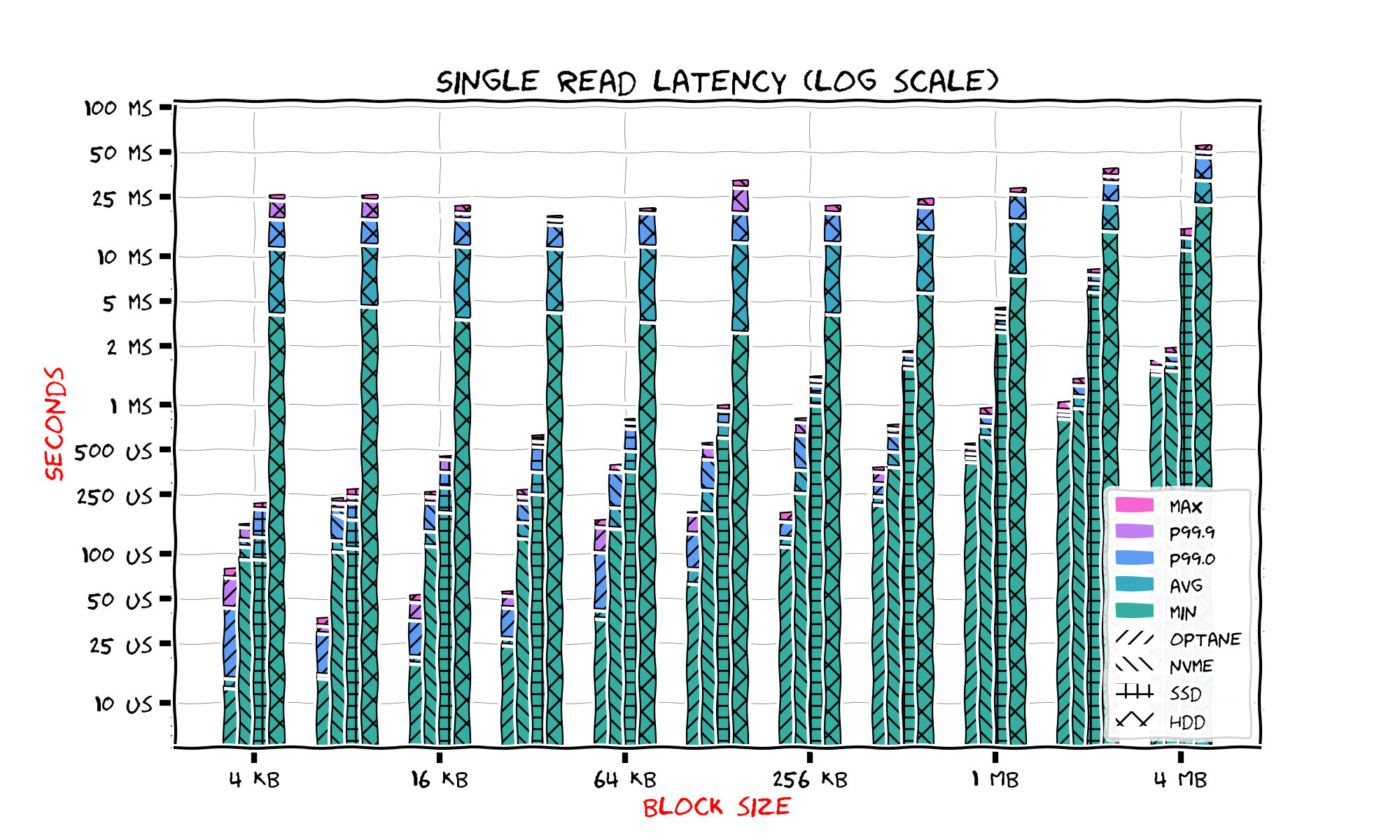
Starting from 4 megabytes the latency is easily predicted by linear extrapolation so we don't show larger blocks here. To show everything on a single figure we are forced to use quite an overloaded legend. We use vertical level to show the latency and we iterate the block size horizontally. For each block size we show four bars, from left to right: for Intel Optane, NVMe SSD, SATA SSD, and HDD. Storage type is represented by hatch and the latency by color.
We see that solid state device latencies are far better than HDD. For a single read the leader is Intel Optane, however as we shall see later it has it's own drawback compared to NVMe SSD. NVMe SSD and SATA SSD look quite close to each other when the block size is small. Our observations show that the best block size for random read is 256 kilobytes for HDD, 4 kilobytes for NVMe and SATA SSD and 8 kilobytes for Intel Optane.
So, how about testing modern IO interfaces in Linux? Continue reading the full article.
2021-03-09 Ruslan Savchenko